Business Intelligence
What happens to your data team when everyone can write SQL
Enabling SQL for everyone speeds decisions and shifts data teams to strategic work, but requires governance for metrics, cost, and security.
When everyone in a company can write SQL, the way data teams operate changes dramatically. Instead of being bogged down with requests, they focus on building systems that empower others to find answers on their own. Here's the core takeaway:
Faster decisions: Employees no longer wait days for reports - they can query data directly, speeding up decision-making by 2-5x.
Shift in roles: Data analysts and engineers move from handling routine tasks to solving complex problems and improving infrastructure.
Fewer bottlenecks: Self-service tools like Querio enable non-technical users to query data safely, reducing dependency on data teams.
Governance challenges: Broad SQL access requires safeguards like role-based controls, semantic layers, and query validation to avoid risks like inconsistent metrics or data exposure.
The shift to self-service SQL access benefits organizations by making data more accessible, but it demands a balance between flexibility and governance to ensure accuracy, security, and cost control.
Extreme Self-Service: Turning Data Consumers into Data Constructors | Whatnot

The Problems with Keeping SQL in One Team's Hands
When SQL access is limited to a select few, it can cause significant delays and create security vulnerabilities. This bottleneck not only slows down the delivery of insights but also undermines the overall reliability and safety of data across the organization.
Long Queues and Slow Reports
In centralized systems, 90% of employees often wait between two hours and four days to get answers from data requests - or they have to rely on outdated dashboards [3]. Before implementing self-service capabilities, analysts at Parcel Perform spent 25% of their working hours - roughly 260 hours each month - just handling routine data extraction requests [10]. This burden overwhelms data teams, leaving little room for strategic priorities like enhancing data architecture or building dependable pipelines.
"The traditional analytical model has become a bottleneck. Today, every business decision requires a report, every report requires a complex SQL query, and every query ends up at the back of a long queue." - Marcin Kolenda, Co-Founder, Alterdata [9]
Conflicting Numbers and Broken Trust
Delays often push employees to find shortcuts. They extract data into spreadsheets or create their own local reports, resulting in different versions of the same metrics. This "shadow system" leads to ungoverned data assets with no version control or audit trail [7].
The impact becomes clear in meetings. Instead of focusing on strategy, teams argue over which numbers are accurate. As Mat Hughes, Product Architecture Lead at InterWorks, explains:
"The meeting that should have focused on solving the conversion rate problem instead becomes an archaeological expedition. Which numbers are right? Why are they different? Whose dashboard should we believe?" [5]
This pattern erodes trust in data across the organization. By 2024, 57% of data professionals identified data quality as their biggest challenge, compared to 41% in 2022 [4].
Data Security and Compliance Gaps
Restricting SQL access can also backfire on security. When official channels are too slow, employees often bypass them by exporting sensitive data to local files, sharing spreadsheets via email, or creating unauthorized pipelines. These actions introduce compliance risks, particularly in regulated sectors like healthcare or finance, where managing PII is critical.
Such workarounds result in unmonitored data assets that organizations can neither classify nor protect. This "Silo Trap" is more than an efficiency issue - it’s a governance failure [11]. Solutions like role-based access controls, query gateways with row limits, and read-only permissions for non-technical users are far better safeguards than simply locking down access [3].
These issues underline the pressing need for a self-service model that balances user empowerment with strong governance. Addressing these challenges is the first step toward rethinking roles and processes for a more effective system.
What Changes When Everyone Can Write SQL
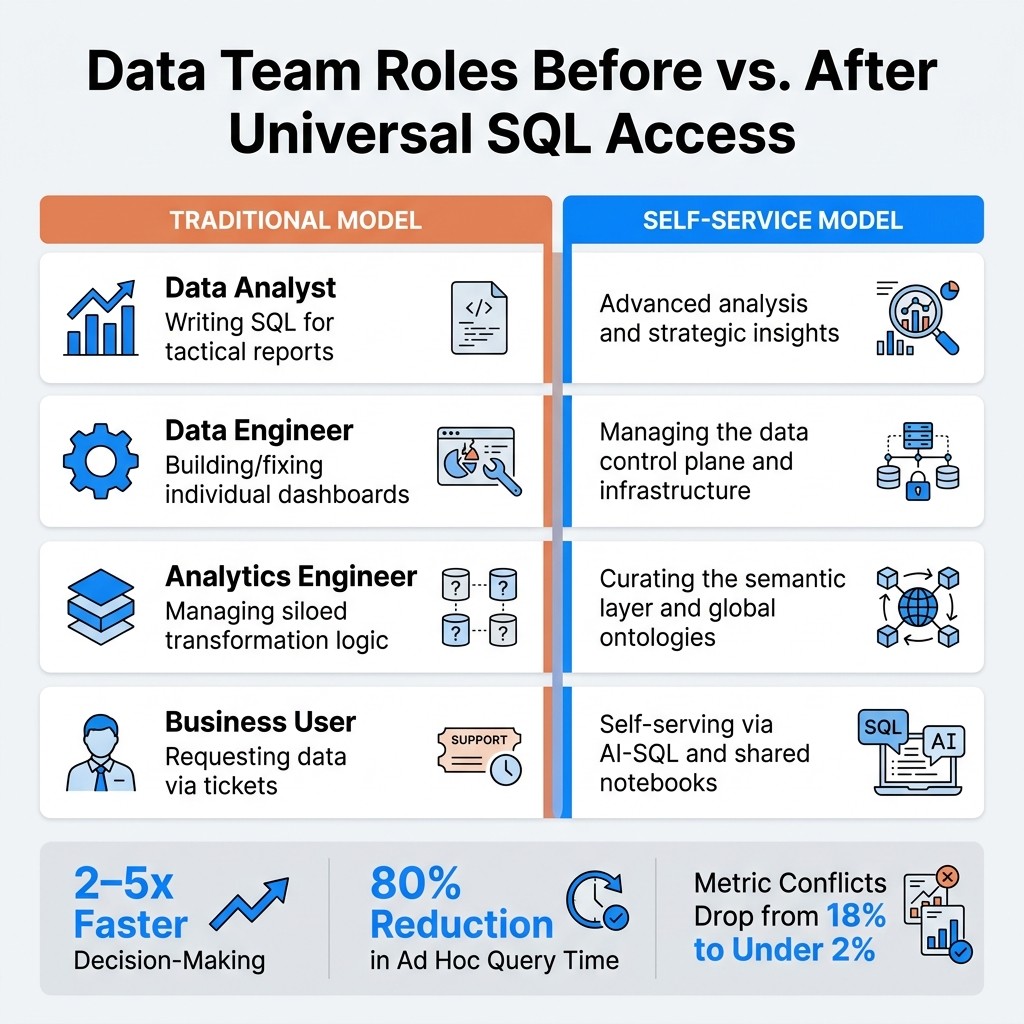
Data Team Roles Before vs. After Universal SQL Access
How Data Team Roles Shift
When writing SQL becomes a universal skill, the dynamics within data teams take a dramatic turn. Instead of acting as a "help desk" for routine report requests, analysts can redirect their efforts toward solving intricate business challenges. This might involve refining product strategies or conducting causal inference studies - tasks that require their unique blend of skills.
Chris Kukstis, Product Analytics Leader at SeatGeek, captures this shift perfectly:
"Instead of dedicating countless hours to writing code that delivers a specific, often tactical, report to a stakeholder, the time of data analysts and scientists can be better spent tackling complex business problems that truly leverage their unique blend of statistical acumen, business understanding, product intuition, and data expertise." [8]
Data engineers also experience a shift in focus. Their role evolves from fixing dashboards and handling one-off requests to creating robust infrastructure. This infrastructure acts as a "data control plane", enabling analysts to work independently without jeopardizing production systems. As data engineer Zach Brown explains:
"My focus now isn't enabling analysts directly. It's about building the infrastructure so they don't need me in the loop for every change." [13]
Here’s a quick look at how responsibilities across the data team change:
Role | Traditional Responsibility | New Responsibility |
|---|---|---|
Data Analyst | Writing SQL for tactical reports | Advanced analysis and strategic insights |
Data Engineer | Building/fixing individual dashboards | Managing the data control plane and infrastructure |
Analytics Engineer | Managing siloed transformation logic | Curating the semantic layer and global ontologies |
Business User | Requesting data via tickets | self-serving via AI tools that write SQL and shared notebooks |
This realignment not only enhances individual roles but also fosters better collaboration and efficiency across the organization.
Better Collaboration Between Technical and Non-Technical Teams
These internal changes also improve communication between technical and non-technical teams. Instead of relying on Slack threads or emailed spreadsheets filled with SQL snippets, teams collaborate using shared, traceable logic frameworks. Paige Berry, Lead Data Analyst at dbt Labs, highlights the difference this makes:
"Before dbt Insights, I'd drop SQL snippets in Slack. Now I can send a single Insights link with everything in one place that's clean, traceable, and ready to ship." [13]
This shift is crucial because one of the biggest barriers between technical and non-technical teams is the lack of a common language. Disagreements over metrics - like how to define "revenue" or "monthly active users" - can cause friction. With core definitions documented and centrally maintained, everyone works from a single source of truth. This eliminates the need for a "translator" in every meeting, making discussions more productive.
Faster Decisions and More Experimentation
When analysts and engineers are no longer bogged down by repetitive tasks, decision-making speeds up dramatically. The time it takes to go from query to answer shrinks from days to mere minutes [12]. This enables teams to embrace a culture of rapid experimentation and data-driven decisions. For example:
Marketing teams can check campaign performance without filing tickets.
Operations teams can analyze patterns on their own schedules.
Product managers can dive into data themselves, addressing specific questions beyond the scope of pre-built dashboards.
This self-service model, supported by well-governed access, ensures that the acceleration is sustainable. One investment management firm reported an 80% reduction in time spent on ad hoc questions after adopting text-to-SQL tools compared to traditional dashboards [6]. Beyond saving time, this approach encourages teams to ask more questions, test more ideas, and ground decisions firmly in data.
How to Handle the Risks of Broad SQL Access
Expanding SQL access across an organization brings benefits but also introduces risks like higher costs, inconsistent metrics, and potential data exposure. To address these, it's crucial to have a clear and structured approach.
Controlling Query Volume and Warehouse Costs
When more users gain the ability to write SQL, the number of queries hitting your data warehouse can skyrocket. Research shows that around 30% of cloud data warehouse spending is wasted on inefficient queries [14]. For instance, a poorly optimized query that scans an entire table instead of focusing on a specific partition could cost hundreds of dollars [14].
To mitigate this, you can combine governed query generation with reusable logic. Tools like Querio connect directly to your data warehouse using read-only credentials, avoiding the need for duplicating data or setting up complex ETL workflows. Querio's AI agents ensure that SQL queries adhere to approved practices by filtering data early, selecting specific columns instead of using SELECT *, and always including a LIMIT clause to reduce unnecessary scans [10][14]. Additionally, data teams can create reusable query blocks in Querio’s version-controlled notebooks, allowing non-technical users to leverage pre-built queries rather than writing their own from scratch.
Once costs are under control, the next challenge is maintaining consistent metrics.
Keeping Metrics Consistent Across the Organization
Broad SQL access can lead to "metric drift", where different teams or individuals define metrics in conflicting ways. A shared semantic layer can solve this by standardizing metric definitions, joins, and business terms across the organization. This ensures that everyone relies on the same logic when analyzing data.
When AI tools generate SQL based on natural language inputs, they can draw from this shared semantic layer. This approach keeps analyses aligned and prevents discrepancies, ensuring insights remain reliable and consistent.
However, broad access also requires strong safeguards to protect sensitive data.
Protecting Data and Staying Compliant
In addition to managing costs and consistency, safeguarding data and maintaining compliance are critical when enabling self-service SQL access. Role-based access controls (RBAC) allow data teams to define which tables and columns specific users or groups can query. Sensitive information - like email addresses or payment data - can be automatically masked, enabling analysis without exposing raw personal details [2].
Querio supports these needs with enterprise-grade security features, including SOC 2 Type II compliance and standard SSO integrations. Every query is fully auditable, allowing data teams to monitor usage, detect anomalies, and ensure compliance without manual intervention. With the global data governance market expected to grow from $5.38 billion in 2026 to $24.07 billion by 2034 [2], establishing robust data governance practices early on makes scaling access far simpler than trying to retrofit controls later.
Building a Self-Service Model That Keeps Governance in Place
Balancing cost control and data protection is essential, but the real challenge lies in creating a self-service model that users trust and adopt widely. This evolution builds on democratized SQL access, ensuring users are empowered without sacrificing governance.
A strong self-service model strikes the right balance between efficiency and control, addressing governance challenges while enabling broader access.
What Data Teams Are Responsible for Now
With more users gaining SQL access, data teams now focus on enabling safe, self-service analysis rather than handling every ad-hoc request. Their responsibilities include managing the semantic layer to ensure all queries follow a single, approved logic. They also need to set up tiered access levels - for instance, providing marketing analysts with guided dashboards while offering data scientists controlled access to raw development schemas.
"High-performing teams shift their focus from 'how many questions can we answer' to 'how many people can we enable to answer their own questions, safely.'" - Kathryn Chubb, dbt Labs [18]
This shift reduces reactive tasks, freeing analysts to work on strategic projects instead of constantly responding to requests.
Practices That Keep Self-Service Scalable and Safe
To avoid issues like query sprawl and metric drift, certain structural practices are essential. These habits can mean the difference between a self-service model that succeeds and one that fails silently.
Version control your business logic. Adopting software engineering practices like Git, testing, and CI/CD for data models ensures changes are reviewed before reaching users. This approach, often called the Analytics Development Lifecycle (ADLC), prevents silent metric drift that undermines trust over time [15][13].
Classify requests by complexity. Use a triage system to manage requests: Tier 1 relies on dashboards, Tier 2 uses reusable query blocks, and Tier 3 involves full projects [18]. This structure keeps the workflow organized and efficient.
Automate quality checks. Validation tests in data pipelines catch errors before they affect dashboards [16]. Automating these quality gates ensures the data team isn’t constantly firefighting bad numbers.
Shopify provides an example of this approach in action. The company maintains approximately 300 core metrics across teams like product, finance, and marketing. Users can freely combine these metrics, but access to raw tables is restricted. This eliminates metric sprawl while still allowing meaningful exploration [16].
How to Know the Model Is Working
When best practices are in place, certain indicators show the model's success. Ad-hoc requests to the data team decline significantly - from over 20 per week to about 3–5 [18]. Metric conflicts also drop sharply; organizations using a semantic layer report a reduction in conflicts from 18% of queries to under 2% [16]. Additionally, warehouse costs stabilize instead of growing alongside user numbers.
Another key sign is the absence of shadow analytics [15][16]. When users trust the self-service layer, they rely on it, eliminating the need for unofficial workflows. This is the ultimate proof that governance is enabling productivity rather than hindering it.
"Traditional governance doesn't fail because it's too strict. It fails because it treats control and speed like they're opposites." - Karen Robito, P3 Adaptive [17]
Tools like Querio's shared context layer and version-controlled notebooks help data teams implement this model effectively. By defining business logic once and applying it consistently across dashboards, ad-hoc queries, and even AI-generated answers, governance becomes a seamless part of the data workflow instead of a barrier to it.
Conclusion: How Querio Helps Data Teams Adapt to Universal SQL Access
Universal SQL access can reshape how data teams operate, empowering them to take on a more strategic role - provided there's strong governance in place. Without proper oversight, expanded access could lead to conflicting metrics, skyrocketing warehouse costs, and governance issues that undermine trust in data. Striking the right balance between speed and control is where Querio steps in.
Querio introduces a shared context layer that allows data teams to define metrics like net_revenue, churn_rate, or 30-day active users just once. These definitions are then applied consistently across queries, dashboards, and even AI-generated insights throughout the organization. This approach gives business users the freedom to explore data independently, while ensuring critical calculations remain centralized and consistent, avoiding the chaos of reinventing metrics in spreadsheets. As Querio puts it, "The best self-service environments do not remove the data team. They change its job from answering every question to building a system where good questions can be answered safely, enabling many users to obtain reliable answers safely." [1]
On the governance front, Querio’s access controls are designed to maintain data security while enabling broader SQL use. Features like role-based access controls, read-only warehouse connections, and detailed audit logs protect sensitive information, limit access based on roles, and provide a comprehensive record of every query - making compliance audits far more manageable. Additionally, integrated query validation and monitoring help data teams identify inefficient queries early, preventing unnecessary jumps in monthly warehouse costs.
FAQs
What should my data team work on once most ad hoc SQL requests disappear?
With fewer random SQL requests coming their way, your data team can dedicate more time to critical priorities like enhancing data quality, ensuring proper governance, and creating scalable data infrastructure. They can also work on advanced analytics, predictive modeling, and building self-service platforms that enable teams to uncover insights on their own. This change transforms analysts into strategic collaborators, helping streamline operations and fueling data-driven growth throughout the organization.
How do we prevent different teams from calculating the same metric differently?
To maintain consistent metric calculations, it's crucial to define clear, standardized guidelines and implement centralized governance. Relying on a single source of truth and shared semantic layers ensures everyone accesses the same trusted data. Providing structured documentation and training helps align teams and minimizes inconsistencies. Tools like Querio play a key role by offering real-time data access and promoting uniformity in metrics. By blending technology with strong governance policies, teams can achieve accuracy and build trust in their data.
What guardrails keep self-service SQL secure and cost-effective?
Self-service SQL stays both secure and budget-friendly when supported by well-defined frameworks and organized processes. Key practices include implementing role-based access controls, maintaining centralized metrics, building precise semantic layers, and establishing clear validation protocols. Providing thorough training and detailed documentation reduces the risk of errors, such as mismatched dashboards. Consistent monitoring and auditing help uphold compliance, avoid expensive mistakes, and preserve data accuracy. This creates a balanced system where data access is widely available without sacrificing reliability or efficiency.
Related Blog Posts


