Business Intelligence
Database vs Data Warehouse vs Data Lake: What's the difference?
Compare databases, data warehouses, and data lakes: purposes, schemas, processing, users, scalability, costs, and when to use each.
When it comes to managing data, choosing the right storage solution depends on how you plan to use it. Here’s a quick breakdown:
Databases: Best for real-time transactions like processing payments or updating inventory. They’re fast, structured, and designed for daily operations.
Data Warehouses: Ideal for analyzing historical data and generating reports. They store structured data and help with business intelligence and decision-making.
Data Lakes: Great for storing massive amounts of raw, unprocessed data, including unstructured formats like videos or logs. Perfect for machine learning and exploratory analysis.
Quick Comparison
Feature | Database | Data Warehouse | Data Lake |
|---|---|---|---|
Purpose | Real-time transactions | Analytics & reporting | Storing raw data |
Data Structure | Highly structured | Structured/semi-structured | Structured & unstructured |
Schema | Schema-on-write | Schema-on-write | Schema-on-read |
Processing | Real-time | Batch | Batch & stream |
Users | Developers | Business analysts | Data scientists |
Scalability | Limited | High | Massive |
Cost | Varies | High | Low |
Each option serves a specific purpose, and many businesses combine all three to meet diverse needs. For example, a database handles live operations, a data warehouse powers analytics, and a data lake supports big data projects.
Database vs Data Warehouse vs Data Lake Comparison Chart
Data Lake vs Warehouse vs Database Explained Simply!
Understanding modern data warehouse architectures is essential for building a scalable data stack.
Databases: Built for Real-Time Operations
Databases are the backbone of Online Transaction Processing (OLTP), enabling the quick, reliable operations that power everyday applications. Whether you're logging into an e-commerce site, updating your shopping cart, or completing a purchase, a database is working behind the scenes to handle each action. These systems excel at managing thousands of small, rapid tasks every minute, ensuring that applications respond instantly to user inputs [4].
How Databases Work
The speed and reliability of databases come from their adherence to ACID properties: Atomicity, Consistency, Isolation, and Durability. These principles ensure that transactions are completed without errors or corruption, even when multiple users are accessing the system simultaneously [4]. For instance, when transferring money between bank accounts, ACID compliance guarantees that the transaction either fully succeeds or fails entirely, avoiding issues like missing funds.
Databases achieve sub-second response times by using row-oriented storage and indexes, which allow them to locate data quickly [4]. This structure makes them ideal for tasks like updating a single user profile or processing an order. Additionally, databases enforce a schema-on-write approach, meaning data must adhere to a predefined structure before it's stored. This ensures data integrity from the moment it is written [4].
When to Use Databases
Databases are essential when your application needs to store and retrieve live, detailed information with minimal delay. They are commonly used in:
E-commerce platforms: Managing inventory, processing customer orders, and maintaining product catalogs.
Financial systems: Handling high-speed transactions, tracking account balances, and detecting fraud in real time.
Healthcare: Storing patient records, scheduling appointments, and managing prescriptions.
For relational database needs, popular options include MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. For non-relational (NoSQL) needs, MongoDB, Cassandra, and Redis are widely used [4]. As Tom Gardiner, CEO of Embeddable, explains:
"There's a big difference between database types. Their individual qualities should be carefully considered when planning for different applications - to ensure you can deliver the desired result" [6].
When data integrity, well-defined relationships, and instant responses are critical, databases are the go-to solution. Up next, we’ll look at how data warehouses are designed to handle analytic workloads differently.
Data Warehouses: Designed for Analytics
Data warehouses are the go-to solution for centralizing structured historical data to uncover analytical insights. Acting as a centralized repository, they pull together information from various systems like CRM, ERP, and financial applications. This consolidation creates a reliable "single source of truth" for an organization’s historical performance.
What Is a Data Warehouse?
Data warehouses operate using a schema-on-write approach. This means all incoming data must fit into a predefined structure before being stored. To make this work, an ETL (Extract, Transform, Load) process is used to pull data from different sources, clean it, and load it into a fixed schema. The result? Consistent, high-quality data that’s ready for analysis.
Their architecture typically has three layers:
ETL layer: Handles data ingestion.
Analytics layer: Supports tools like OLAP and SQL for complex queries.
Reporting layer: Powers dashboards and visualizations.
This structure is fine-tuned for running complex analytical queries, unlike databases designed for quick transactional lookups. As MongoDB puts it, a data warehouse is essentially a massive database built specifically for analytics [8].
Data warehouses don’t deal with live transactional data. Instead, they store years’ worth of information - ranging from hundreds of gigabytes to multiple petabytes - making them perfect for analyzing trends and forecasting. Their fixed schema also allows users to work with standard SQL tools, making data analysis more user-friendly for business teams.
These unique features open the door to a wide range of practical applications.
Best Uses for Data Warehouses
Thanks to their architecture, data warehouses excel in scenarios requiring integrated analysis across departments. With self-service BI tools like Tableau and Power BI, business analysts and executives can generate insights without needing advanced technical skills.
Some common applications include:
Financial risk management
Historical market trend analysis
Cross-retail customer behavior insights
Healthcare operations optimization
Marketing teams can also create focused data marts, enabling faster campaign analysis and decision-making.
"Data warehousing will become crucial in machine learning and AI. That's because ML's potential relies on up-to-the-minute data, so that data is best stored in warehouses - not lakes" [1].
Mark Cusack, CTO of Yellowbrick
Data Lakes: Storage for Raw Data
While data warehouses focus on organizing historical data for analysis, data lakes take a different approach by storing raw data in its original form. This means data lakes can handle a variety of formats, from structured relational tables to unstructured media files, making them a great choice for managing large, diverse datasets - even when the exact use of the data hasn't been determined yet [7] [9].
The standout feature of data lakes is their schema-on-read processing. Instead of transforming data before storage, the structure is applied only when the data is queried. Microsoft puts it this way:
"A data lake helps you store everything in its original, untransformed state, deferring transformation until the data is needed" [7].
Another key advantage is the separation of storage and computing. Cloud platforms like AWS S3 and Azure Data Lake Storage make it easy to scale storage while keeping costs manageable. This flexibility is a sharp contrast to the rigid setups of traditional systems. It’s also practical - 68% of organizational data often remains unanalyzed because of storage silos [10]. By breaking down these barriers, data lakes provide a scalable and cost-efficient way to store massive amounts of data, paving the way for advanced analytics.
Core Features of Data Lakes
Data lakes typically follow an ELT process (Extract, Load, Transform), where data transformations happen only when needed for analysis. This approach offers unmatched flexibility, but it comes with a challenge: without proper metadata management and cataloging, a data lake can turn into a "data swamp", where locating or trusting data becomes difficult [7] [9] [10].
These systems can handle nearly any data type, including:
IoT sensor readings
Website logs
Social media feeds
Mobile app clickstreams
CSV and Parquet files
PDFs and other document formats
Unsurprisingly, 75% of leading chief data officers are investing in data lakes [10], and 66% of organizations rely on the public cloud as their primary environment for hosting them [9]. With these features, data lakes are becoming essential for modern data strategies.
Where Data Lakes Fit
Data lakes shine in scenarios where raw, unprocessed data is crucial. They are particularly valuable for machine learning model training, where diverse datasets - like text, images, and videos - help algorithms identify complex patterns. The growing demand for Generative AI and Large Language Models has only increased the importance of these repositories, as these technologies thrive on unstructured data.
Data lakes are also perfect for exploratory data analysis, giving data scientists the freedom to experiment without being tied to a fixed schema. Common applications include:
Storing IoT sensor data from manufacturing equipment
Archiving customer interaction logs
Managing large media libraries
AWS highlights their suitability for cloud deployment:
"Data lakes are an ideal workload to be deployed in the cloud, because the cloud provides performance, scalability, reliability, availability, a diverse set of analytic engines, and massive economies of scale" [9].
This makes data lakes a cost-effective solution for archiving historical data ("cold" storage) that might be needed for compliance or future analyses.
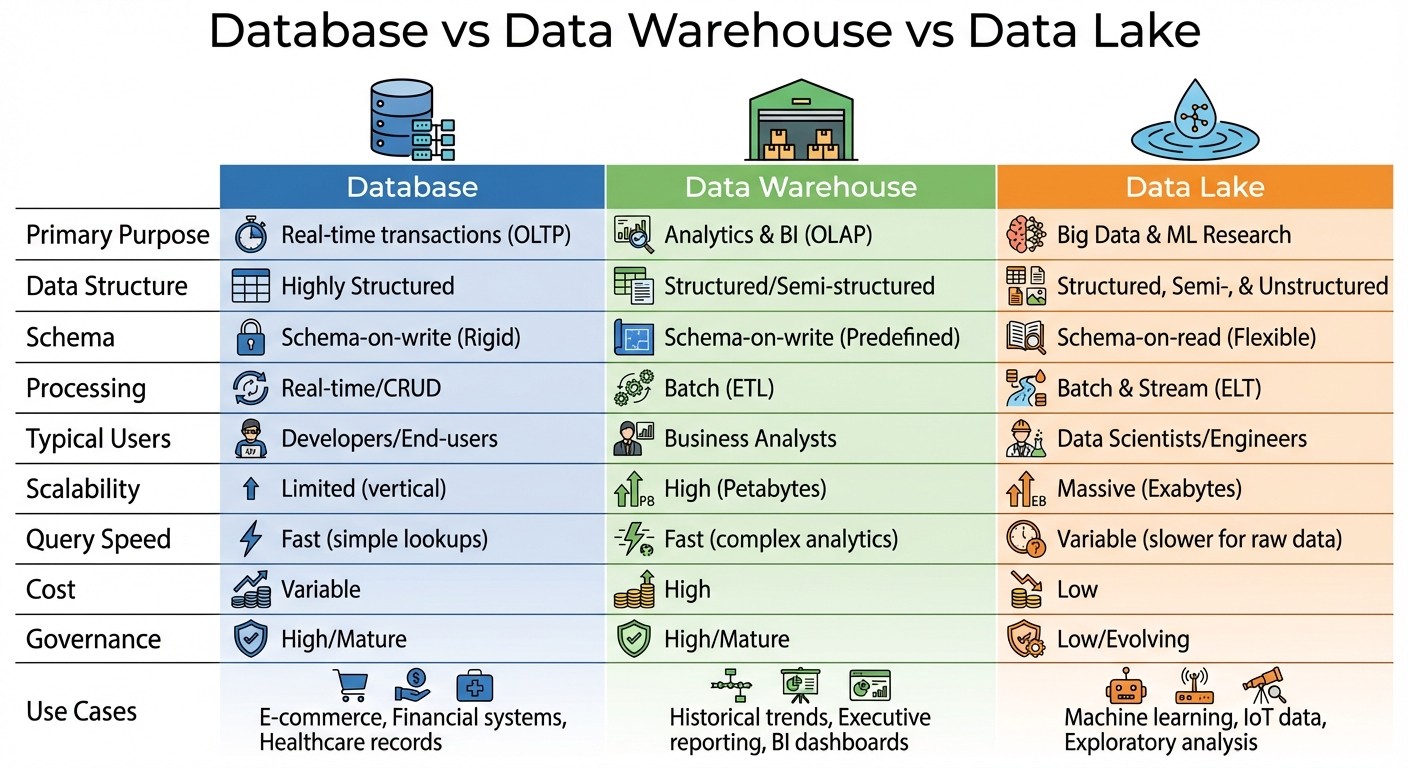
Database vs Data Warehouse vs Data Lake: Side-by-Side Comparison
Now that we've broken down each solution individually, let’s see how they compare directly. This side-by-side view helps clarify their differences so you can decide which option best suits your organization's needs.
Comparison Table
Here’s a detailed look at how databases, data warehouses, and data lakes differ across several key aspects:
Dimension | Database | Data Warehouse | Data Lake |
|---|---|---|---|
Primary Purpose | Real-time transactions (OLTP) | Analytics & BI (OLAP) | Big Data & ML Research |
Data Structure | Highly Structured | Structured / Semi-structured | Structured, Semi-, & Unstructured |
Schema | Schema-on-write (Rigid) | Schema-on-write (Predefined) | Schema-on-read (Flexible) |
Processing | Real-time / CRUD | Batch (ETL) | Batch & Stream (ELT) |
Typical Users | Developers / End-users | Business Analysts | Data Scientists / Engineers |
Scalability | Limited (often vertical) | High (Petabytes) | Massive (Exabytes) |
Query Speed | Fast (for simple lookups) | Fast (for complex analytics) | Variable (slower for raw data) |
Cost Factor | Variable (per instance) | High (Compute intensive) | Low (Storage focused) |
Governance | High / Mature | High / Mature | Low / Evolving |
This table lays out the key distinctions to help you evaluate your options. One standout difference is the approach to schemas: databases and data warehouses rely on predefined schemas (schema-on-write), while data lakes allow greater flexibility with schema-on-read.
Cost considerations also vary significantly. Data lakes are typically more affordable for storing large amounts of raw data, while data warehouses incur higher costs due to their compute-heavy nature. Databases, on the other hand, have costs that depend on the specific instance or setup.
The intended audience for each solution also differs. Databases are essential for developers managing real-time application data, data warehouses cater to business analysts generating reports and dashboards, and data lakes are favored by data scientists and engineers working on machine learning models or exploratory analysis.
This comparison provides a clear framework for identifying the right solution based on your business priorities and use cases.
How to Choose the Right Solution
Building on our comparison, selecting the right data solution depends entirely on your data analytics strategy and organizational goals. The choice hinges on how you plan to use and manage your data.
When Databases Are the Best Fit
Databases are your go-to solution for supporting live applications or handling real-time customer transactions. If your focus is on ensuring immediate data consistency for daily operations - like processing orders in an online store, managing inventory, or handling user accounts - a database is the way to go. They are built for Online Transaction Processing (OLTP) and adhere to ACID principles (Atomicity, Consistency, Isolation, Durability), ensuring operational accuracy and reliability. For developers needing fast and dependable read/write operations to keep applications running seamlessly, databases are indispensable.
When Data Warehouses Are the Right Choice
Data warehouses shine when you need a centralized hub for business analytics. They’re perfect for running complex SQL queries, creating dashboards, and tracking historical key performance indicators (KPIs) across departments. Built for Online Analytical Processing (OLAP), data warehouses are ideal for tasks like historical trend analysis, executive reporting, and comparing regional or departmental performance. If your stakeholders rely on structured, reliable data for decision-making, a data warehouse delivers the speed and structure required for these insights.
When Data Lakes Are Ideal
Data lakes are perfect for handling massive amounts of raw, unstructured data. Think IoT sensor outputs, social media streams, or log files - data that may later be used for machine learning or experimental analysis. They’re especially useful when the exact purpose of the data hasn’t been determined yet. With the ability to store petabytes (1,000 terabytes) of information, data lakes are a cost-effective solution for big data exploration and storage [2]. This flexibility makes them a top choice for data science and exploratory projects.
Combining Multiple Solutions
Many organizations benefit from using all three solutions in a layered architecture. A common approach involves:
Data lakes for collecting and storing raw data.
Data warehouses for structured analytics and reporting.
Databases for real-time operations.
This setup allows data scientists to explore raw data in the lake, business analysts to run structured queries in the warehouse, and developers to maintain smooth application performance with databases. By separating workloads in this way, you ensure efficiency while meeting a variety of analytics and operational needs [3].
Conclusion
Main Points to Remember
Each data storage solution has its own strengths. Databases excel at managing real-time transactions with ACID compliance, making them indispensable for live applications like e-commerce sites or customer account systems. Data warehouses act as centralized hubs for structured historical data, optimized for business intelligence, complex SQL queries, and executive-level reporting. On the other hand, data lakes offer flexible, low-cost storage for massive amounts of raw data - whether structured, semi-structured, or unstructured - making them a go-to choice for data science and machine learning initiatives.
The difference in design philosophies - schema-on-write for databases and warehouses versus schema-on-read for data lakes - shapes their usage. Application developers often rely on databases, business analysts turn to data warehouses, and data scientists dig into data lakes for insights [1][5].
Selecting the right solution depends on your business goals, the types of data you handle, and the needs of your users. Many organizations achieve success by combining all three in a layered system: data lakes for raw data ingestion, data warehouses for refined analytics, and databases for operational tasks. This approach balances efficiency with the ability to meet diverse analytical and operational demands.
With global data volumes expected to hit around 158 zettabytes by 2025, it's clear that choosing the right storage strategy is becoming more important than ever for managing costs and maximizing analytical performance [11].
FAQs
Can I use a data lake for BI dashboards?
Yes, you can absolutely use a data lake for BI dashboards. But here’s the thing: data lakes store raw, unstructured data. That means you’ll usually need to process, transform, and organize the data first to make it compatible with analytics and visualization tools. This extra step ensures the data is ready for effective business intelligence reporting.
What’s the simplest way to move data from a database into a warehouse?
The ETL process - short for Extract, Transform, Load - is the most straightforward way to transfer data from a database to a data warehouse. Here's how it works: data is first extracted from the source database, then transformed into a format that aligns with the warehouse's requirements, and finally loaded into the warehouse. This method is widely recognized for efficiently preparing structured data for analysis and reporting.
How do I keep a data lake from becoming a data swamp?
To keep a data lake from becoming a messy, unmanageable "data swamp", it's essential to focus on governance and metadata management. Start by organizing, labeling, and documenting your data so it’s easy to locate and interpret. Regular maintenance is key - clean, validate, and catalog the data regularly to ensure it stays accurate and useful.
You should also enforce strict access controls and security measures to protect sensitive information. And don’t overlook scalability - partitioning data and archiving outdated files can help prevent clutter and keep the system running efficiently.
Related Blog Posts


