Modern Data Warehouse Architectures Explained
Explore modern data warehouse architectures. Learn how to choose the right design, from traditional patterns to cloud-native systems, to power your analytics.
https://www.youtube.com/watch?v=f6zXyq4VPP8
published
Outrank AI
data warehouse architectures, cloud data warehouse, data modeling, data architecture, self-serve analytics
6fe005a7-dad4-4c9e-9edb-66ad008e3167

Your data warehouse architecture isn't just a technical drawing for the engineering team. Think of it as the master blueprint for your company's entire data strategy. The architectural choices you make today will directly impact how quickly your teams can find answers, build new products, and sidestep the costly bottlenecks that plague so many organizations.
Why Your Data Warehouse Architecture Matters
A well-designed architecture is the central nervous system of your business. It’s the system that takes all the scattered signals—sales figures from your CRM, campaign metrics from your marketing tools, and user behavior from your product—and translates them into a single, coherent story.
Without that solid foundation, your data stays locked away in isolated silos. When that happens, getting a complete picture of your business isn't just hard; it's practically impossible.
The idea of bringing all this business information together isn't new. The real breakthrough came in the late 1980s. Before that, data was fragmented, and a unified view was a pipe dream. When Barry Devlin and Paul Murphy at IBM first introduced the "business data warehouse" in 1988, they provided the first real solution to this problem. By the late 1990s, their architectural concepts became the gold standard for any large company serious about its data.
Getting the architecture right is a crucial business decision, not just an IT one. The wrong choice leads to painfully slow reports, frustrated analysts, and leaders who can't get the timely answers they need to steer the ship. A strong architecture, on the other hand, quickly becomes a powerful competitive advantage.
Core Functions of a Data Warehouse Architecture
At its heart, a data warehouse architecture serves a few critical roles. Understanding these functions helps clarify why its design is so important.
Function | Business Impact |
|---|---|
Data Integration | Unifies data from dozens of disparate sources (e.g., Salesforce, Google Ads, Stripe) into a single location. |
Data Storage | Provides a secure, scalable, and cost-effective repository for historical and current analytical data. |
Data Transformation | Cleans, structures, and models raw data into a reliable format that's ready for analysis and reporting. |
Data Access | Enables business users, analysts, and data scientists to query and explore data through BI tools and SQL. |
These functions work together to create a single source of truth, eliminating the guesswork and conflicting reports that come from siloed data.
From Bottleneck to Enabler
In the past, data warehouses were rigid, complex, and walled off. If a business user needed a report, they had to file a ticket with the data team and wait—sometimes for days or even weeks. This model created a massive bottleneck that slowed down decision-making across the entire company.
Modern data warehouse architectures, especially those built for the cloud, completely flip that script. They’re designed from the ground up for flexibility, massive scale, and, most importantly, self-service. The goal is no longer just to store data; it's to empower everyone in the organization to explore it for themselves.
An effective architecture transforms the data team from a reactive service desk into proactive enablers of a data-driven culture. It's the difference between being a gatekeeper and building a highway.
This shift has profound, practical implications for every team:
Product teams can analyze user behavior in near real-time to decide which features to build next.
Marketing departments can measure campaign ROI and adjust budgets on the fly, without waiting on an analyst.
Executives can pull up a dashboard and get a holistic view of business health, all from one reliable source.
To get the most out of your data, the architecture needs to be part of a cohesive modern enterprise data strategy. The architecture you choose is the engine that brings that strategy to life. If you want to dig deeper into the fundamentals, you can explore the core concepts of a data warehouse here. In the sections that follow, we'll break down the different architectural patterns that make all of this possible.
Understanding the Great Data Warehouse Debate: Inmon vs. Kimball
Before you can really wrap your head around modern data warehouse architecture, you have to understand the two competing philosophies that have shaped this space for decades. This isn't just some dusty old history lesson; it's a fundamental debate that still influences how data teams build their single source of truth today. The entire field was shaped by two pioneers, Bill Inmon and Ralph Kimball, who had completely different ideas on how to get the job done.
Imagine you're tasked with building a city's entire library system from scratch. Do you start by building a massive, centralized main branch, making sure every single book is perfectly cataloged under one unified system before anyone can check anything out? Or do you start by quickly building smaller, specialized neighborhood libraries, each tailored to its community, and figure out how to connect them later?
That's the core of the Inmon vs. Kimball debate.
The Inmon Model: Top-Down and Built for Consistency
Bill Inmon, often called the "father of the data warehouse," argued for the first approach. He championed a top-down philosophy where the absolute priority is creating a single, highly structured, and normalized Enterprise Data Warehouse (EDW). This EDW would serve as the central, undisputed hub for all company data.
Here's how it works: raw data from all over the company is pulled through a rigorous ETL (Extract, Transform, Load) process and organized into a highly disciplined, non-redundant structure. Only after this central repository is perfected are smaller, subject-specific data marts spun off for departments like sales, marketing, or finance.
It’s all about building that massive central library first.
The Goal: Create one, and only one, enterprise-wide version of the truth. Consistency is king.
The Process: All data is integrated and normalized centrally before anyone in a specific department gets to use it.
The Strength: Unbeatable data integrity.
Because every piece of data flows from a single, quality-controlled source, you dramatically reduce the risk of the marketing team and the sales team showing up with conflicting numbers. This makes the Inmon model a go-to for large, complex enterprises where governance and rock-solid accuracy are non-negotiable.
The Kimball Model: Bottom-Up and Built for Speed
Ralph Kimball came at it from the completely opposite direction. He proposed a bottom-up approach designed to deliver value to the business as quickly as possible. Why wait for a massive, multi-year project to finish when you can get actionable insights now?
Kimball's method starts by building individual data marts that are hyper-focused on specific business processes. Each data mart is built using a dimensional model (often a star schema), which is intuitive for business users and optimized for fast queries and reporting.
These separate data marts are then woven together into a cohesive whole using "conformed dimensions"—basically, shared and standardized reference points like 'Customer ID' or 'Product SKU'. It’s like building those nimble neighborhood libraries first, but making sure they all use the same universal card catalog system so they can eventually talk to each other.
Kimball's philosophy was incredibly pragmatic: get useful data into the hands of business users, fast. Instead of waiting for a monolithic enterprise warehouse to be built, teams could start generating reports and finding insights from their own data marts in a fraction of the time.
This split in the 1990s created two very different paths. Inmon's approach was often the choice for massive corporations trying to tame hundreds of data sources that demanded strict, centralized control. Meanwhile, Kimball's more agile, business-friendly design was a natural fit for individual departments or mid-sized companies that couldn't afford to wait years for results.
Comparing The Two Philosophies
The trade-offs here are pretty clear, and they are significant.
Aspect | Inmon Model (Top-Down) | Kimball Model (Bottom-Up) |
|---|---|---|
Primary Goal | Enterprise-wide consistency | Business process speed & usability |
First Step | Build the central EDW | Build departmental data marts |
Data Structure | Normalized (3NF) | Dimensional (Star Schema) |
Implementation | Slower, more resource-intensive | Faster, iterative, and agile |
Flexibility | Less flexible to new requirements | Highly adaptable to business changes |
So why does this old debate still matter? Because the best modern cloud data architectures have learned to blend elements from both. Today's platforms, like Snowflake or Google BigQuery, have the sheer scale to support an Inmon-style central repository while also giving you the flexibility to quickly spin up Kimball-style virtual data marts for different teams.
To dive deeper into these structures, check out our complete guide on the data warehouse model.
Diving Into Common Data Warehouse Architectures
Now that we’ve covered the high-level philosophies, let's get our hands dirty and look at how data warehouses are actually built. Over the years, a few common architectural patterns have emerged. Understanding these classic models is crucial because it really puts into perspective just how much modern cloud solutions have changed the game.
We’ll walk through the traditional architectures—Single-Tier, Two-Tier, and Three-Tier—before jumping into the cloud-native model that has completely reshaped the industry. Each one represents a distinct way of getting data from its raw, messy state into a clean, analysis-ready format.
The Single-Tier Architecture: A Minimalist Approach
The simplest model you’ll find is the Single-Tier architecture. Think of it as an all-in-one setup where the database, the analytical engine, and the reporting tools all live on a single server. The main goal here is to keep data movement to an absolute minimum to spit out reports as fast as possible.
Because everything is in one box, it’s pretty straightforward to get up and running. But here’s the catch: that simplicity is also its biggest weakness. With every process competing for the same resources, you create a massive performance bottleneck. This approach simply doesn't scale. It might work for a tiny team or a very specific data mart with little data, but it falls apart under any serious analytical pressure.
The Two-Tier Architecture: Separating Sources From The Warehouse
The Two-Tier architecture was a significant step up. This pattern creates a clear line between your data sources and the data warehouse itself. The first tier holds all the source systems—your CRM, ERP, transactional databases, and so on. The second tier is the warehouse server, where all that data is cleaned, stored, and ready for analysis.
In this setup, data is pulled from the sources and loaded into the warehouse. Your dashboards and reporting tools then connect directly to this second tier. This separation gives you a nice performance boost because the heavy lifting of analysis doesn't slow down your day-to-day operational systems. For many years, this was the standard, but it still often kept the data storage and the processing engine bundled together, which could cause its own set of conflicts.
The Three-Tier Architecture: The Classic Model
The most famous traditional pattern is the Three-Tier architecture. It brings a whole new level of organization by splitting the system into three distinct layers, each with its own job.
Bottom Tier (Data Warehouse Server): This is the foundation. It’s the database server where data is stored after being extracted and transformed from the source systems. It's all about core data management.
Middle Tier (OLAP Server): This layer is the "business logic" engine. It sits between the users and the raw data, often using an Online Analytical Processing (OLAP) server. It pre-calculates and organizes data into multidimensional cubes, making it much easier for business folks to slice and dice information without needing to be SQL wizards.
Top Tier (Front-End Client): This is what the user actually sees. It’s the presentation layer, made up of the query tools, reporting apps, and interactive dashboards.
This clean separation of duties provides much better organization and scalability than the earlier models. The downside? All these layers can add complexity and latency, sometimes making the whole system feel sluggish. Just keeping the lights on and managing the connections between these tiers can be a full-time job.
A major distinction in data warehouse design lies in whether you build from the top down for consistency (Inmon) or from the bottom up for speed (Kimball). Modern architectures often blend these approaches.
The two foundational philosophies that have shaped these architectural patterns, Inmon and Kimball, offer different paths to the same goal. One prioritizes enterprise-wide consistency, while the other focuses on delivering value to specific business units quickly.
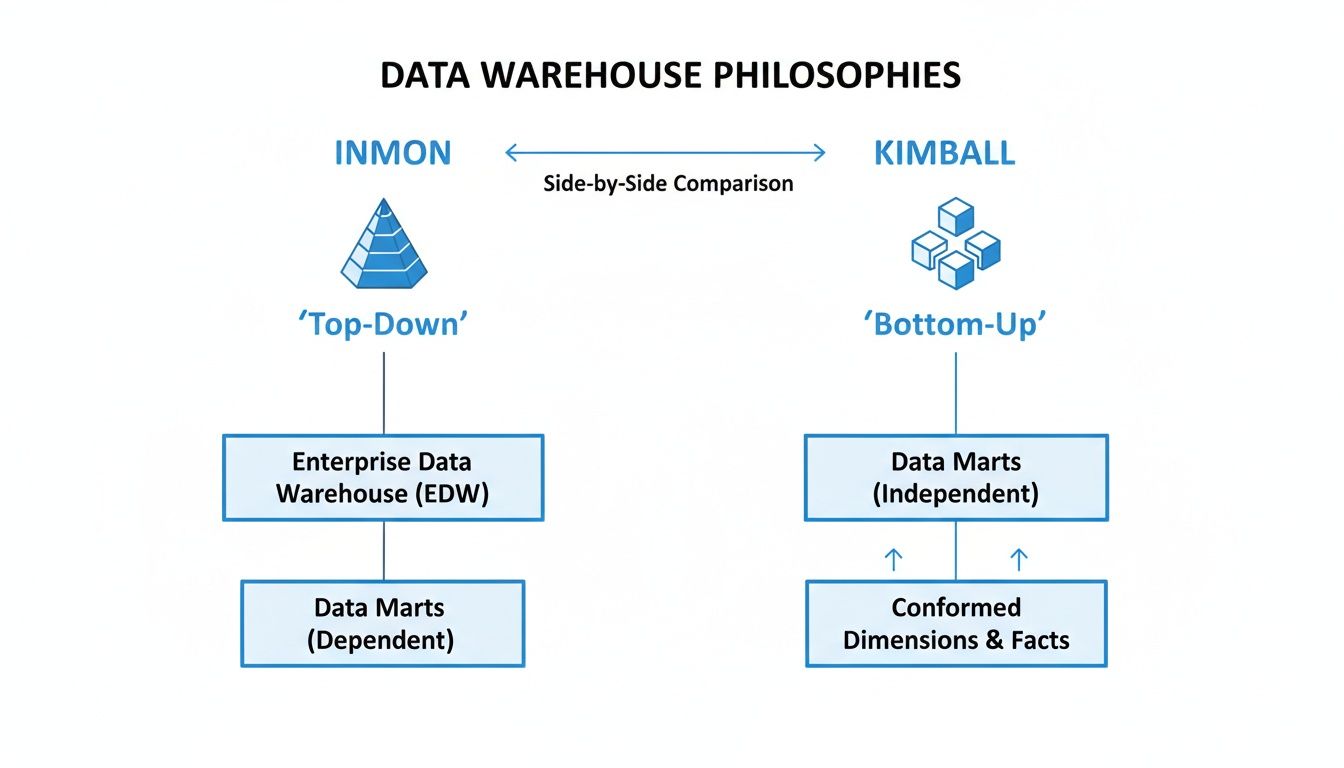
This visual really captures the core trade-off: Inmon’s structured, top-down approach gives you a single source of truth but takes longer to build. Kimball’s agile, bottom-up model delivers insights faster but can sometimes lead to "silos" of data.
To help you decide which approach might fit your needs, here's a quick breakdown of how these classic patterns stack up against the modern cloud model.
Comparison of Data Warehouse Architecture Patterns
Architecture Pattern | Key Characteristic | Best For | Main Limitation |
|---|---|---|---|
Single-Tier | All components (storage, processing, presentation) on a single server. | Very small teams or single-purpose data marts with minimal data and few users. | Creates a major performance bottleneck; does not scale. |
Two-Tier | Separates source systems from the data warehouse server. | Departmental solutions where analytical workloads need to be isolated from operational systems. | Storage and compute are often still coupled, leading to resource contention. |
Three-Tier | Logically separates data storage, analytical processing (OLAP), and presentation layers. | Large enterprises needing a highly structured, organized, and scalable system for diverse user groups. | Increased complexity, potential for latency, and significant administrative overhead. |
Cloud-Native | Decouples storage and compute, allowing them to scale independently. | Organizations of any size that need elasticity, cost-efficiency, and the ability to handle massive, spiky workloads. | Can lead to unpredictable costs if compute usage is not monitored and managed carefully. |
As the table shows, each of the traditional models served its purpose but was ultimately constrained by its physical and logical limitations.
The Modern Cloud-Native Architecture
This brings us to the real game-changer: the modern cloud-native architecture. Platforms like Snowflake, Google BigQuery, and Amazon Redshift didn't just improve on the old models—they tore up the blueprint and started over with one core principle: the separation of storage and compute.
Think of it like trying to expand a traditional library. If you need more room for books, you have to build a bigger building. If you need more librarians to help people find those books, you also have to expand the building. You can't just add one without the other. That’s exactly how legacy data warehouses worked; storage and processing power were stuck together.
Cloud platforms broke that dependency. Now, storage and compute are completely separate resources you can scale up or down independently.
You can store petabytes of data cheaply without paying for massive, always-on processing power.
When you need to run a huge, complex query, you can instantly spin up a powerful compute cluster to handle it, and then shut it down the moment it’s done.
This elasticity finally cracked the code on the performance bottlenecks that held back older systems. Of course, for any team looking at these platforms, understanding the financial side is critical. For instance, a detailed guide to Amazon Redshift pricing and models can help you evaluate whether a provisioned or serverless approach makes more sense for your budget and workload.
This architectural shift is also a lifesaver for governance. Modern platforms allow you to set up federated permissions, meaning you define your security policies once and they apply everywhere. A single set of rules can control access across your entire data landscape, making it vastly simpler to manage security at scale. And if your data is scattered across different systems, you'll want to dig into the trade-offs between a centralized warehouse and other modern structures by understanding the differences between a data warehouse vs a data lake.
How To Choose The Right Architecture For Your Business
Picking a data warehouse architecture isn't just a job for the IT department; it's a strategic business decision. The right choice can become a powerful engine for growth. The wrong one? It’s a money pit—an expensive, rigid system that becomes a bottleneck for the entire company.
So, how do you get it right? Instead of getting bogged down in technical jargon, let's walk through a few key questions about your business. The answers will point you toward an architecture that actually fits what you need today and where you're headed tomorrow.
Assess Your Business Scale and Complexity
First things first: take an honest look at your data reality. Are you a small startup pulling data from a couple of SaaS tools, or are you a global enterprise juggling hundreds of systems and a firehose of new information every day?
The scale of your operation completely changes the game.
For small businesses or startups: Your main goal is getting from data to decisions, fast. A simple, cloud-native warehouse on a platform like Google BigQuery or Snowflake is your best bet. It’s affordable, easy to get running, and you can scale it up as you grow. Don't over-engineer it.
For mid-sized companies: You're probably starting to feel the growing pains of more data from more places. You need a more structured approach. A cloud architecture that separates storage and compute is perfect here. It gives you the flexibility to handle big analytical queries without your costs spiraling out of control.
For large enterprises: You're operating at a massive scale, with complex compliance rules and tons of different teams needing data. A hybrid or multi-cloud strategy often makes the most sense, allowing you to blend different architectural patterns to serve specific departments while keeping a firm grip on governance.
Evaluate Your Data Team's Maturity
The world's most sophisticated architecture is worthless if you don't have the team to run it. Be real about your team's current skills and bandwidth.
A small team of two or three data pros will drown trying to manage a complex, multi-layered system. They need a managed, low-maintenance solution that frees them up to find insights, not just perform endless upkeep. On the flip side, a large, mature data organization with dedicated engineers can build and support a much more powerful, customized setup.
The goal is to choose an architecture that empowers your team, not one that requires you to hire an entirely new one just to operate it.
A modern platform should actually reduce your team's administrative burden. For example, features like the federated permissions in Amazon Redshift let a team define security rules once and apply them everywhere. This kind of efficiency is a lifesaver for governance, no matter how big your team is.
Define Your Need For Speed and Agility
How fast does your business move? If you're in a market that changes on a dime, you need an architecture that can keep up without a six-month redevelopment project for every new idea.
This is where legacy, on-premise systems really fall down. They are notoriously inflexible. Adding a new data source or tweaking a business metric can turn into a slow, painful ordeal.
Cloud-native data warehouse architectures are built for agility. Because their components are decoupled, you can spin up new compute power, test out new data models, and plug in new tools in a matter of days, not months. This gives your product and marketing teams the freedom to experiment and iterate, which is a massive competitive advantage.
Consider Who Needs Access To Data
Finally, think about who will actually be using this data. Are you building a system for a handful of highly-trained data analysts, or is your goal to empower hundreds of employees across the company with self-service analytics?
Analyst-heavy teams are comfortable working directly with complex data models and raw SQL.
Business users in sales, marketing, and operations need simple, intuitive tools that hide the complexity of the warehouse.
Your architecture has to support that "last mile" of data delivery. A brilliant data warehouse is a total failure if only a few gatekeepers can unlock its value. Modern solutions are designed to be the foundation for a whole ecosystem of BI tools, from Tableau to self-serve analytics platforms like Querio.
The right architecture ensures that when someone in marketing has a question, they can get a fast, accurate answer themselves.
Powering Self-Serve Analytics on Your Warehouse
Building a technically perfect data warehouse is only half the battle. The real test for any modern data warehouse architecture isn't just about storing data efficiently—it's about making that data genuinely useful for everyone in the organization. If your business teams can't get answers to their own questions, that sophisticated architecture is little more than a very expensive, underused database.
This is the classic “last-mile problem” in analytics. A company pours resources into a powerful cloud data warehouse, but every request for a new chart or a simple metric still gets funneled through a small, overwhelmed data team. The team effectively becomes a human API, and the dream of a data-driven culture grinds to a halt.
Solving this means adding a dedicated self-service analytics layer that sits right on top of your warehouse. Think of this layer as a user-friendly interface that empowers both technical and non-technical people to explore data directly, without needing to write a single line of SQL.
Moving Beyond the Bottleneck
When business users are stuck filing tickets for every data request, the data team is trapped in a reactive loop. Their days are spent pulling basic numbers instead of tackling the high-impact strategic projects they were hired for. A self-serve layer breaks this cycle for good.
Instead of being a bottleneck, the data team steps into a far more powerful role: they become enablers. Their work shifts from answering one-off questions to building and maintaining the reliable, self-service infrastructure that everyone else depends on.
With this model in place, different teams can finally find their own insights:
Product Managers can build their own funnels to track feature adoption without waiting in a queue.
Marketing Teams can create live dashboards to see how campaigns are performing in real-time.
Customer Success can analyze product usage patterns to spot at-risk accounts before they churn.
The ultimate goal is to transform the data team from a reactive service desk into proactive builders of a data-informed culture. This is where the architectural investment finally pays off.
By giving people the right tools, you democratize access to the insights locked away in your warehouse. For example, a platform like Querio uses AI agents that let users ask questions in plain English, completely removing the technical barrier to data exploration. This approach ensures the value of your data warehouse architecture reaches every corner of the business.
From Governance Nightmare to Secure Empowerment
A common—and valid—fear with self-service analytics is losing control over data governance. If you give everyone access, how do you prevent chaos and make sure data is used correctly and securely? Fortunately, modern data platforms are designed to solve this very problem.
Cloud data warehouses like Amazon Redshift now offer federated permissions, which let data teams define security policies once and have them automatically enforced across the entire system. You can set rules based on a user's role, guaranteeing they only see the data they're authorized to see.
For instance, a data team can put specific access controls in place:
Row-Level Security: A sales rep for the West region sees customer data for their territory, and nothing more.
Dynamic Data Masking: A support agent can view customer details but has sensitive information like credit card numbers automatically hidden.
These fine-grained controls are defined once in the warehouse and are inherited by any self-service tool connected to it. This means you can open up access with confidence, knowing your governance rules are always being enforced at the source. The warehouse becomes a secure, governed foundation for widespread analytics.
This combination of a powerful cloud warehouse and a smart, user-friendly analytics layer is what unlocks true self-service. It’s how you get the full return on your architectural investment and build a company where data-driven decisions aren't just possible—they're easy.
Steering Clear of Common Migration and Governance Traps
Changing or building a new data warehouse architecture is a massive project. It's so much more than a simple software swap. In my experience, success comes down to sidestepping the human and process-related landmines that can blow these initiatives up before they even get going.
One of the first traps teams fall into is drastically underestimating the migration effort. There's this tempting idea that you can just "lift and shift" the old warehouse onto a shiny new cloud platform. The reality is far messier. You're actually signing up to untangle years of baked-in legacy logic, rewrite an ocean of queries, and painstakingly remap every data pipeline. This isn't a weekend job; it's a process that can easily stretch over months, sometimes even years.
Right alongside that is the pitfall of picking a vendor based on marketing hype. Every cloud provider will tell you they have the fastest, cheapest solution. But the right choice for your team depends entirely on your existing skills, the tools you already use, and the specific kinds of questions your business asks of its data.
Weave in Governance from the Very Beginning
If there's one mistake that's almost impossible to recover from, it's pushing data governance to the back burner. I hear it all the time: "We'll sort out governance once we're live." This is a guaranteed recipe for creating a "data swamp," where nobody trusts the data and every dashboard tells a different story.
You don't need a perfect, 500-page governance manual on day one. Just start with the basics.
Build a simple data catalog: Start by just documenting your most important data sources. What is this dataset, where did it come from, and what does it represent?
Define clear data ownership: Assign a specific person or team to be the go-to expert for key domains, like "customer data" or "product usage data." When a number looks off, everyone knows exactly who to call.
Roll out essential policies first: Don't try to boil the ocean. Begin with basic access controls and data quality checks on a handful of your most valuable datasets.
The point isn't to create a flawless governance bible overnight. It's to build a foundation of trust and accountability that can grow and adapt along with your data culture.
Laying down these ground rules early on prevents the chaos of an ungoverned free-for-all. For a much deeper look into this, our guide on data governance best practices has more strategies you can put to work immediately.
Take a Step-by-Step, People-First Approach
Few things are as risky as a "big bang" migration where you try to switch everything over at once. A much smarter—and safer—strategy is to migrate in phases. Move one business unit or a single important use case at a time. This gets a win on the board quickly, lets you learn from the small mistakes that will inevitably happen, and builds the confidence and momentum you need for the bigger project.
Finally, don't ever forget about the people who will actually use the warehouse. A brand-new system is completely worthless if your business colleagues don't understand it, don't trust it, or don't know how to get what they need from it. Involve them from the start, write clear documentation, and run training sessions that show them exactly how this new tool makes their work easier. Ultimately, the success of your data warehouse is measured by how many people use it to make better decisions.
Frequently Asked Questions
Even with a solid plan in place, a few common questions always pop up when data teams and product leaders are weighing their data warehouse options. Here are the answers to the ones we hear most often.
What Is The Difference Between A Data Warehouse, A Data Lake, And A Data Lakehouse?
Let's break that down with an analogy.
Think of a data warehouse as a meticulously organized research library. Every piece of information (data) has been cleaned, categorized, and placed in a specific spot. It’s perfect for answering specific questions quickly and reliably, which is why it excels at business intelligence and reporting.
A data lake, on the other hand, is like a massive, unsorted archive. It holds everything—raw, unprocessed data in every format imaginable. It's incredibly flexible but can get messy without a good system.
The data lakehouse is the new kid on the block, blending the best of both worlds. It gives you the raw storage flexibility of a data lake combined with the powerful management and query features of a warehouse. This hybrid approach lets you run both traditional analytics and complex machine learning tasks from a single source of truth.
How Long Does It Take To Build A Data Warehouse?
Honestly, the timeline is all over the map. It completely depends on the scope and your team's approach.
A nimble startup using a cloud platform like BigQuery or Snowflake can often get a basic warehouse up and running in just a few weeks. The goal here is speed and immediate value.
In stark contrast, a massive enterprise building a traditional, on-premise warehouse from scratch could easily spend 1-2 years on the project. That's why most teams today don't do a "big bang" launch. They take an agile approach, delivering value one piece at a time.
Our advice: Treat a warehouse build or migration like any other major initiative. Start small, maybe with a single business unit, and show some quick wins. This builds momentum, gets you buy-in, and dramatically lowers your risk.
Can I Switch Data Warehouse Architectures Later?
The short answer is yes, but it’s a huge undertaking. Changing your core architecture—say, moving from a legacy on-premise system to the cloud—is not a simple lift-and-shift.
You're looking at a complex data migration project, plus the massive effort of rewriting all your ETL/ELT pipelines to work with the new system. It's often disruptive, costly, and resource-intensive.
This is exactly why your initial choice is so important. You need to think beyond your current needs and pick a path that can grow with you. Choosing modern, platform-agnostic tools from the get-go can make any future transitions significantly less painful.
At Querio, we deploy AI agents directly onto your data warehouse to empower your entire team with self-serve analytics. Stop being a data bottleneck and start building a scalable data culture. Get started with Querio today.

