Time Series Analysis in Python: A Practical Guide
Learn time series analysis in Python with this hands-on guide. Walk through data prep, modeling with ARIMA, Prophet, and LSTMs, and evaluation.
https://www.youtube.com/watch?v=jhh4tHYmVew
published
Outrank AI
time series analysis in python, python forecasting, data analysis python, prophet python, arima python
d81140ef-e3a2-4259-8fd1-c1994dd4e5c8

You've probably got a CSV export open right now, a timestamp column that may or may not parse cleanly, and a stakeholder asking for “a forecast by tomorrow.” That's the normal starting point for time series work in Python. The hard part usually isn't choosing an algorithm. It's turning operational data into something a model can trust.
That's why good time series analysis in Python starts with discipline, not model shopping. Clean the dates. Make the index explicit. Check for gaps. Plot the series before you fit anything. Then compare a few model families with validation that respects time. That sequence sounds basic, but it's the difference between a notebook that looks smart and one that survives contact with production data.
Table of Contents
Setting Up Your Time Series Project in Python
A forecasting project gets unstable fast when the setup is sloppy. If your environment changes mid-project or your timestamp parsing depends on whatever defaults happen to work on your laptop, you'll spend more time debugging than modeling.
Start with a dataset that behaves like a time series
Use a dataset where each row represents an observation tied to a moment in time. Daily signups, hourly support tickets, weekly shipments, monthly recurring revenue snapshots. Python became a foundational language for this work because it combines flexible date handling with numerical and statistical tooling, and a common workflow is to load data with pandas, convert the timestamp column with to_datetime(), set it as the index, and then resample to a different cadence such as daily, weekly, or monthly, as described in this time series workflow overview from DASCA.
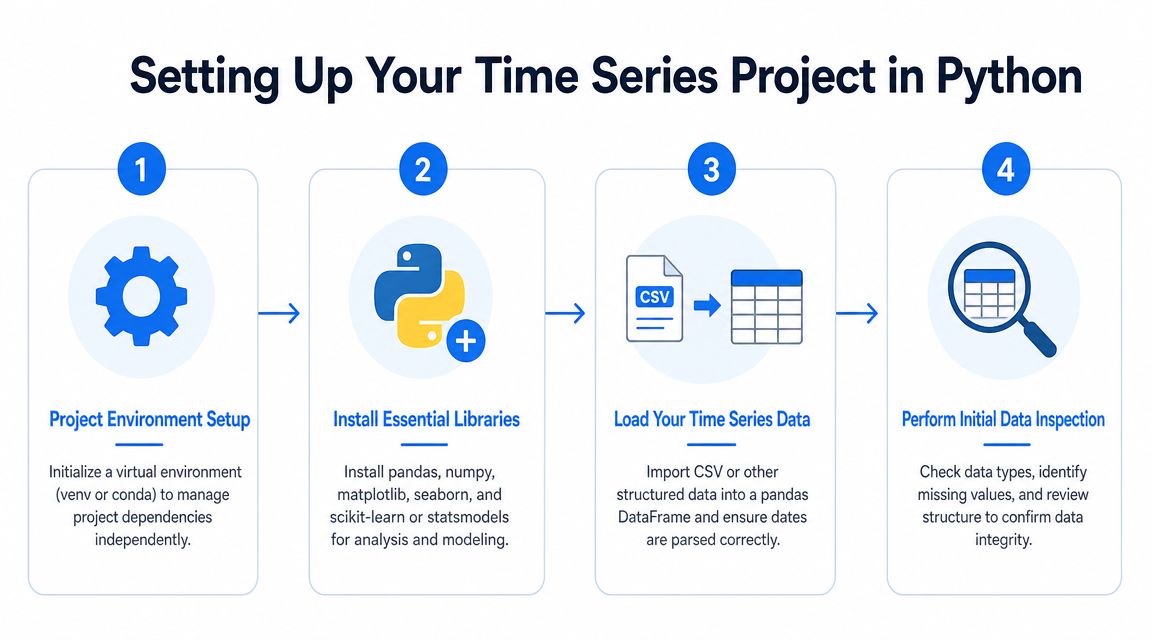
If you're working from a warehouse export, keep the first notebook boring on purpose. Load one metric. One timestamp column. One grain. Don't join five dimensions until the base series is reliable. Teams using reusable notebook workflows often benefit from a library of interactive notebook templates so setup doesn't become a custom exercise every time.
Install the tools you actually need
For most projects, this stack is enough:
pandas for indexing, slicing, resampling, and cleaning
numpy for numeric operations
matplotlib and seaborn for plotting
statsmodels for decomposition, ADF testing, exponential smoothing, ARIMA, and SARIMA
scikit-learn for preprocessing and evaluation helpers
Prophet for business-oriented forecasting with a simple interface
TensorFlow / Keras for LSTM experiments
A clean environment keeps version drift from breaking your notebook:
If TensorFlow is overkill for your use case, leave it out until you need it. A lot of teams install deep learning libraries too early, then spend effort resolving environment issues for a model they never deploy.
Make the datetime index non-negotiable
This is the step that enables the rest of time series analysis in Python.
Once the datetime index is in place, slicing becomes natural:
Practical rule: If the date column is still a plain object dtype after loading, you're not doing time series work yet. You're doing string processing.
That sounds obvious, but it's where many notebooks go wrong. People fit models against row order, not actual time. Then a missing day, duplicated timestamp, or timezone issue knocks the whole analysis off course.
Exploratory Data Analysis and Cleaning
Most business series are messy in ways textbook examples aren't. Missing weekends. Irregular extracts. Partial days. Outliers caused by a product launch, billing change, logging outage, or one broken ETL job. Cleaning isn't a prelude to the core work. It is the core work.
Find the gaps before you fill them
The main challenge in business forecasting is often not picking a fancier model, but making the series analytically usable by backfilling missing values, choosing time-aware validation, and testing for stationarity and seasonality before modeling. Many tutorials under-explain how to turn messy operational data into a high-quality forecasting dataset, which is exactly the problem highlighted in this practical Python time series repository.
Start by checking whether the timestamp frequency is what you think it is.
That reindexing step is useful because it makes absence explicit. Before that, you may not know whether a missing day is actually absent or merely missing from the file.
A lot of teams skip this and fit directly on observed rows. That works until you discover the model learned your extraction schedule instead of customer behavior. If your source data comes from multiple systems, a repeatable process for cleaning up data saves more forecast quality than another round of hyperparameter tuning.
Clean with methods that match the business process
Don't use one fill strategy for every gap. The right method depends on what the metric represents.
Use forward fill when the last known value still applies until updated. Use interpolation when values change gradually and missing points likely sit between known observations. Use rolling averages when the raw series is too noisy to inspect visually.
What usually goes wrong is not the method itself. It's applying it without asking what generated the data.
Weekend gaps: If your business is closed on weekends, a missing Saturday may be expected. Reindexing daily is still useful, but don't pretend those observations exist unless you have a business reason.
System outages: If tracking failed for a period, filling can hide a data quality incident. Keep a flag column for imputed periods.
Promotional spikes: Don't “clean” away real events. A one-day surge may be the signal you care about.
Keep two columns when imputing: the cleaned value and an
is_imputedflag. Future you will want both.
Plot for structure, not decoration
After cleaning, plot the raw and cleaned series together. That's where trend, seasonality, and suspicious behavior become visible.
Then add rolling statistics:
These plots answer simple but important questions:
Trend: Is the series drifting upward or downward?
Seasonality: Do the same patterns repeat weekly or monthly?
Variance stability: Does the noise level stay similar or expand over time?
Anomalies: Are there sudden spikes, dips, or flatlines that need explanation?
Plain line charts still beat fancy dashboards at this stage. You're trying to understand the data-generating process, not impress anyone.
Decomposition and Testing for Stationarity
Some models tolerate a lot of real-world mess. Classical models don't. They expect the series to behave in relatively stable ways over time. That's where stationarity and decomposition matter.
Stationarity is a modeling constraint, not a theory exercise
A stationary series behaves more like a river flowing within a usual range than one that keeps flooding new banks. Its mean, variance, and autocorrelation structure are more stable across time. That matters because many classical forecasting methods assume the process doesn't keep redefining itself.
One of the first analytical checks in Python time series workflows is stationarity and autocorrelation, because many forecasting methods depend on that stability. In practice, don't argue about the definition for twenty minutes. Test it, inspect it, and transform the series if needed.
Interpret the result conservatively. A low p-value supports the idea that the series is stationary. A higher p-value suggests it probably isn't. But don't let the test replace judgment. A product launch, pricing shift, or measurement change can make a series technically difficult and operationally obvious at the same time.
If the series isn't stationary, first differencing is the standard move:
Then re-run the ADF test on orders_diff.
If differencing makes the plot look like noise but your business clearly has weekly cycles, you may have removed useful structure and still need a seasonal treatment.
Run decomposition to separate signal from leftovers
Decomposition helps you split the observed series into trend, seasonality, and residuals. That's valuable even before modeling because it tells you what kinds of pattern are present.
Use an additive view when changes look like a relatively consistent amount over time. A multiplicative setup can be more appropriate when swings scale with the level of the series.
A decomposition plot gives you several fast reads:
Trend component: Is the baseline rising, falling, or changing in steps?
Seasonal component: Is there a reliable weekly or monthly pattern?
Residual component: What remains after accounting for systematic structure?
Residuals matter more than people think. If they still show obvious autocorrelation or repeating patterns, the decomposition has described the series but not fully explained it. That becomes important when you move into ARIMA or even modern models that still benefit from a clean signal.
Building Forecasting Models in Python
People often jump too early. By the time this stage is reached, the series should already be indexed correctly, cleaned thoughtfully, and inspected for trend and seasonality. Then model comparison becomes useful instead of random.
A quick model comparison
Model | Best For | Ease of Use | Interpretability |
|---|---|---|---|
ARIMA / SARIMA | Stable series with clear autocorrelation and seasonal structure | Moderate | High |
Prophet | Business series with trend and recurring seasonality | High | Moderate |
LSTM | More complex sequence patterns after simpler baselines underperform | Lower | Low |
That table looks simple, but the trade-offs are real. Start with the simplest model that matches the structure of the series. Deep learning isn't a badge of seriousness. It's a cost.
For teams expanding beyond pure univariate forecasting, time series regression analysis becomes useful when outside drivers matter, such as pricing, campaigns, or weather-like external covariates.
ARIMA and SARIMA when the series is structured and stable
ARIMA is still the right baseline more often than people admit. It works well when the series has a coherent autocorrelation pattern and doesn't require the model to infer every structure from scratch.
The parameter idea is straightforward:
p captures autoregressive lags
d captures differencing
q captures moving average behavior
For seasonal data, SARIMA adds seasonal counterparts.
Those plots help you choose lag structure, though in practice they're often rough guides rather than exact answers.
ARIMA and SARIMA are strong when you need a model you can inspect. You can reason about lag effects. You can inspect residuals. You can often explain to a stakeholder why the forecast moves the way it does. That matters.
What doesn't work well is forcing ARIMA onto a series with intermittent demand, irregular spacing, or abrupt structural breaks. In those cases, you spend all your time trying to rescue the assumptions.
Prophet when business seasonality matters more than manual tuning
Prophet became popular because it lowers the friction of getting a reasonable business forecast. It expects a dataframe with ds and y, and it handles trend and seasonality with less manual parameter work than classical approaches.
Prophet is useful when you want a practical model fast, especially for business metrics with recurring patterns. It's also friendlier for teams that don't want to hand-tune ACF and PACF interpretations.
Still, it's not magic. If the source data is badly gapped, irregular, or affected by shifting definitions, Prophet will give you a polished forecast built on shaky inputs. That's why the cleaning work earlier matters more than the library choice.
If you want a public example of how forecasting narratives can diverge across market conditions, this piece on Polytreasury's 2026 MATIC prediction is a useful reminder that volatile domains demand humility, regardless of model family.
LSTM when simpler baselines stop capturing the pattern
LSTMs are sequence models designed to learn from ordered observations. They can capture complex temporal behavior, but they require more preparation and they're much harder to interpret.
That makes them a poor first model and a good escalation path.
LSTMs can help when the series has nonlinear sequence behavior that simpler models keep missing. But they come with trade-offs:
More preprocessing: You need supervised sequence windows, scaling, and careful shape handling.
More tuning risk: Lookback windows, architecture choices, training stability, and overfitting all matter.
Lower interpretability: You'll know whether it predicts better. You often won't know why.
A good notebook compares all three categories on the same cleaned data and the same validation design. Don't let each model get its own custom split and then call it a fair test.
Evaluating Model Performance and Forecasts
Most bad forecasting notebooks fail here, not in model fitting. They use a random split, get flattering metrics, and accidentally test on the past and future mixed together. That's leakage.
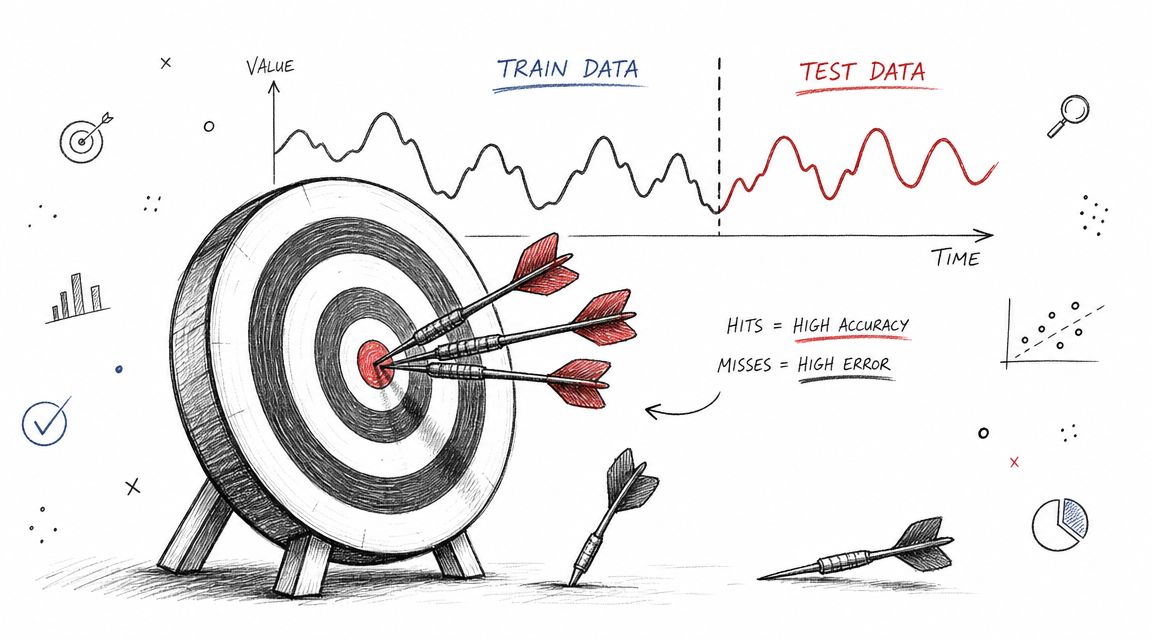
Why random splits fail
For model validation, expert practice in time series is to avoid random train/test splits and instead use rolling-origin or forward-chaining evaluation, where the training window moves forward through time and the test window always remains strictly in the future. This reduces leakage and better reflects deployment conditions, as emphasized in Aileen Nielsen's SciPy tutorial on time-aware validation.
A standard train_test_split shuffles observations unless you take special care. That destroys temporal order. Your model gets to learn patterns from later periods while pretending to forecast earlier ones. The resulting score may look clean and still be useless in production.
That simple chronological split is the minimum acceptable baseline.
Rolling validation in practice
A single holdout window can still mislead you if performance depends heavily on one recent period. Rolling validation is more reliable because it repeats the forecast task as the window moves forward.
This isn't glamorous, but it reflects what the actual job entails. You train on history available at that point, then predict the next unseen interval.
The easiest way to fake forecasting skill is to validate like a classification problem. The easiest way to lose trust is to deploy that result.
A short walkthrough can help if you want another visual explanation of forecast evaluation patterns:
Read the metrics with business context
MAE is often the most intuitive metric. It tells you the average absolute size of the error in the original units. RMSE penalizes larger misses more heavily, so it's useful when big forecast errors hurt more than small ones.
You can also calculate MAPE if the denominator is well-behaved and near-zero actual values won't distort the result. In many business series, that caveat matters.
Then plot predictions against actuals:
The plot often catches what metrics miss. Maybe the model gets the level right but lags turning points. Maybe it predicts smooth averages while the business needs spike detection. Maybe it fails only during promo periods, which are exactly the periods leadership cares about most.
Next Steps and Productionizing Your Model
A notebook forecast has limited value until someone can run it again next week without you babysitting it. Productionizing doesn't have to mean a full ML platform. For many teams, it starts with saving the model, scripting the refresh, and monitoring drift.
Save the artifact and the assumptions
Persist the trained object so you don't retrain every time someone opens the notebook.
Later:
Save more than the model. Save the preprocessing choices too. That includes the resampling cadence, fill strategy, differencing decision, feature transformations, and validation window. A forecast is only reproducible when the preparation logic is reproducible.
A small README beside the model file prevents a lot of confusion. “Daily data, reindexed to calendar days, forward-filled inventory state, weekly seasonal order.” That's the kind of detail people assume they'll remember and never do.
Automate forecasts with a small script first
Start with a plain Python script that runs on a schedule. Pull fresh data, apply the same preparation steps, load the saved model, generate a forecast, and write the output somewhere useful.
That may be enough for an internal planning workflow. If the output needs to reach more people, publish it into a dashboard or reporting layer. Tools for building dashboards in Python are useful once the forecasting pipeline itself is stable.
If your team works from warehouse data and wants notebook-based analysis without hand-building every query, Querio is one option. It uses AI coding agents on top of warehouse data and custom Python notebooks, which can fit workflows where analysts and operators both need inspectable forecast logic.
Use forecasting infrastructure for anomaly detection too
Production forecasting and anomaly detection are close relatives. A time-series course on exponential smoothing notes that the model can “quickly build anomaly detection systems” because it adapts to sharp structural changes and then forgets past deviations, which makes it a practical option for low-maintenance monitoring in business settings, as discussed in this exponential smoothing lesson from mlcourse.ai.
That idea is underused. Many teams don't need the most advanced forecast. They need a reliable expectation band and an alert when reality departs from it.
A lightweight pattern looks like this:
Generate expected values: Forecast the next horizon using a smoothing model or another simple baseline.
Compute residuals: Compare actual values to expected values as data arrives.
Set operational thresholds: Alert when residuals exceed a rule your team can act on.
Retrain periodically: Update the model when the baseline behavior has shifted.
This works well for traffic drops, signup spikes, revenue anomalies, or sudden seasonality changes. The maintenance burden stays low if the series is cleaned consistently and the threshold logic is understandable.
The biggest production mistake isn't choosing the wrong model family. It's letting the notebook remain a one-off artifact with undocumented assumptions. A modest, repeatable pipeline beats a brilliant analysis nobody can rerun.
Querio helps teams turn Python-based warehouse analysis into repeatable self-serve workflows instead of one-off notebooks. If you want analysts, product teams, and operators to work from the same live data with inspectable Python, take a look at Querio.

