Data Cleaning Service: Outsource vs. In-House Self-Serve
Should you hire a data cleaning service or empower your team with self-serve tools? A guide for data leaders comparing cost, ROI, and workflows for both models.
published
Outrank AI
data cleaning service, data quality, data governance, querio, self-serve analytics
b5ca62dd-018c-47c5-8377-a58c04e0da93

Your team probably isn't blocked by analysis. It's blocked by cleanup.
A product manager asks for a funnel breakdown. Finance wants a revenue reconciliation. Growth wants a retention cut by acquisition source. Instead of answering, your data team spends the day fixing duplicated accounts, patching missing values, standardizing fields, and explaining why two dashboards disagree. The team becomes a human API for the business.
That's the moment to stop treating a data cleaning service like a narrow procurement decision. This choice is more substantial. Are you buying temporary relief from bad data, or are you building the internal system that prevents the same mess from coming back?
Table of Contents
The Data Cleaning Bottleneck You Need to Solve
Bad data rarely announces itself as a strategy problem. It shows up as small annoyances. An analyst rewrites a join. A PM exports to CSV and fixes values by hand. Ops asks for “one more pass” before sharing numbers with leadership.
Then it becomes normal.
That's expensive because data cleaning is foundational work, not cosmetic work. IBM defines data cleaning, also called data cleansing or data scrubbing, as the process of identifying and correcting errors and inconsistencies in raw datasets so the data becomes accurate, complete, consistent, and usable for analysis or decisions. IBM also calls out common defects such as duplicates, missing values, syntax errors, irrelevant records, and structural issues in its overview of data cleaning fundamentals.
The deeper issue is that many teams treat cleaning as a downstream chore when the actual problem sits upstream. Domo's guidance highlights a familiar pattern: organizations keep repeating cleanup work even though the root cause may be schema drift or weak validation at ingestion, which creates rework and delayed reporting in the first place. That's the governance gap. You can read a more operational version of that challenge in this breakdown of what makes manually cleaning data challenging.
The strategic question
A data cleaning service can absolutely help. If you have a one-time mess, a migration, or a neglected CRM that needs triage, outsourcing may be the fastest route to a usable dataset.
But if your team cleans the same classes of issues every week, don't mistake repeated cleanup for a vendor-selection problem.
Practical rule: If the same defects keep coming back, you don't have a cleaning problem. You have a capture, modeling, or governance problem.
What leaders should focus on
You need to decide which of these describes your situation:
Emergency remediation: You inherited a broken dataset and need a fast cleanup.
Recurring operational drag: Analysts repeatedly fix the same issues before every report.
Capability gap: Business teams depend on specialists for basic data-quality work.
Governance failure: Inputs are inconsistent because no one owns validation rules upstream.
If you're in the second, third, or fourth category, outsourcing alone won't fix the business problem. It may even hide it.
Two Paths to Clean Data
There are two broad ways to approach a data cleaning service decision. Often, these are blurred together. They shouldn't.
External services
An external data cleaning service is exactly what it sounds like. You hand data to a third party, define the cleanup scope, and get back a corrected dataset or processed output.
That vendor may deduplicate records, standardize fields, normalize formats, remove bad values, or enrich records as part of the engagement. The work is useful. It can also be efficient when the task is bounded.
This model is similar to hiring a contractor to repaint a building. They finish the job. They don't redesign the maintenance system that caused the paint to peel.
In-warehouse self-serve cleaning
The alternative is to build cleaning logic where your data already lives and run it as part of normal operations. That means your team owns the rules, the schedules, the validation checks, and the outputs.
IBM's definition is helpful here because it clarifies what the work includes: fixing duplicates, missing values, syntax errors, and structural issues before analysis. If you want your team to stop repeating that work manually, you need infrastructure that makes those corrections systematic, not episodic. Companies exploring broader operating models often connect this to their wider stack decisions around data management services.
The real difference
This isn't just “vendor versus software.”
It's outsourcing a task versus owning a capability.
Service model: Someone else fixes your current dataset.
Self-serve model: Your team builds repeatable cleaning routines and runs them continuously.
Service model: Knowledge often stays with the vendor or in project documents.
Self-serve model: Knowledge lives in notebooks, workflows, tests, and warehouse logic.
Service model: Every new issue can trigger a new request.
Self-serve model: New issues become new rules in your operating system.
Clean data isn't the asset. A repeatable way to produce clean data is the asset.
That distinction matters because most companies don't suffer from one bad file. They suffer from ongoing operational inconsistency. If your business keeps adding sources, changing schemas, and launching products, a one-off cleanup won't keep pace.
Comparing the Models Head-to-Head
The table below is the practical version of the decision most leaders need to make.
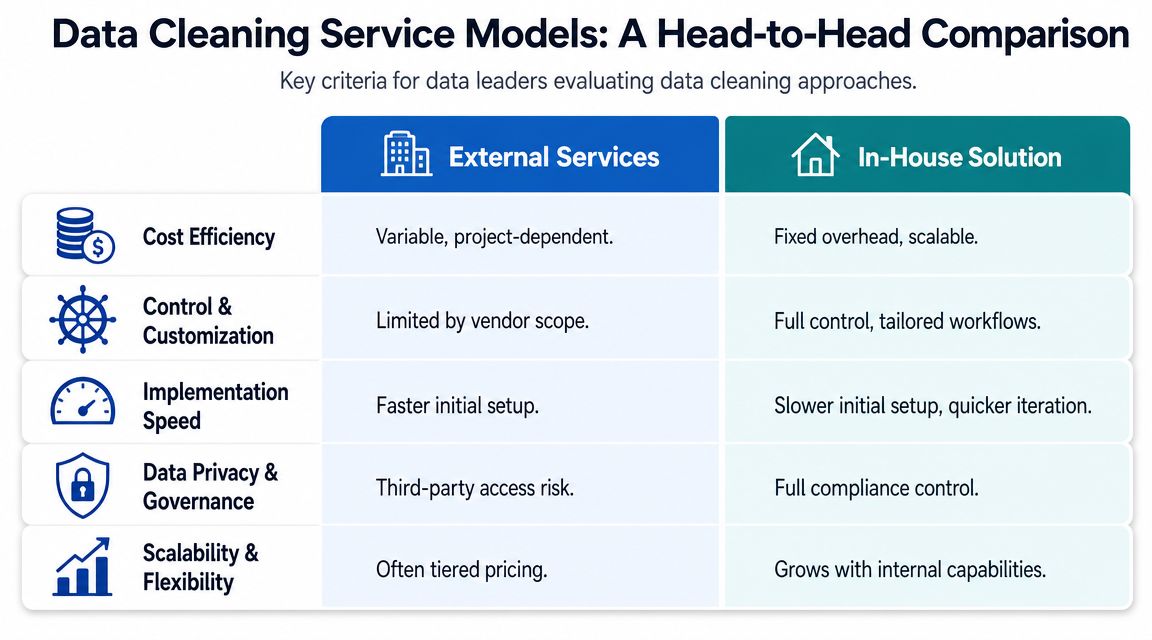
Quick comparison table
Criterion | External Data Cleaning Service | In-Warehouse Self-Serve (with Querio) |
|---|---|---|
Cost model | Variable. Usually tied to project scope, hours, or recurring service work. | More fixed and operational. You invest in tooling, workflows, and internal ownership. |
Speed and agility | Faster for one-off cleanups if scope is clear. Slower when requests, revisions, and approvals pile up. | Slower to stand up at first. Faster once rules and automations are in place. |
Scalability | Works for bounded projects. Gets cumbersome when many sources or repeated cycles are involved. | Improves as your team turns repeat work into reusable routines. |
Governance and security | Requires sharing data with a third party or granting outside access. | Keeps logic and sensitive data closer to the warehouse and internal controls. |
Customization | Limited by contract scope, vendor process, and turnaround model. | High. Teams can evolve rules with changing product, finance, or GTM needs. |
Team enablement | Can reduce internal workload in the short term, but often creates dependency. | Builds internal data literacy and reduces analyst gatekeeping over time. |
Knowledge retention | Logic may live in SOWs, vendor notes, or static deliverables. | Logic can live in versioned notebooks, shared workflows, and internal documentation. |
Best fit | One-time remediation, migration support, or narrow cleanup tasks. | Ongoing data-quality operations and organizations that want self-serve analytics. |
What the trade-offs look like in practice
The easiest mistake is to optimize for the first month instead of the next year.
Cost and predictability
External services look simple because they convert a messy internal problem into a purchase order. That's attractive when your team is overloaded.
But those costs tend to move with scope. More files, more defects, more review cycles, more money. Internal systems cost more attention upfront, but they usually age better because the same rule can run again without restarting procurement or vendor coordination.
Agility and business speed
A vendor can clean a dataset. A vendor usually can't sit inside every product launch, pricing change, and CRM process update that creates the next wave of defects.
Internal self-serve cleaning wins when the business changes often. Teams can update logic immediately instead of waiting for re-scoping. That matters when a product team adds a new event property, or finance reclassifies a revenue field, or sales starts writing values into a free-text field that should have been controlled.
The faster your business changes, the more expensive external dependency becomes.
Governance and security
Many teams stay too casual at this point.
If data includes customer, revenue, health, or employee information, any transfer to a third party introduces review work, access decisions, and governance overhead. Even when a vendor is responsible and compliant, you still own the decision to expose the data.
An in-warehouse approach doesn't remove governance obligations, but it usually gives your team tighter operational control because the cleaning happens closer to existing permissions, audit practices, and warehouse policies.
Team design and culture
Outsourcing can relieve pressure. It can also train the organization to escalate every data-quality issue outward or upward.
That's bad operating design. If business users need help for every recurring cleanup step, your analysts remain bottlenecks. If analysts own all quality fixes manually, engineers become the escalation layer behind them. Nobody gains an advantage.
An internal model is stronger when it creates shared ownership:
Analysts write or review reusable cleanup logic.
Data engineers handle core pipelines and upstream validation.
Product managers help define business rules and field meaning.
Ops teams adopt clearer input standards.
Where each model breaks
External services break when the work becomes continuous. Internal self-serve breaks when nobody owns standards, automation, or review.
That means the right answer isn't ideological. It's operational. If the problem is isolated, outsource it. If the problem is structural, build for it.
A Deep Dive into Cost Models and ROI
Most leaders underestimate the cost of recurring cleanup because they only look at the vendor invoice.
That's too narrow.

Why outsourced pricing gets slippery fast
A practitioner account from Datascopic reports a pricing pattern that should sound familiar to anyone who has bought cleanup help: dataset examination was charged at $150, cleansing at $90 per hour, and final bills ranged from $300 to well over $2,000 depending on the amount of data and the extent of the problems, as described in this review of the cost of data cleansing.
None of those figures are shocking on their own. The problem is repetition.
If the work returns every month, every quarter, or every time a new source lands, you're no longer buying a discrete project. You're funding a workaround. That's the tipping point where leaders should revisit the classic buy versus build trade-off with more discipline.
The hidden line items people miss
Vendor fees are only one layer. You also pay for:
Scoping time: Someone on your team has to explain field meanings, defect patterns, and expected outputs.
Review cycles: Cleaned data still needs validation against business logic.
Transfer overhead: Exports, permissions, secure handling, and re-import steps take real time.
Context loss: Vendors don't automatically know why a “bad” value might be legitimate in one workflow.
Recurring rework: If upstream issues stay untouched, the same defects return.
Datascopic makes this point clearly in qualitative terms. The cost isn't only the service fee. It also includes the operational cost of bad data and the process changes required to stop data from becoming dirty again.
How to think about ROI without fooling yourself
The right comparison isn't “service invoice versus software subscription.” It's temporary cleanup versus permanent capability.
Ask three blunt questions:
Is this a one-time remediation or a recurring operating need?
How much analyst time disappears into repeated cleanup work?
Will the same rules be needed again across new datasets or future reporting cycles?
If the answer to the second and third questions is “a lot,” internal infrastructure usually becomes the better financial decision, even if setup takes longer.
Operating principle: The moment your team can reuse cleaning logic across workflows, you've moved from project spend to capability investment.
ROI should include more than direct spend. Count the speed of delivery, the reduction in analyst interruption, and the drop in ad hoc manual fixes. Those are the gains that change team capacity.
Workflows and Implementation in Practice
The workflow difference between outsourcing and self-serve is where the strategy becomes obvious. One model creates a request queue. The other creates a repeatable system.
What outsourcing actually looks like day to day
An external data cleaning service usually follows a familiar pattern:
Define scope. Your team identifies the dataset, defects, expected rules, and deliverables.
Negotiate handling. Legal, procurement, and security may need to review the engagement.
Export data. Someone packages and transfers the relevant files or grants access.
Wait for processing. The vendor applies agreed logic.
Review output. Your team checks whether the cleaned result aligns with business reality.
Re-import and reconcile. Cleaned data gets loaded back into operational or analytical systems.
That sounds fine until the business changes halfway through. Then you add a new rule, reopen scope, and start another round of clarification.
The communication burden is a significant tax. Every ambiguity in source data becomes a back-and-forth thread. Every edge case needs human explanation. Every revision slows downstream reporting.
What an in-warehouse workflow looks like
A self-serve model looks different because it treats cleaning as part of normal operations.
A typical flow is simpler:
Connect to the warehouse. Work where governed data already exists.
Define cleaning rules in code. Use notebooks or transformations to standardize recurring fixes.
Schedule execution. Run routines on a cadence instead of waiting for a ticket.
Monitor outputs. Review dashboards or quality checks for regressions.
Refine rules. Update logic as source systems or business definitions evolve.
This model works because the cleaning logic stays close to the data and close to the people who understand the business context.
A simple notebook example
A lot of “internal capability” talk stays abstract. It doesn't need to.
Here's a lightweight Python example using pandas to deduplicate accounts and standardize a text field:
This isn't complicated. That's the point. Many recurring issues don't require a giant platform project. They require a place to write logic once, share it, schedule it, and improve it over time.
Implementation checklist for each path
If you outsource
Nail the business rules first: Don't send a vendor ambiguous field logic.
Limit scope: Keep the engagement tied to a bounded dataset or problem.
Define acceptance criteria: Agree on what “clean” means before work starts.
Plan re-entry: Decide how cleaned data returns to your systems and who validates it.
If you build internally
Start with repeat offenders: Pick the datasets that generate the most repeated cleanup work.
Version your logic: Treat cleaning rules like production assets, not one-off scripts.
Automate scheduling: Manual reruns recreate the same bottleneck in a new form.
Expose outputs clearly: Business teams need trusted, documented cleaned tables or views.
A team doesn't need perfect architecture on day one. It needs a workflow that reduces repetition.
Building Your Data Cleaning Strategy with Querio
If you've reached the point where recurring cleanup is slowing reporting, delaying decisions, and trapping analysts in low-impact work, the answer isn't another round of ad hoc fixes. It's a shift in operating model.
One practical route is to move the work into a collaborative, warehouse-centered environment. Querio fits that pattern by deploying AI coding agents directly on the warehouse and using Python notebooks as shared working assets, which lets teams build, run, and reuse cleaning logic without keeping all requests trapped with analysts. If you're assessing fit with your stack, the relevant place to start is Querio's integration options.
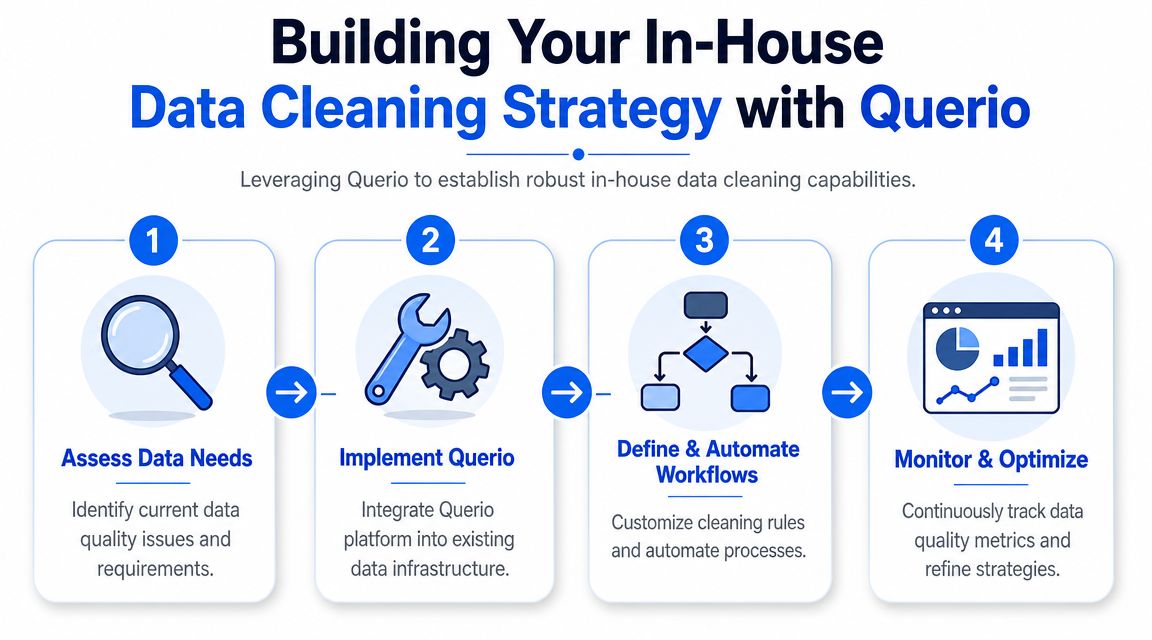
A practical migration path
Don't migrate everything at once. That's how teams create an internal tool mess instead of a reliable operating layer.
Use a phased approach:
Audit and prioritize
Identify the sources that create the most rework. Usually that means CRM tables, event streams, operational exports, or finance mappings that break repeatedly.Recreate the cleaning logic
Turn manual spreadsheet steps and vendor instructions into versioned notebook logic. The first win is visibility. Everyone can finally see what “cleanup” means.Automate recurring routines
Schedule the logic. Move from “run this when someone asks” to “this runs as part of the operating cadence.”Share and expand ownership
Let analysts, data engineers, and adjacent operators review and improve the routines instead of routing everything through one specialist.
What to operationalize first
Not every cleaning task deserves the same urgency. Start with work that is both frequent and costly in team interruption.
High-friction tables: Data that breaks dashboards or reporting every cycle.
Cross-functional dependencies: Inputs used by product, finance, and go-to-market at the same time.
Simple repeat logic: Standardization, deduplication, and controlled-value cleanup are often the best early candidates.
Visible trust problems: If leaders already question a metric because source data is inconsistent, fix that pipeline early.
A good internal cleaning strategy doesn't begin with sophistication. It begins with removing repeated human effort from the most painful workflows.
The strategic payoff is cultural as much as technical. Once cleaning logic becomes shared infrastructure, the data team stops being the emergency repair desk.
Decision Framework for Data and Product Leaders
Teams primarily seek a defensible decision, rather than a philosophical answer.

Questions that decide the right model
Use these questions to make the call.
Is the problem isolated or chronic?
A one-time CRM cleanup, migration, or backlog project is a reasonable use case for an external data cleaning service. A recurring weekly cleanup cycle is not.
Do you need speed now or advantage later?
If leadership needs one cleaned dataset quickly, outsourcing may be fine. If the business needs faster iteration across many changing questions, build internal capability.
How sensitive is the data?
The more sensitive the dataset, the stronger the case for minimizing external handling and keeping the work close to warehouse controls.
Are your rules stable or evolving?
Static cleanup jobs are easier to outsource. If business rules change often, internal ownership is usually safer and faster.
Do you want dependency or capability?
This is the blunt version. External services can reduce workload. They rarely increase internal analytical independence.
If you're hiring for data roles while making these decisions, it helps to align your interview process with the kind of operating model you want. These Professional Careers Training interview resources are useful for pressure-testing whether candidates can reason about data quality, workflow design, and business context rather than just write queries.
What success should look like
For an outsourced model, success usually means:
Fast remediation: The urgent dataset gets cleaned and returned on time.
Clear acceptance criteria: Stakeholders trust the corrected output.
Limited repeat work: The problem doesn't immediately recycle into a new request.
For an internal self-serve model, success looks different:
More automated rules: Repeated defects get handled by reusable logic.
Less analyst interruption: Fewer one-off cleanup requests hit the core team.
Faster time to trusted data: Business teams get clean inputs without waiting for heroics.
Better upstream discipline: Source owners start fixing capture problems, not just downstream mess.
The right answer is usually simple.
Choose an external data cleaning service when the problem is bounded, urgent, and unlikely to recur.
Choose an internal self-serve approach when cleanup has become part of your company's operating burden. At that point, buying more cleanup is just renting the same pain.
If your team is stuck acting like a human API instead of building durable data systems, take a look at Querio. It's designed for teams that want to keep work in the warehouse, use shared Python notebooks, and turn repeated analyst cleanup into self-serve infrastructure.

