Business Intelligence and Analytics: A Startup's Guide
A complete guide to business intelligence and analytics for startups. Learn to move from slow reports to fast, self-serve insights that drive growth.
https://www.youtube.com/watch?v=A1fYPeKxLaI
published
Outrank AI
business intelligence and analytics, self-serve analytics, data analytics, startup bi, data governance
c6ef3e7a-2077-4c18-a4d9-97aea86e24ec

Most advice on business intelligence and analytics starts in the wrong place. It starts with dashboards.
That sounds sensible until you live with the result. A founder asks, “Why did conversion drop after the pricing change?” A product manager asks, “Which activation step predicts retention?” A sales leader asks, “Which segment is slipping this month?” The data exists, but the answer still takes days because someone has to translate the request, write SQL, validate definitions, build a chart, and explain the output.
That isn't a reporting problem. It's an access problem.
Business intelligence has grown into a major market because companies now treat analytics as operating infrastructure, not a side function. One market projection values the BI industry at $34.82 billion in 2025, rising to $72.21 billion by 2034 at an 8.40% CAGR, while another projects growth from $37.96 billion in 2026 to $116.25 billion by 2033 at a 14.98% CAGR. The same market summary also notes that 65% of organizations are already using or exploring AI in analytics, and that global data volume is expected to reach 181 zettabytes in 2025. The exact forecast varies by scope, but the direction is clear in Fortune Business Insights' BI market outlook. Companies need faster decisions on top of much larger data estates.
The practical lesson for startups is simple. If every important question still routes through one analyst or one BI developer, you don't have a modern analytics function yet. You have a queue.
Table of Contents
Why 'More Dashboards' Won't Fix Your Data Problem
Most startup teams don't suffer from a lack of charts. They suffer from a lack of decision velocity.
A dashboard can tell you revenue is down, onboarding is stalling, or CAC is rising. It usually can't answer the next three questions that matter. Which cohort moved first? Was the change isolated to one channel? Did behavior shift after a release, a pricing test, or a sales motion change? That's where traditional business intelligence and analytics setups often break down.
The dashboard trap
Founders often hire an analyst or buy a BI tool and assume the problem is solved. For a while, that works. You get executive reporting, weekly KPI reviews, and a few clean charts for the board.
Then the business starts moving faster than the reporting layer.
Every new question becomes a request. Every request needs context. Every context change creates another dashboard, another filter set, or another metric definition. Soon the data team becomes a service desk for the whole company.
Practical rule: If a non-technical leader can't answer a follow-up question without opening a ticket, your BI setup is producing visibility, not leverage.
The issue isn't that dashboards are useless. They are useful for monitoring stable metrics. They fail when people need to explore, not just consume.
Why this hurts growing companies more
In an early-stage company, the cost of delay is high. Product decisions happen weekly. Pricing changes happen fast. Go-to-market experiments stack on top of each other. If insight arrives after the decision window closes, the analysis may still be correct, but it's no longer valuable.
That's why I push founders to think less about “What dashboards do we need?” and more about “Who can answer what, without waiting?” That shift changes tool choice, team design, and architecture.
A startup doesn't need fifty polished reports. It needs a reliable way for operators to move from question to answer without creating analyst bottlenecks. The popular dashboard-first playbook usually does the opposite, which is why this breakdown of why dashboard-first BI fails and how Querio fixes it resonates with so many data teams.
What works instead
A better model has three traits:
Governed data at the center: People explore trusted definitions, not spreadsheet exports and side calculations.
Direct access for business users: Product, sales, finance, and operations can ask real questions without waiting for hand-built reports.
Fast iteration on follow-ups: The second question matters as much as the first. Good systems support that naturally.
If you remember one thing, make it this: business intelligence and analytics should shorten the path from question to action. If your stack creates a line in front of the data team, adding more dashboards won't fix it.
Understanding Business Intelligence and Analytics
Business intelligence and analytics get lumped together because they sit on the same foundation. That's accurate, but it hides an important distinction. One helps you see the business clearly. The other helps you decide what to do next.
The simplest way to think about BI and analytics
A kitchen analogy works better than most definitions.
Business intelligence is observing the recipe. You track ingredients, timing, temperature, and output. You know what was cooked, what the result looked like, and where the process drifted. In business terms, this is your reporting layer. Revenue by segment. Pipeline by rep. Retention by cohort. Support volume by category.
Analytics is inventing new dishes. You ask why one recipe worked, what will happen if you swap an ingredient, and which variation should be tried next. In business terms, this moves beyond summary into explanation, forecasting, and recommendation.
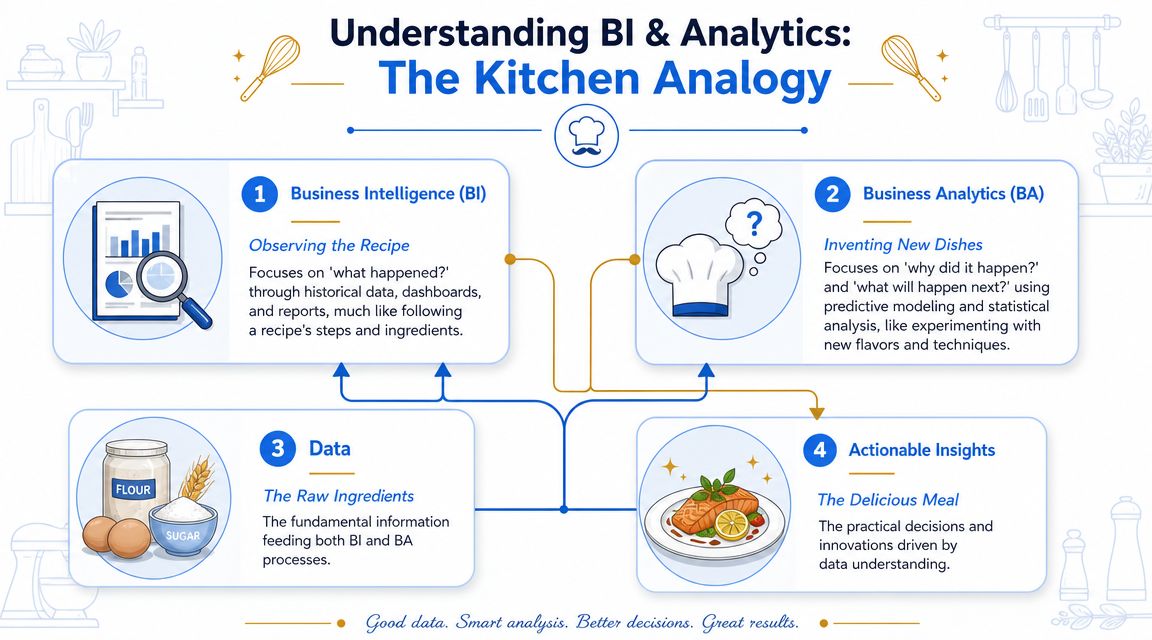
That distinction matters because many teams buy tools for one job and expect them to solve the other. A dashboarding layer is good at monitoring. It isn't automatically good at investigation.
What sits underneath the reports
The underlying architecture is less glamorous than the front-end charts, but it decides whether the system scales. Tableau's overview of BI describes a typical three-layer stack made up of data integration, a data warehouse, and a reporting/visualization layer. The same overview also frames the three main analysis modes in BI workflows as descriptive, predictive, and prescriptive analytics in Tableau's guide to business intelligence.
Here is the practical version of that model:
Data integration: You pull data from tools like Stripe, Salesforce, HubSpot, Postgres, product event streams, or support systems.
Warehouse: You centralize and model that data in Snowflake, BigQuery, Redshift, or Databricks so people aren't reconciling numbers across tools.
Access layer: Users consume metrics through dashboards, ad hoc queries, notebooks, or guided interfaces.
Good business intelligence and analytics starts with infrastructure, not visualization. Charts are the final mile.
The three analysis modes are also more useful when translated into operating language:
Descriptive analytics: What happened?
Predictive analytics: What is likely to happen?
Prescriptive analytics: What should we do?
A founder usually needs all three. The mistake is assuming one static reporting system will serve them equally well. It won't. Descriptive reporting can be standardized. Predictive and prescriptive work usually require exploration, iteration, and direct interaction with the data.
The Critical Difference Between BI and Analytics
Teams often use the terms interchangeably, but they solve different business problems. If you blur them together, you usually end up over-investing in reporting and under-investing in decision support.
What each discipline is for
Business intelligence is for operational visibility. It helps teams monitor the state of the business with stable definitions and recurring views. Leadership reviews, sales pacing, support backlog, margin tracking, and weekly product metrics all belong here.
Analytics is for investigation and intervention. It starts when someone asks a question that isn't already packaged. Why did a metric move? Which users are driving the shift? What pattern predicts expansion or churn? Which action should we test first?
The split matters even more because cloud BI adoption is already widespread. By late 2024, about 75% of businesses relied on cloud-based BI solutions, and organizations using real-time data analytics reduced decision-making time by an average of 30%, according to Kanerika's BI statistics review. The signal isn't just that BI tools are common. It's that businesses gain more when they move beyond static historical reporting toward faster analytical workflows.
Business Intelligence vs. Analytics at a Glance
Attribute | Business Intelligence (BI) | Analytics |
|---|---|---|
Primary question | What happened? | Why did it happen, what may happen next, and what should we do? |
Typical user | Executives, managers, operational teams | Analysts, product leaders, operators, finance, growth teams |
Usual output | Dashboards, recurring reports, KPI tracking | Exploratory queries, models, experiments, recommendations |
Best use case | Monitoring stable processes | Investigating change and guiding action |
Strength | Consistency and visibility | Depth and adaptability |
Common failure mode | Too many static dashboards | Work that stays trapped with specialists |
A useful test is this: if the answer can be reviewed every Monday in the same format, BI is probably the right mode. If the answer changes based on cohort, segment, time window, release date, or funnel path, you're in analytics territory.
Why startups need both, but not in equal measure
Early-stage teams often think they need a polished BI suite first. In reality, they need a lightweight reporting layer and a strong analytical workflow. The business is still changing too quickly for dozens of fixed assets to remain useful.
The smartest setup gives leadership consistent scoreboards while giving operators room to explore. That combination is what turns data from an executive mirror into an operating tool.
The Shift to Modern Self-Serve Analytics Architectures
Traditional BI architecture made sense when reporting cycles were slower and fewer people touched data directly. That world is gone. The warehouse became central, data volume increased, and business teams started expecting immediate answers.
A visual comparison makes the shift obvious.
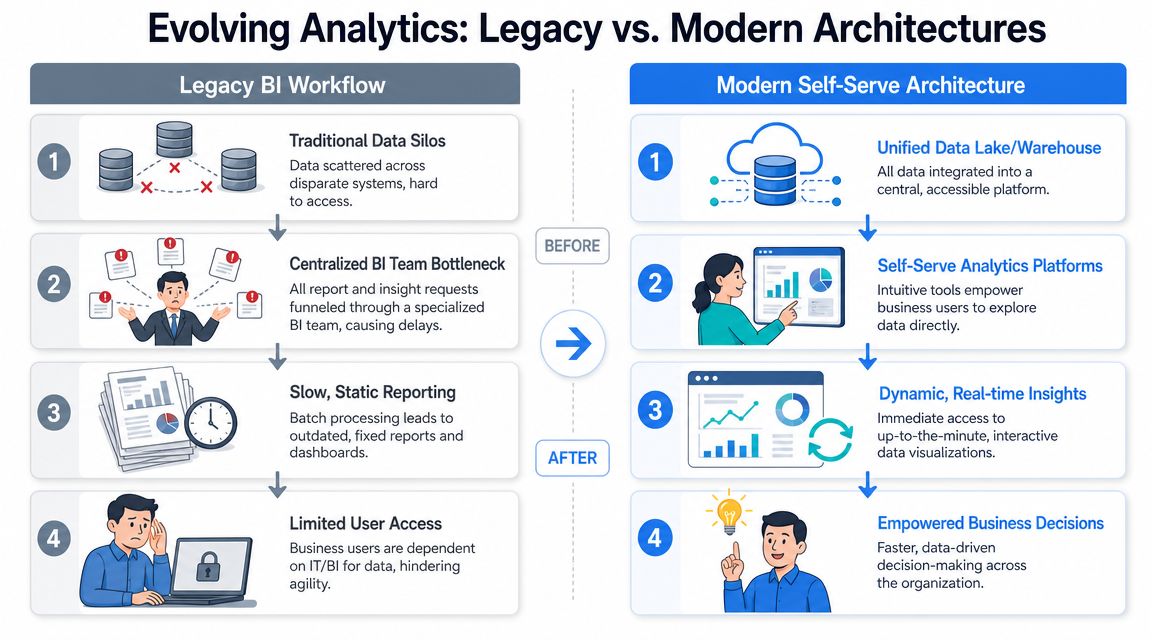
Why the old model keeps slowing teams down
The legacy model usually looks like this. Data lands in disconnected systems. Engineering or data teams move it into a warehouse. Analysts model it, validate it, and build reports. Business users open the finished dashboards and submit follow-up requests when the chart doesn't answer their real question.
That workflow creates a structural bottleneck. The analyst becomes the translator, query writer, metric explainer, and report maintainer all at once. Even when the team is strong, throughput stalls because the architecture depends on a small group of specialists to serve everyone else.
This is exactly why self-service analytics keeps rising on executive agendas. Improvado's trends report notes that self-service analytics is ranked among the top three priorities for organizations building data-driven cultures because it reduces analyst bottlenecks and speeds decision cycles. The same summary explains that augmented analytics uses AI to automate data preparation and insight discovery, which is why it has become a practical enabler of self-serve use rather than just a buzzword in Improvado's BI trends overview.
The failure mode in legacy BI isn't bad intent or weak analysts. It's a design that turns a high-skill team into a ticket queue.
A lot of founders misdiagnose this. They think they need another analyst. Often they need a different access pattern.
Later in the buying process, it's worth studying the components of the modern data stack because the bottleneck usually sits in the handoff between warehouse, semantic logic, and user access.
What the modern architecture changes
The modern approach keeps the warehouse as the source of truth but changes who can work from it. Instead of shipping everyone into a dashboard layer and hoping the right report exists, the system exposes governed data more directly through query interfaces, notebooks, AI-assisted exploration, and reusable business logic.
That has a few practical effects:
Business users get answers faster: They can ask a question and refine it without waiting for a report cycle.
Analysts spend less time on repetitive pulls: They focus on modeling, metric design, and higher-value analysis.
Definitions stay centralized: Teams still work from governed warehouse data instead of creating spreadsheet forks.
Exploration becomes normal: Follow-up questions stop being expensive.
This short demo gives a concrete view of how the newer workflow feels in practice.
The big change isn't visual polish. It's that the data team stops acting like a human API and starts maintaining a system other teams can use.
A Practical Implementation Roadmap for Startups
Startups rarely have a dashboard problem first. They have an access problem.
If every important question still routes through one analyst, adding charts just creates a nicer queue. The roadmap that works is the one that reduces handoffs early, keeps metric logic under control, and gives teams a way to answer routine questions themselves without breaking trust in the numbers.
Phase one and two
Start with decisions, not reporting requests. List the five to ten decisions that need better data this quarter. Keep them tied to operating choices, not vanity reporting. Which acquisition channels create activated accounts? Which onboarding steps predict expansion? Where does pipeline stall by segment? Those questions shape the model, the metric layer, and the access pattern.
Centralize the data before teams invent their own versions. For an early-stage startup, that usually means product events, billing, CRM, and marketing data in one warehouse. A plain, reliable foundation beats a polished reporting layer sitting on top of fragmented sources.
A few habits matter more than tool selection at this stage:
Assign an owner to each source. Someone should be responsible for whether Salesforce fields are maintained, Stripe data lands correctly, and product events still reflect real user behavior.
Model around business entities. Accounts, users, workspaces, subscriptions, invoices, and deals are easier for the company to work with than raw source tables.
Write metric names in business language. "Activated account" will survive. "pql_qualified_flag_v2" will not.
Decide what must be governed early. Revenue, pipeline, activation, and retention definitions should not drift team by team.
If you're at Series A and still light on data engineering support, this guide to setting up a BI tool before hiring a data engineer is a useful reference for keeping the first version simple enough to maintain.
Phase three and four
Choose the access layer based on who needs to ask follow-up questions. This is the step founders often get wrong. They buy for dashboard polish, then discover the cost later when every "can you break that down by segment?" request lands back with the data team.
The better test is practical. Can a product manager explore governed metrics without learning table names? Can a finance lead trace a number back to its definition? Can an analyst update business logic once instead of fixing it across twenty reports? If the answer is no, the bottleneck is still there.
Different roles need different interfaces. Analysts may stay in SQL or notebooks. Executives still want a stable weekly view. Operators and functional leads usually need something in between, where they can explore trusted data without touching raw schema complexity. Platforms such as Looker, Hex, and Querio take different approaches. Querio, specifically, connects to the warehouse and uses a file-system style notebook workflow with AI coding agents so technical and non-technical users can query and build analyses on governed data without routing every request through an analyst.
Buy for the second and third question, not the first screenshot.
Roll out usage inside real operating cadences. A self-serve layer only matters if teams use it in product reviews, sales forecasting, growth experiments, and customer success checks. If people still leave the meeting to ask analytics for a pull, the implementation is incomplete.
A rollout pattern I trust looks like this:
Start with one team that has recurring, high-value questions, usually product, revenue, or finance.
Publish shared metric definitions before broad access.
Train that team on how to explore and verify answers on its own.
Review decisions made from the system, not just login activity.
Expand to the next team only after the workflow is stable.
This sequence is less exciting than a company-wide launch. It works better. It keeps the analytics function focused on decision speed and data quality, while reducing the analyst bottleneck that traditional BI tends to create as the company grows.
Measuring Success with the Right Metrics and Governance
Most BI programs get measured with the wrong scoreboard. Leaders count dashboards, report views, and how many requests the data team closed. Those are activity metrics. They don't tell you whether the business intelligence and analytics function changed how the company operates.
Stop counting dashboards
The more useful question is whether insight gets converted into action. ThoughtSpot's guidance makes that point directly. It recommends evaluating BI with metrics like click-through rate and time-to-decision, and embedding analytics into workflow tools like Slack, Teams, CRM, and ERP systems instead of leaving them in standalone dashboards, as described in ThoughtSpot's business intelligence and analysis guide.
That lines up with what works in practice. If a sales manager sees a risk signal but still has to leave their workflow, find a dashboard, interpret it, and ask an analyst for context, the insight is too far from action.
I usually push teams to track a short set of operational measures:
Time to insight: How long does it take to move from question to trusted answer?
Time to decision: How long before that answer changes a meeting, a workflow, or a customer interaction?
Adoption outside the data team: Are product, finance, sales, and operations using the system themselves?
Decision coverage: Which recurring business decisions are consistently data-informed?
If you need a clean starting point for the language around metrics, this breakdown of understanding key performance indicators is a good companion resource.
Governance that enables self-serve use
Governance sounds heavy, but in startups it should be lightweight and strict in a few places only.
You need consistency around business logic. That usually means a semantic layer or shared metric definitions so “ARR,” “active customer,” or “qualified pipeline” doesn't change from one team to another. You also need ownership for source quality and a review process for changes that affect reporting.
What you don't need is to block access until everything is perfect. That creates the same bottleneck under a more respectable name.
Freedom without definitions creates chaos. Definitions without access create paralysis.
A strong self-serve setup gives users room to explore while protecting the core logic underneath. That's the balance. Governance should make data easier to trust, not harder to reach.
How Next-Gen Platforms Deliver Analytics Instantly
The future of business intelligence and analytics isn't another layer of static reporting. It's an access model where governed warehouse data becomes usable by far more people, much faster.

What changes when the warehouse becomes directly usable
A BI analyst's role has traditionally included producing standard and custom reports for executives and stakeholders. That's useful, but it also creates an operational gap. The analyst becomes the layer between governed warehouse data and everyone who needs answers. Systems that let users query the warehouse directly while preserving governance can materially increase analytics throughput, which is the central point in O*NET's BI analyst role summary.
That changes the experience of analytics in concrete ways:
Questions start closer to the decision-maker: A product manager can investigate feature adoption directly.
Follow-up analysis happens in the same flow: People don't stop at one chart.
The warehouse stays central: Data isn't copied into side systems just to become accessible.
Analysts move up the stack: They spend more time on modeling, semantic logic, and hard analytical work.
Next-gen platforms stand apart from older BI categories. The point isn't just to make charts easier to read. The point is to make governed analysis easier to perform.
How the data team's role shifts
In the older model, the data team produces answers. In the newer model, the data team produces capability.
That means building reliable models, defining metrics once, exposing safe interfaces, and letting the rest of the company work from them. AI-assisted interfaces, notebook workflows, and warehouse-native access patterns all matter because they reduce the translation cost between business question and technical query.
When that works, the company stops treating analytics as a separate reporting department. It starts using analytics as part of daily operations. That's the core shift.
If your team is overloaded with ad hoc requests and static dashboards aren't keeping up, Querio is one warehouse-native option to evaluate. It deploys AI coding agents directly on top of company data so teams can query, analyze, and build from governed warehouse data through a notebook-style workflow, without forcing every question through an analyst.

