Build a Modern Database Management Strategy for 2026
Build a robust database management strategy to scale your data team. Learn the core components, KPIs, and a roadmap for self-serve analytics implementation.
https://www.youtube.com/watch?v=ktnQb5yX93E
published
Outrank AI
database management, data strategy, self-serve analytics, data governance, querio
13d74c80-c07c-4883-a720-d390406fb6dc

Your team probably already feels the symptom. Product wants retention numbers before the roadmap review. Finance wants one version of revenue. Sales wants account health in the CRM and in the warehouse to match. Data gets pulled into every request, every clarification, every “can you just check one thing.”
That's not a reporting problem. It's a database management strategy problem.
When the foundation is weak, the data team becomes a routing layer for broken systems. When the foundation is solid, the same team can build governed self-service, support faster decisions, and focus more on strategic initiatives than cleanup.
Table of Contents
What Is a Database Management Strategy Really?
A database management strategy is the operating model for how your company handles data so people can use it safely, quickly, and consistently. It's not just a storage decision, and it's definitely not a DBA-only concern. It shapes how data gets modeled, where it lives, who can access it, how fast it performs, and whether the business trusts it enough to act.
The easiest way to explain it is urban planning.
A company without a database management strategy looks like a city that grew without zoning, roads, or building codes. Teams create tables wherever they want. The same customer exists in five systems. Access is handled through ad hoc requests. Performance degrades because nobody planned for growth. The city still functions, but movement is slow, expensive, and risky.
A company with a real strategy looks different. Governance acts like zoning. Security policies act like building codes. Performance optimization acts like roads and transit. Data quality acts like utilities people depend on every day. Self-serve analytics becomes the equivalent of public infrastructure. It gives more people safe access without requiring a specialist to escort them every time.
That matters because the economic backdrop is no longer small. The global big data market was valued at $307.5 billion and is projected to reach $924.4 billion by 2032, according to Acceldata's overview of data management strategy. If data infrastructure is becoming that central to business operations, strategy can't stay informal.
Strategy is about decisions, not databases alone
A good strategy answers a short list of uncomfortable questions:
Which system is authoritative for customers, products, orders, and billing
What data belongs in operational databases versus analytical stores
How access gets granted without creating a ticket queue
What standards define “good enough” data
What happens when systems disagree
Those decisions are more important than any single tool choice. Snowflake, BigQuery, PostgreSQL, Databricks, and dbt can all work in the right environment. They all create problems in the wrong one.
For teams sorting out storage choices, this breakdown of database vs data warehouse vs data lake is a useful framing device because architecture confusion often starts with using one system for jobs it wasn't built to do.
A mature strategy doesn't try to make one platform do everything. It assigns the right workload to the right layer.
What good strategy changes in practice
When the strategy is working, you can see it in behavior:
Area | Without strategy | With strategy |
|---|---|---|
Access | Slack requests and manual approvals | governed, repeatable access paths |
Reporting | conflicting dashboards | shared definitions and trusted sources |
Performance | slow queries and surprise cost spikes | predictable response times and tuned workloads |
Team capacity | analysts answer basic questions all day | analysts maintain systems and tackle higher-value work |
That is the core objective. A database management strategy doesn't exist to make the data stack look elegant. It exists so the business can move faster without breaking trust.
The Five Core Components of a Modern Data Strategy
Most companies don't fail because they ignored data entirely. They fail because they overinvested in one layer and neglected the rest. A modern database management strategy needs five components that work together. Remove one, and the whole system gets brittle.
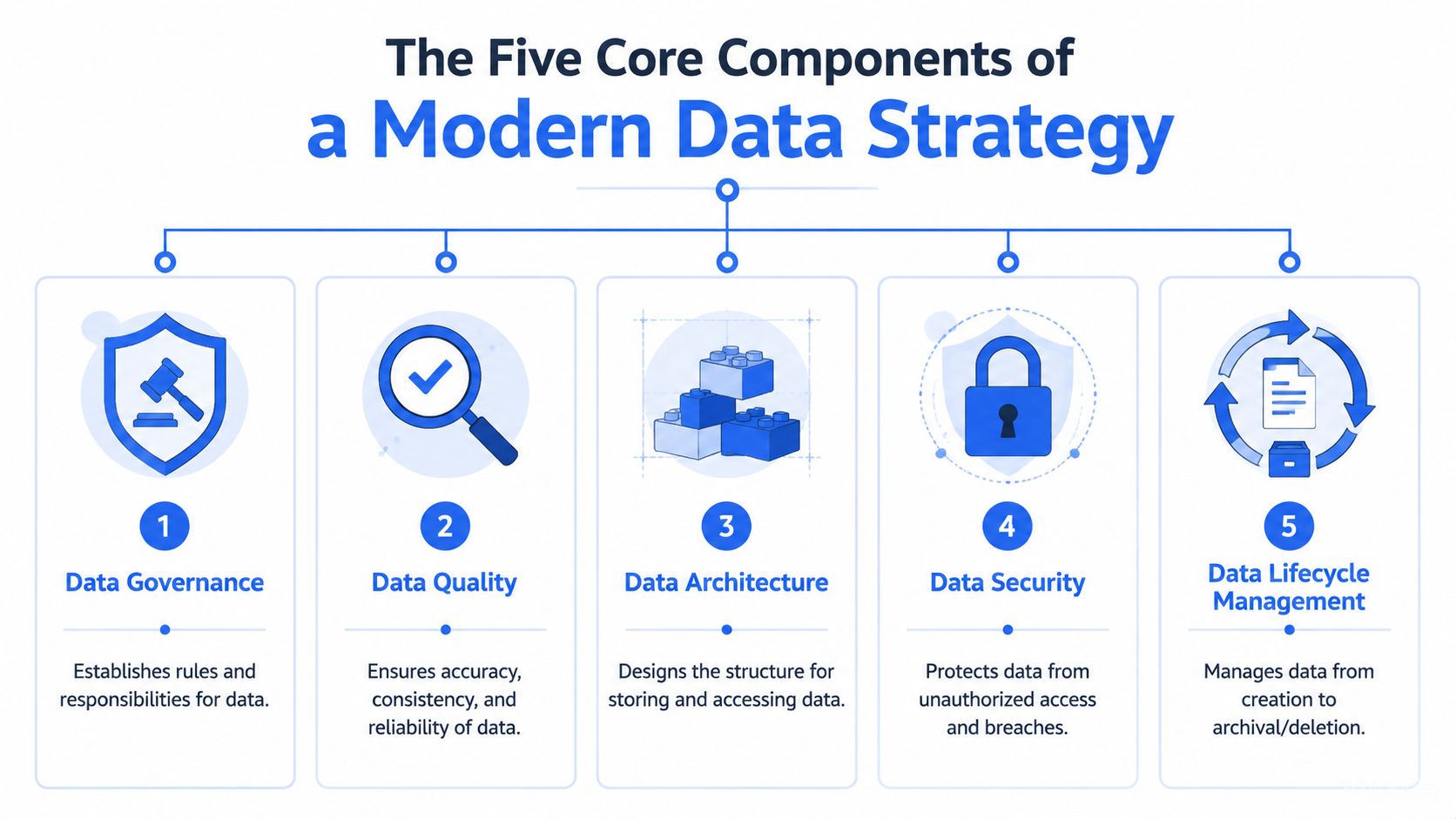
Teams building on a warehouse, transformation layer, and analytics interface usually run into the same lesson. The stack only feels modern when the operating rules are modern too. That's why a practical view of the modern data stack is more useful than another vendor diagram.
Governance defines who can trust what
Governance is where ownership gets explicit. Somebody owns customer definitions. Somebody approves schema changes for core models. Somebody decides whether a metric is production-grade or exploratory.
What doesn't work is “shared responsibility” with no actual decision-maker. That leads to duplicate metrics, undocumented logic, and executive meetings spent debating which dashboard is right.
A lightweight governance model should cover:
Data ownership for key domains like customer, product, billing, and usage
Definition control for company metrics
Change management for schema updates and breaking transformations
Documentation standards for business-facing datasets
Security and compliance must support access, not block it
Security often gets implemented as a wall. It should behave more like controlled routing. The business needs broad discovery and narrow permissioning. Analysts and operators need enough access to answer legitimate questions without exposing sensitive fields unnecessarily.
That means role-based access, environment separation, auditability, and clear policies for privileged workflows. It also means refusing the common anti-pattern where a handful of engineers hold direct credentials to everything while everyone else waits in line.
Practical rule: if your access model makes safe work harder than unsafe work, people will route around it.
Performance is a product feature
If queries are slow, people stop trusting the system. They export data locally, rebuild logic in spreadsheets, and create shadow reporting. At that point, the problem isn't only technical. You've trained the company that the official path is unreliable.
Performance work usually starts with the obvious but frequently postponed tasks:
Indexing hot paths in transactional systems
Partitioning large analytical tables by useful keys
Materializing common aggregations
Separating operational workloads from heavy analytics
Architecture determines how much pain you postpone
Architecture is where trade-offs become visible. Relational databases like PostgreSQL are excellent for transactional consistency. Warehouses like Snowflake and BigQuery are built for analytical scale. Lakehouse patterns can help when your data types and compute patterns are broader. Problems start when leaders delay those distinctions because “it works for now.”
A healthy architecture plan answers three things clearly:
Decision area | Good question |
|---|---|
Storage | Where should raw, curated, and serving data live? |
Compute | Which workloads need low-latency transactions versus analytical scans? |
Interfaces | How will business users query safely without direct dependence on engineering? |
Data quality and MDM create operational trust
Data quality isn't just validation rules. It's the discipline of making sure business entities mean the same thing across systems. That's where Master Data Management, or MDM, matters.
Companies deploying MDM software achieve up to a 20% increase in data accuracy, a 15% improvement in organizational efficiency, and an average 10% reduction in operational costs after adoption, according to Semarchy's MDM statistics roundup. That lines up with what experienced teams see on the ground. Once customer, product, and account records stop drifting across systems, reporting debates shrink fast.
What works:
Choosing a few master entities first, not trying to govern everything at once
Matching records centrally, then publishing clean reference data outward
Making quality visible through monitored checks and ownership
What doesn't:
Treating quality as a cleanup sprint
Letting every team define “customer” independently
Assuming warehouse centralization alone fixes semantic inconsistency
A modern strategy is stable when these five components reinforce each other. Governance without performance creates frustration. Performance without quality creates fast wrong answers. Architecture without security creates exposure. The goal isn't perfection. It's coherence.
Setting Objectives and Measurable KPIs
Most database programs drift because the stated goal is too technical. “Improve data infrastructure” isn't a target. Neither is “modernize the stack.” Teams need objectives tied to business motion.
If product managers wait days for engagement numbers, your objective isn't faster SQL. It's shorter time-to-insight for product decisions. If finance reconciles revenue in multiple places, your objective isn't better modeling in the abstract. It's a single trusted path to the number used in planning.
Translate technical work into business outcomes
Good objectives connect infrastructure changes to operating outcomes. They also force trade-offs. You can't optimize every workflow at once, so the best roadmap starts with the business processes that break most often.
A useful pattern is to rewrite technical initiatives in business language:
Instead of query optimization, use faster access to operational dashboards
Instead of schema cleanup, use fewer conflicting definitions in executive reviews
Instead of access redesign, use less waiting for approved analysis
Instead of MDM rollout, use consistent customer and product reporting across functions
The framing of a roadmap often determines whether data leaders gain or lose executive support. If the roadmap sounds like tooling work, it gets deprioritized. If it sounds like decision velocity, planning accuracy, and team capacity, it gets funded.
For teams that need a simple model for KPI design, this guide to measuring key performance indicators is a practical complement to the infrastructure side.
Choose KPIs that change behavior
The best KPIs are hard to game and easy to review. They should tell you whether the strategy is improving trust, speed, and adoption.
A strong scorecard usually includes a mix like this:
KPI | What it tells you |
|---|---|
Data accuracy rate | whether trusted datasets are actually reliable |
Query latency | whether users can explore without friction |
System uptime | whether data access is dependable |
Access request turnaround | whether governance is enabling work or blocking it |
Self-service adoption rate | whether the business is using the system directly |
Number of duplicate metric definitions | whether governance is reducing reporting drift |
Some of these are technical. Some are operational. That's the point.
Track the handoff cost between teams. It often reveals more about your database management strategy than infrastructure metrics alone.
A few cautions matter here:
Don't overload the dashboard. A short KPI set creates accountability.
Don't measure only platform health. The business outcome matters more than the cluster status.
Don't define KPIs without owners. Every metric needs someone responsible for movement, not just reporting.
The strategy is working when the same KPI set matters to engineering, analytics, product, and leadership. That alignment is what turns database management from backend maintenance into business infrastructure.
Your 5-Phase Implementation Roadmap
A database management strategy becomes real when it turns into sequencing. Many organizations already know some part of what's broken. The harder question is what to fix first, what to leave alone, and how to avoid rebuilding the same mess in a shinier stack.
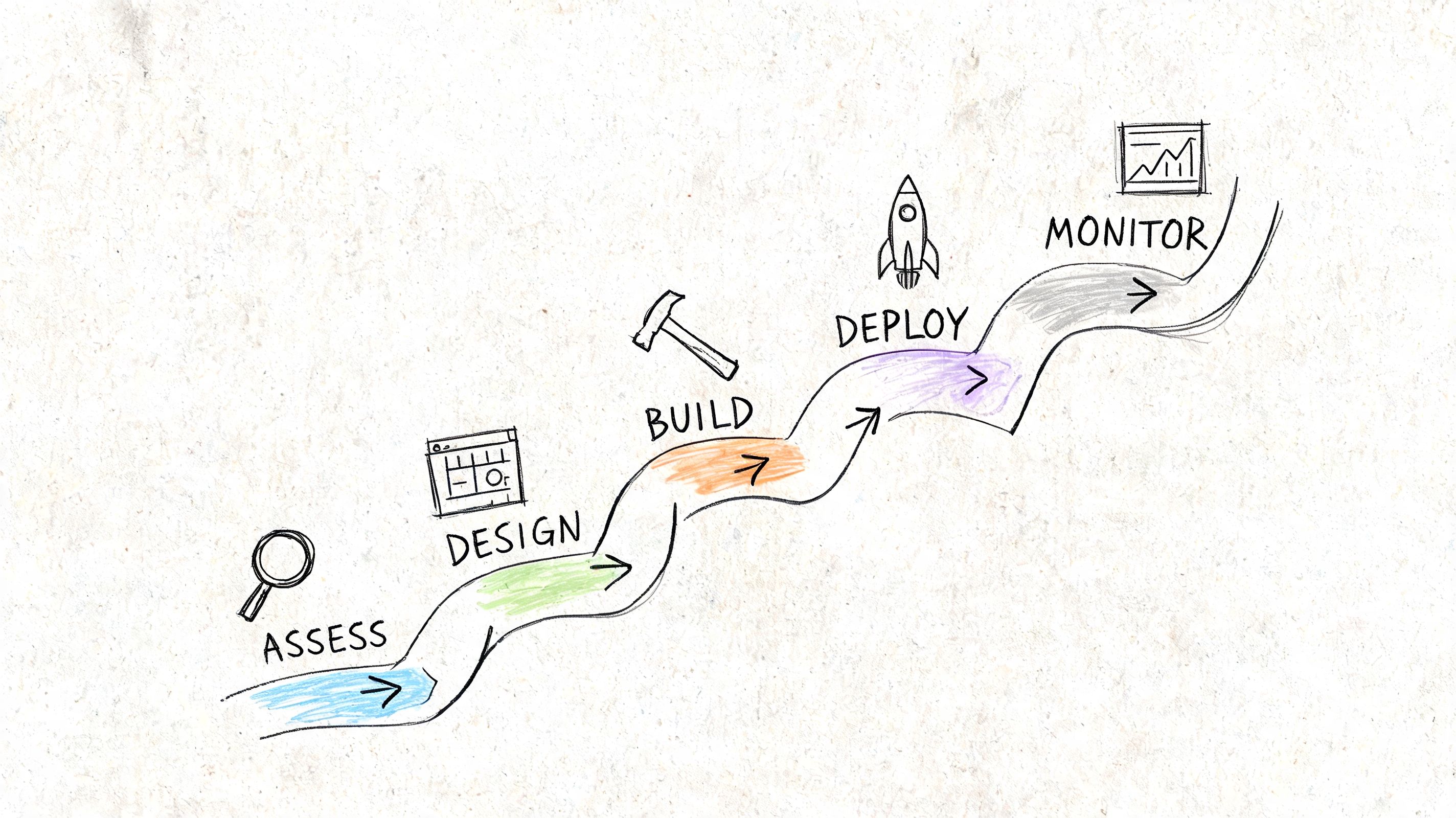
Phase 1 assessment and discovery
Start by mapping reality, not aspirations. Inventory your databases, warehouse tables, pipelines, dashboards, permissions, and critical business entities. Then identify which assets are trusted, which are merely tolerated, and which no one should be using but everyone still does.
This phase is also where access pain becomes visible. The permission creep problem is one of the most common implementation gaps. Analytics teams need legitimate access across multiple databases, but traditional credential management creates bottlenecks, as described in StrongDM's discussion of database access challenges.
Look for these signals:
Orphaned permissions that nobody can justify
Core reports with unclear lineage
Critical tables with multiple unofficial copies
Business requests blocked by credential provisioning
Phase 2 strategic design
Once you know the current state, define the target operating model. Many teams get distracted by vendor evaluation too early in this phase. Design first.
Write down the future-state answers to a few concrete questions:
Design question | Decision to make |
|---|---|
Source of truth | Which system owns each critical entity? |
Access model | How will users discover and query data safely? |
Data contracts | What changes require review before deployment? |
Serving layer | Which datasets are approved for broad business use? |
This is also where startup operators should align data work with company planning. If you need a founder-friendly way to connect data priorities to business tracking, this overview of strategies for startup KPI success is a useful companion.
Phase 3 tooling and implementation
Tooling should support the operating model you chose, not compensate for the absence of one. In practice, that means selecting systems that fit the workload.
A typical pattern looks like this:
Transactional databases for application operations
A warehouse or analytical engine for cross-functional reporting
Transformation workflows for curated business logic
A governed access layer for analysts and business users
Metadata and documentation tooling so people can find trusted assets
What usually fails is trying to preserve every historical exception. Standardize the common path. Leave edge cases for later.
Phase 4 optimization and automation
Once the core path exists, tune it. Remove manual checks that happen every week. Automate quality validation. Add workload isolation where noisy jobs degrade shared performance. Clean up permission inheritance before it becomes impossible to reason about.
A practical walkthrough helps here:
Optimization should target recurring pain, not theoretical elegance. If one monthly board report causes repeated rework, automate that path first. If one pipeline creates downstream confusion, make its lineage and tests explicit before tuning lower-value jobs.
The fastest way to lose momentum is to spend a quarter polishing architecture while the company still can't answer routine questions reliably.
Phase 5 ongoing governance and evolution
Mature teams separate themselves in this area. They stop treating database management as a one-off migration and start running it as an operating discipline.
The cadence matters:
Review core metric definitions on a schedule
Audit access patterns before privileges sprawl again
Retire stale assets so discoverability doesn't collapse
Revisit architecture choices when team size, product complexity, or data volume changes
If you skip this phase, the system slowly drifts back toward informal workarounds. The implementation roadmap succeeds when governance becomes normal operations, not a rescue project.
Best Practices and Common Pitfalls to Avoid
The fastest way to spot an immature database management strategy is simple. Everyone says data is important, but nobody can explain who owns the hard decisions.
Most failures aren't dramatic. They come from slow accumulation. A permission model that made sense six months ago becomes incoherent. A dashboard built for one team becomes de facto company reporting. A warehouse fills with useful but undocumented assets until discoverability collapses.
Do this instead of that
A practical database management strategy is mostly disciplined repetition. The basics matter more than cleverness.
Automate performance hygiene early. Indexing, partitioning, and materialized summaries shouldn't wait until users complain at scale. ThoughtSpot notes that implementing performance indexing and partitioning can reduce query retrieval times by up to 90%, and using B-tree indexes on high-cardinality columns with materialized views can achieve 5-10x throughput gains in production environments, as outlined in its data management best practices guide.
Define governed datasets before broad rollout. If business users get direct access to raw, unstable models, they'll build on top of shifting ground.
Train users during implementation. Good systems still fail when teams don't understand where trusted data lives or what each field means.
Design for failure paths. Pipelines break, upstream schemas change, and permissions drift. Build alerting and ownership around those realities.
Where teams usually get stuck
The common pitfalls are boring, which is why they're dangerous.
Best practice | Common pitfall |
|---|---|
Define strategy before buying tools | buying platforms first, then forcing the org to fit them |
Treat quality as a product | fixing data only when executives notice a discrepancy |
Keep access governed but usable | making secure access so slow that teams export data offline |
Review lineage and ownership regularly | assuming once-documented means permanently understood |
Another useful external perspective is this roundup of database management best practices, especially for leaders who want a cross-check against their current operating model.
One more issue deserves emphasis. Teams often optimize the warehouse and ignore the user experience around it. If discoverability, documentation, and permissioning are weak, strong infrastructure won't produce self-service. It will just produce a technically impressive bottleneck.
Good database management is visible in fewer interruptions, fewer reconciliation debates, and fewer “who has access?” messages.
From Strategy to Self-Serve Analytics Platforms
Self-serve analytics is often presented as a tooling purchase. In practice, it's the result of a strong database management strategy. Without that foundation, self-service becomes a faster way to spread confusion.
A non-technical user doesn't care whether your problem is schema drift, duplicate entities, or poorly modeled joins. They care whether they can ask a question and trust the answer. If the system is inconsistent, slow, or permission-gated in unpredictable ways, they stop using it. Then the data team becomes the fallback interface again.
Why self-service fails without strategy
Most self-service rollouts break in one of three places:
Trust fails. Users see different answers for the same question.
Access fails. People can discover data but can't use it without a specialist.
Performance fails. Exploration is so slow that users abandon the workflow.
That's why strategy matters first. Governance tells users what's official. Architecture ensures analytical workloads run in the right place. Performance work keeps interaction responsive. Quality controls prevent “customer” from meaning five different things depending on source system.
For leaders evaluating the business side of this shift, this guide to self-serve business intelligence is a useful complement.
What changes when the foundation is right
When the underlying strategy is solid, self-service changes the role of the data team. Analysts stop spending most of their week answering repetitive requests. They define semantic layers, maintain trusted data products, improve quality checks, and build reusable workflows.
Warehouse-native MDM is especially important here. According to RudderStack's data management strategy article, it can reduce data inconsistency errors by 80-95% and enable 3x higher self-service adoption by eliminating “human API” delays and giving users a single source of truth. That's the operational bridge between classic data management discipline and modern analytics usability.
The strongest self-serve environments usually share a few traits:
Capability | What users experience |
|---|---|
Trusted semantic definitions | fewer arguments over metric meaning |
Governed access paths | less waiting for manual approvals |
Responsive analytical workloads | faster iteration during exploration |
Clear ownership and lineage | more confidence in what's safe to use |
The business benefit is straightforward. Product moves faster because questions don't queue behind analysts. Executives spend less time reconciling reports. Data leaders can invest in systems, not endless request handling.
That's the payoff of a real database management strategy. You're not just storing data better. You're changing how the company operates.
If your team is stuck acting as a human API, Querio helps shift the model. It deploys AI coding agents directly on your data warehouse so technical and non-technical users can query, analyze, and build on company data through governed, flexible workflows. The result is a self-service environment where the data team maintains infrastructure instead of manually answering every question.

