Nested SQL Select: A Practical Performance Guide
Master the nested SQL select. Learn to write, debug, and optimize subqueries for performance on modern data warehouses like Snowflake, BigQuery, and Redshift.
https://www.youtube.com/watch?v=ZaFMM-vNlvc
published
Outrank AI
nested sql select, sql subquery, sql optimization, data analytics
a2c5a5d2-3df3-4f67-8fb6-e840efd40bda

A lot of analysts meet the nested sql select at the exact moment their questions stop being simple. You’re not just pulling a table anymore. You’re trying to find users who adopted one workflow but not another, products that outperform their category average, or accounts that match one behavior while avoiding another. A flat query stops being enough.
That’s where nested SELECT statements earn their place. They let you ask SQL in layers. One query produces an intermediate answer, and another query uses that answer to finish the job. The pattern is old, standard, and still useful.
It’s also one of the easiest ways to create warehouse pain. A subquery can be clean and fast, or it can turn into the kind of logic nobody wants to debug on a Friday afternoon. In a self-service analytics environment, that difference matters even more because someone else will inherit your query. Often someone with less SQL context than you.
Table of Contents
Answering Complex Questions with Nested SQL
A stakeholder asks a question that sounds simple: which users finished onboarding, skipped the new feature, and still renewed last month? That is not one filter. It is a chain of conditions, and at least one step usually depends on the result of another.
That is where nested queries earn their keep in day-to-day analytics work. A product manager might need users who completed onboarding but have not used a feature. An analyst might need products with sales above their category average. A finance lead might need customers whose latest order clears a threshold derived from a separate slice of the same dataset. Each case has an intermediate answer that feeds the final one.
A nested SQL select fits that pattern well. The inner query produces a value, a set of values, or a temporary relation. The outer query uses that result to filter, compare, or reshape the final output. SQL supports that pattern in several places, which is why subqueries show up in both quick analysis and production models.
Practical rule: Use a nested select when the logic is genuinely two-step and the query still reads clearly from top to bottom.
Readability is the definitive test. I use nested selects for focused filters and one-off comparisons. I stop using them when they start stacking business logic in a way that hides intent. On modern warehouses, the harder question is not whether a subquery is valid SQL. It is whether the next analyst can debug it, extend it, and trust the result without tracing three layers of parentheses.
That distinction matters because SQL gets reused by many people. In a self-service environment, one nested query can end up copied into a dashboard, a notebook, a reverse ETL sync, and a KPI definition. If the subquery expresses a clean idea, that reuse is fine. If it creates repeated scans, row-by-row evaluation, or tangled logic, refactor early into a CTE, JOIN, or window function.
What Is a Nested SQL Select
A nested SQL select, usually called a subquery, is a SELECT statement written inside another SQL statement. It lets one query produce an intermediate result that another part of the same query can use immediately.
That sounds simple, but its fundamental value is strategic. Nested selects are useful when the question is naturally two-step and the SQL stays readable. They become a problem when analysts start burying business logic inside layers of parentheses that are harder to test, review, and reuse.
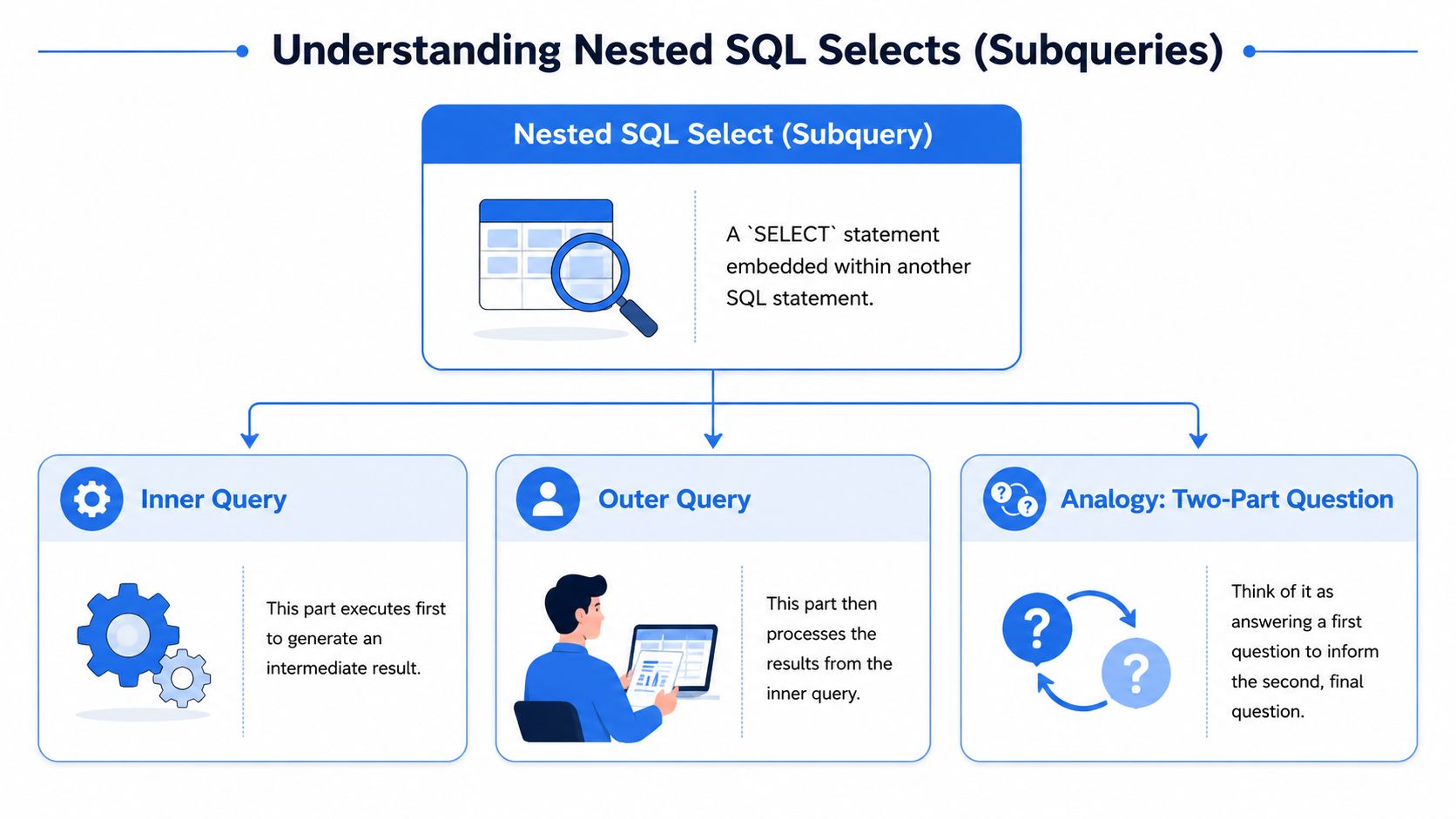
The basic mental model
Suppose you want to find employees whose sales are above the overall average sales value.
The inner query returns one value: the average sales. The outer query compares each employee’s sales to that value. That makes this a scalar subquery.
This pattern keeps the logic close to the question. You do not need a separate temp table or a second manual step just to compute the benchmark first.
A subquery acts as a temporary result, not a permanent object.
Where subqueries can live
Subqueries can appear in several parts of a SQL statement, and the placement changes how they behave.
Inside WHERE for filtering:
This is common for membership tests. In production code, I often rewrite patterns like this into an INNER JOIN for filtering related records if the join version is easier for the team to read and maintain.
Inside FROM as a derived table:
This approach creates an intermediate dataset and then queries it. It works well for one-off analysis, but if that intermediate step carries business meaning, a named CTE is often easier to review later.
Inside SELECT as a scalar value:
This adds context to each row without changing the row set. It can be handy, but it is also one of the first places I check when a query feels repetitive or harder than necessary to optimize.
Each placement solves a different problem. WHERE subqueries usually filter. FROM subqueries shape an intermediate relation. SELECT subqueries attach a value to each output row.
Subqueries are part of standard SQL and every analyst should know how to read them. The harder skill is deciding when to stop using them. In a self-service analytics environment, syntax is rarely the limiting factor. Clear intent, predictable performance, and code that another analyst can safely modify matter more.
Correlated vs Non-Correlated Subqueries
This is the distinction that separates a harmless query from a warehouse problem.
A lot of teams treat every subquery as roughly the same thing. They aren’t. The core split is between non-correlated and correlated subqueries, and the performance difference can be dramatic.
Non-correlated subqueries
A non-correlated subquery stands on its own. You can run it independently, get a result, and then feed that result into the outer query.
Example:
The inner query doesn’t depend on any row from the outer query. It calculates one number, once. Then the outer query compares each row against that number.
This is the safer kind of subquery. It’s easy to reason about, often easy for the optimizer to rewrite, and usually acceptable for ad hoc work if it stays readable.
Correlated subqueries
A correlated subquery depends on values from the outer query. That means the inner query is tied to each outer row.
Example:
Now the inner query refers to e.department from the outer query. The database has to evaluate the average salary for the relevant department in relation to the current outer row.
That’s where things get expensive. The difference between correlated subqueries executing once per outer row and non-correlated subqueries executing once total can create 100x+ performance differences on large datasets, according to ThoughtSpot’s SQL subquery tutorial. That’s not a theoretical detail. It’s one of the first things I look for when a query feels unexpectedly slow.
If a query reads like “for each row, go look something up again,” assume it needs scrutiny.
Correlated subqueries are not always wrong. Sometimes they express intent clearly, especially with EXISTS. But they deserve suspicion in production analytics, especially when the outer table is large.
If your real goal is matching records across tables, a JOIN is often clearer. If you need a refresher on join behavior, this guide to inner join SQL patterns is a useful comparison point because many subqueries are really joins in disguise.
Correlated vs. Non-Correlated Subqueries
Aspect | Non-Correlated Subquery | Correlated Subquery |
|---|---|---|
Dependency | Independent of outer query | Depends on outer query values |
Execution pattern | Runs once | Runs in relation to outer rows |
Readability | Usually simpler | Often harder to reason about |
Optimizer friendliness | Often better | More likely to create planning limits |
Good fit | Global thresholds, fixed filters | Existence checks, row-relative logic |
Risk | Usually maintainable if short | Often slow and harder to debug |
A practical rule helps here. If the inner query can be pasted into your SQL editor and run by itself, it’s non-correlated. If it can’t because it references an outer alias, treat it as a potentially expensive pattern.
Common Patterns and Practical Use Cases
Subqueries become easier to judge when you’ve seen the recurring patterns. Most analytics work doesn’t require creativity so much as choosing the right pattern for the job.
Filtering with IN and NOT IN
One of the most common uses is filtering one dataset based on values returned from another.
Find customers who placed a completed order:
Find customers who have not adopted a feature:
Nested SQL queries with GROUP BY and aggregation functions are important for cohort analysis, and NOT IN combined with nested queries is useful for segmentation and data quality workflows, as shown in Data Carpentry’s nested query lesson.
That’s a very normal analytics pattern. Product, lifecycle, and growth teams use it constantly.
Checking existence with EXISTS
EXISTS is often a better fit when you only care whether matching rows exist.
List departments that have at least one employee:
This pattern is especially good when you don’t need a full list from the inner query. You just need to know whether the match is there. In practice, I prefer EXISTS over IN when the logic reads as a yes-or-no relationship.
For analytical comparisons that involve ranking or row-relative calculations, subqueries can work, but window functions in SQL usually produce cleaner code.
Adding context with a scalar subquery
A scalar subquery returns one value and can sit in the SELECT list.
This is useful when each row needs a reference point. It can make exploratory analysis easier because the comparison value is visible beside the row’s own value.
A scalar subquery is fine when it adds one stable reference value. It becomes noisy when you stack several of them into the same
SELECTlist.
The common failure mode here is overuse. If you add multiple scalar subqueries, or each one embeds more logic, readability drops fast. At that point, move the shared logic into a named CTE or derived table.
The Performance Impact on Modern Data Warehouses
Modern warehouses are much better at query optimization than many people assume. They can often rewrite a simple subquery into an execution plan that looks a lot like a join. That’s the good news.
The bad news is that people hear “the optimizer is smart” and stop thinking about execution shape.
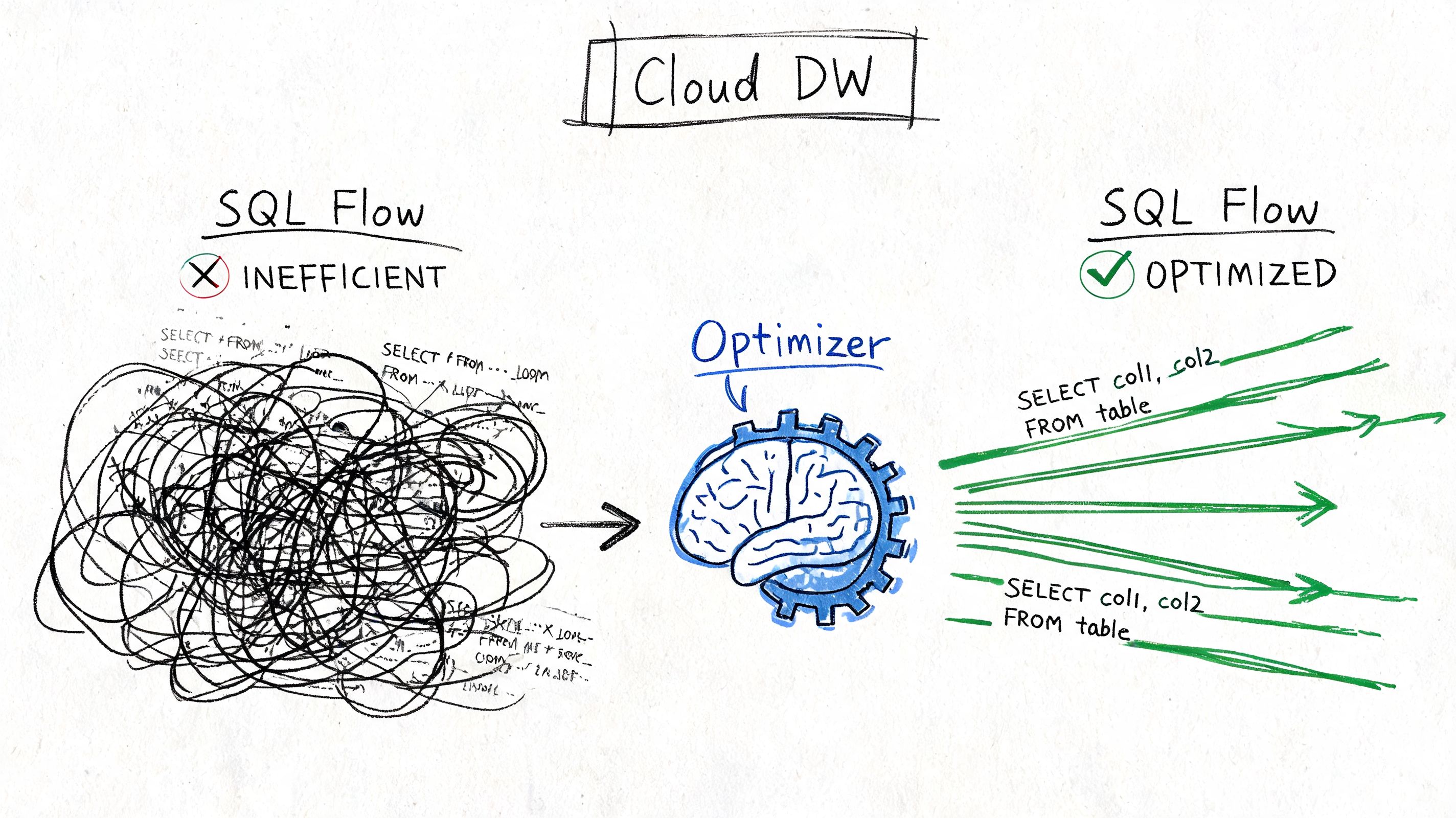
How execution order shapes performance
The key execution model is straightforward. The inner SELECT executes first, and its result is passed to the outer SELECT, as summarized in this explanation of nested subquery execution order and selectivity. That sounds simple, but the consequences vary a lot depending on what the inner query returns.
If the inner query is selective and shrinks the working set early, nested logic can work well. If it returns a large intermediate result, or if the database has to reevaluate it in an expensive pattern, performance can degrade quickly.
That’s why I care less about whether a query uses a subquery and more about what that subquery does to the data shape.
Good sign: The inner query reduces rows sharply before the outer query runs.
Bad sign: The inner query scans broad data and produces a large result with little filtering value.
Worse sign: The logic is correlated and tied to outer-row processing.
When teams start paying close attention to optimizing cloud spend using SQL, they usually discover the same thing. Compute cost is often driven by query shape, repeated scans, and oversized intermediates rather than by SQL syntax alone.
Where optimizers help and where they do not
Optimizers often help with simple, non-correlated subqueries. They may flatten them, reorder joins, or push filters down into the plan. But that doesn’t mean every nested sql select is automatically safe.
Correlated subqueries remain the biggest trap. They can block broader rewrites and push the warehouse toward repeated work. Even when the engine eventually produces an acceptable plan, the query is still harder for humans to inspect.
The optimizer can rescue some bad SQL. It can’t rescue unclear intent.
In startup environments, this matters because SQL gets reused by many people. One analyst writes the first version, another turns it into a dashboard query, and a third embeds it into a scheduled model. If the original pattern is already fragile, scale exposes it.
That’s also where warehouse design matters. Query behavior is shaped by modeling choices, table size, and concurrency patterns, not just syntax. Teams standardizing self-service reporting should understand the broader context in data warehouse architectures, because query-level tuning and warehouse-level design are tightly connected.
Refactoring Nested Selects for Readability and Speed
A nested query isn’t a badge of sophistication. It’s just one way to express logic. When it stops being clear, stop defending it and rewrite it.
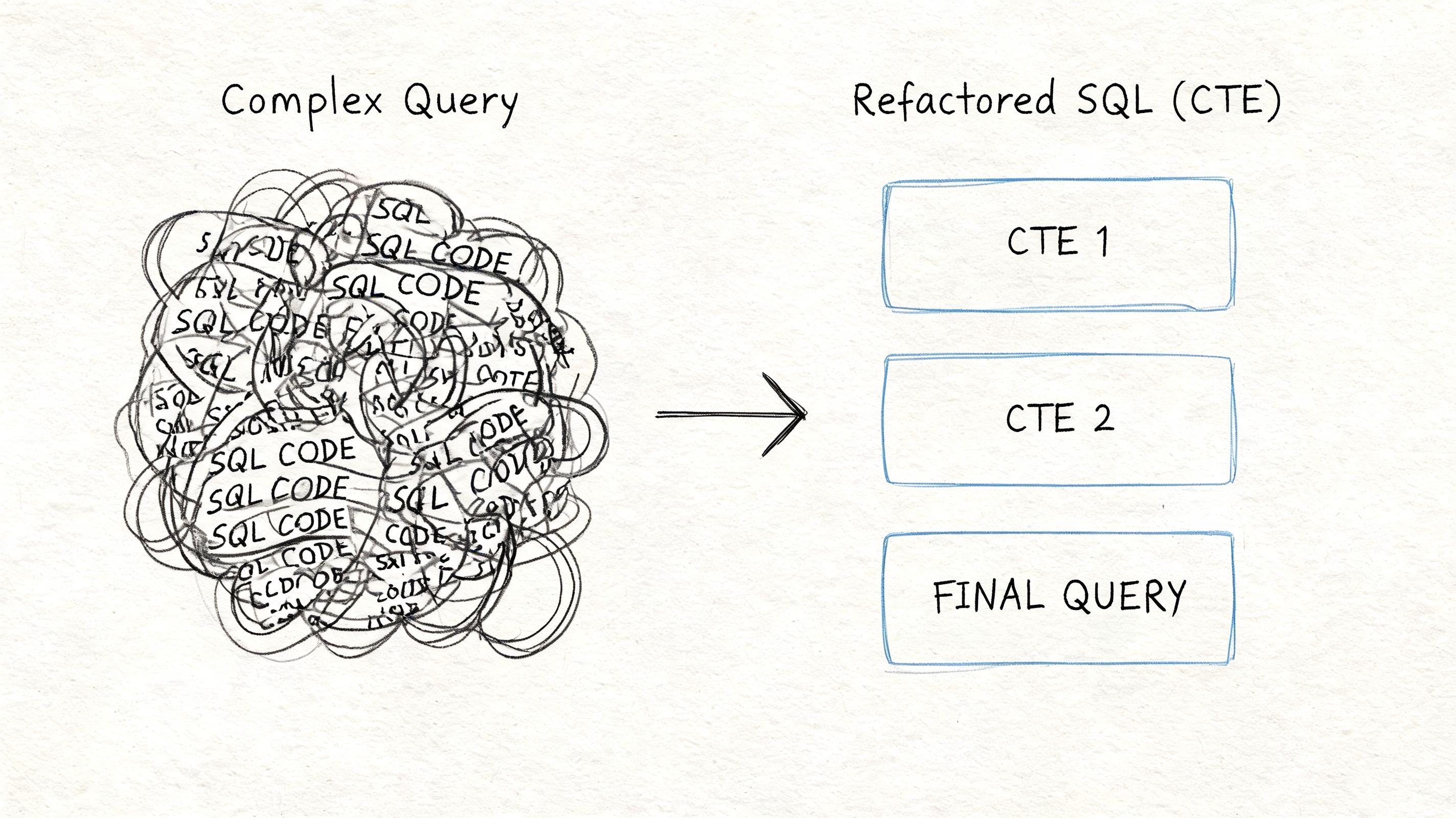
Refactor to a CTE when the logic has stages
Take this nested query:
It works. It also repeats logic and forces the reader to mentally parse nested blocks twice.
A CTE version is easier to maintain:
The output is the same. The difference is organizational. Each step has a name, and each name communicates intent.
This is the same reason application teams use structured refactoring approaches instead of letting complexity accumulate. Modernization Intel's refactoring framework is aimed at broader codebases, but the principle applies cleanly to SQL. Rewrite only when structure has become the obstacle. Refactor when the logic is still sound but hard to work with.
Refactor to a JOIN or window function when the pattern is analytical
If the subquery is just filtering based on another table, a JOIN is often cleaner.
Before
After
If the subquery compares a row to a group-level metric, a window function is often the strongest option.
Before
After
That version usually reads more like analysis and less like a workaround.
A short walkthrough helps if you want to see the rewrite mindset in action:
In teams that support self-service analytics, tools can help rewrite and explain these patterns. For example, Querio’s query optimization workflows are designed around rewriting SQL into more maintainable forms such as joins and CTEs. That kind of assistance is useful when analysts can write the first draft but need help getting it production-safe.
Best Practices for Production Analytics
Production SQL has to survive handoffs. That’s where nested queries often fail. Existing resources often ignore the human factors, and non-technical users or junior analysts can struggle to debug complex nested queries, creating maintenance burden in self-service analytics environments, as noted in this discussion of nested query maintainability.
That means the standard for “good SQL” is higher than “returns the right rows.”
What to keep and what to avoid
Use simple subqueries for simple filters. A short non-correlated subquery in a
WHEREclause is often perfectly fine.Prefer CTEs when the logic has multiple stages. Named steps beat stacked nesting when someone else has to read the query.
Treat correlated subqueries as suspicious by default. They may be correct, but they deserve performance review.
Use joins for relationship logic. If you’re matching entities across tables, a join usually exposes intent more clearly.
Use window functions for comparative analytics. They’re built for row-versus-group calculations.
Write SQL for the next analyst, not just for the query engine.
The production mindset
My rule is simple. If a nested sql select makes the logic clearer, keep it. If it hides business meaning, duplicates logic, or makes debugging harder, refactor early.
That matters even more in startups. Reporting logic spreads quickly. What starts as an analyst’s notebook query often ends up powering team decisions. Readability is not cosmetic. It’s part of system reliability.
If your team is trying to scale self-service analytics without turning data into a ticket queue, Querio is one option to evaluate. It deploys AI coding agents directly on the warehouse and can help users work with advanced SQL patterns, including subqueries, joins, and rewrites into cleaner analytical workflows.

