Modern Data Stack: Accelerate Self-Serve Analytics for Your Team
Discover how the modern data stack enables self-serve analytics with essential components, tools, and strategies to empower your team.
https://www.youtube.com/watch?v=h7NoWIcar8U
published
Outrank AI
modern data stack, data architecture, business intelligence, self-serve analytics, data engineering
56d38ece-1550-470e-8a04-32f53946a079

The modern data stack isn't just a new set of tools; it's a complete rethinking of how companies handle their data. Think of it as a cloud-native toolkit designed to collect, store, clean up, and analyze information. It marks a huge departure from the old, rigid, on-premise systems of the past.
This new approach is all about flexibility, scale, and putting data directly into the hands of the people who need it—not just the data engineers.
What Is the Modern Data Stack Anyway?
Let’s use an analogy. Imagine all your company’s data is raw food coming from different farms: user clicks from your app, transaction details from Stripe, campaign results from Google Ads. A traditional data setup was like a stuffy, old-school restaurant with one overworked chef. Every single request for a new report or analysis had to go through them, creating a massive bottleneck.
The modern data stack is the exact opposite. It's a state-of-the-art, open-plan kitchen with specialized stations and appliances. Anyone on the team can walk in, grab the ingredients they need, and prepare their own analysis, fast.
This architecture isn't a single, monolithic product. It’s a philosophy built on using specialized, best-in-class tools that connect easily. This "unbundled" approach means you can pick the perfect tool for each stage of the data journey—one for pulling data in, another for storing it, and a different one for building dashboards—without being locked into one vendor’s ecosystem.
The Core Philosophy: Modular and Accessible
The whole point of the modern data stack is to make data accessible to everyone. By centralizing data in a powerful cloud warehouse, it gives business users the ability to explore and answer their own questions. This completely removes the traditional logjam where every single data request had to be funneled through a central IT or data team.
For a deeper dive into how this central component works, check out our guide on business intelligence and data warehousing.
This shift has a massive impact on how quickly a business can move. When a product manager can instantly dig into user behavior or a marketing lead can track campaign performance in real-time, the entire company gets smarter and faster. Data stops being a siloed, guarded resource and becomes a shared utility that powers everyday decisions. To better understand the benefits, it's worth reading a good guide to data modernization services.
The modern data stack flips the old model on its head by championing ELT (Extract, Load, Transform) instead of ETL (Extract, Transform, Load). This means raw, unfiltered data is loaded directly into the cloud warehouse first. It gets transformed later, giving analysts the ultimate flexibility to work with the original data in any way they see fit.
To really see the difference, it helps to compare the two approaches side-by-side.
Modern Data Stack vs Traditional BI Architecture
Characteristic | Traditional BI Architecture | Modern Data Stack |
|---|---|---|
Hosting | On-premise servers | Cloud-based |
Structure | Monolithic, all-in-one vendors | Modular, best-in-class tools |
Data Flow | ETL (Transform before Load) | ELT (Transform after Load) |
Scalability | Limited, expensive to scale | Elastic, pay-as-you-go |
Accessibility | Limited to technical teams (IT, BI) | Open to all business users |
Speed | Slow, batch processing | Fast, real-time or near-real-time |
Flexibility | Rigid, pre-defined schemas | Highly flexible, raw data available |
This table shows a fundamental philosophical shift. The modern approach is built from the ground up for the speed and scale that today’s businesses demand, trading the rigidity of the old world for the flexibility of the cloud.
A Rapidly Growing Market
The widespread move to these new architectures is more than just a trend; it's a major market shift. The data integration market, which is the engine of the modern data stack, was valued at $15.18 billion in 2026.
Forecasters expect that number to nearly double, hitting $30.27 billion by 2030. This explosive growth shows just how critical these agile, cloud-first data systems have become for any company that wants to stay competitive.
Deconstructing the Core Components
To really get what makes the modern data stack tick, you have to look under the hood. It’s not a single piece of software; it's more like a finely tuned orchestra of specialized, cloud-native tools all working in harmony. Each one has a specific job to do on the journey from raw, messy data to clear, actionable insights.
I like to think of it as a sophisticated digital factory. Raw materials (your data) come in from all your different suppliers, move through various assembly stations, and come out the other end as a finished product (insights) that your team can actually use.
Let's walk through each stage of this production line.
Data Ingestion: The Delivery Trucks
First things first, you have to get the data into your system. This is the data ingestion layer. Picture a fleet of automated delivery trucks that go out to all your data sources—your CRM, Google Ads, the product database, Stripe—and bring all that raw material back to the factory.
Tools in this space, like Fivetran or Airbyte, specialize in building and maintaining pre-built connectors to hundreds of sources. Instead of your engineers burning weeks writing fragile, custom scripts that always seem to break, these tools do the heavy lifting. They make sure data shows up consistently and on schedule, creating the crucial first link in your data supply chain.
This is a huge departure from older, more rigid data processes. The whole workflow becomes much more flexible and iterative.
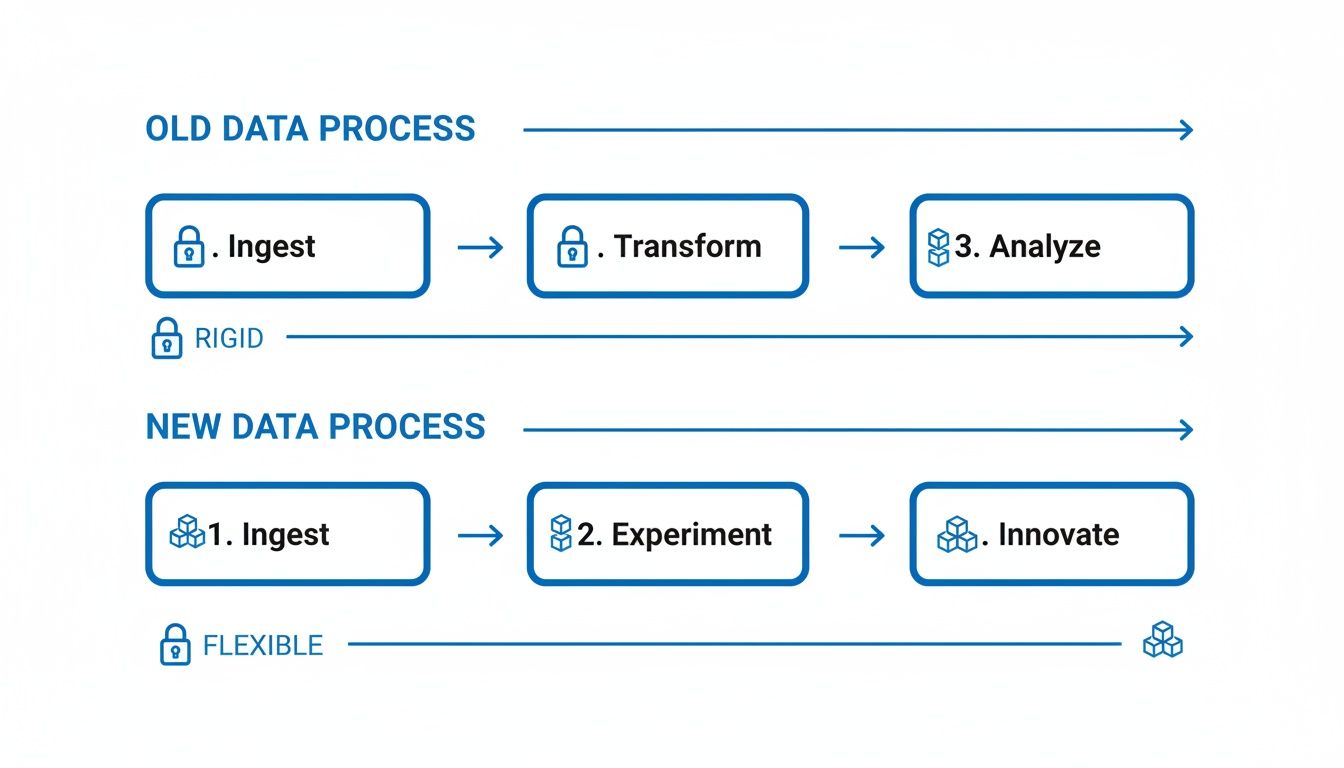
As you can see, it's less of a straight, locked-down assembly line and more of a dynamic cycle that actually encourages people to experiment and innovate along the way.
Data Warehousing: The Central Warehouse
Once all that raw data arrives, it needs a home. That's the job of the cloud data warehouse (or a data lakehouse), which is the undisputed centerpiece of any modern data stack. Think of it as a massive, infinitely scalable central warehouse where every single piece of raw material is stored and neatly organized.
Platforms like Snowflake, Google BigQuery, and Databricks have completely changed the game here. The big innovation was separating storage from compute. This means you can store petabytes of data for cheap and then fire up powerful computing resources only when you need to run a query, which saves a ton of money. This central repository becomes the single source of truth for the entire company.
Transformation: The Assembly Line
Let's be honest, raw data is usually a mess. It needs to be cleaned up, joined with other data, and molded into a consistent format that’s actually ready for analysis. This is the transformation stage—it's the factory's main assembly line.
This is where a tool like dbt (data build tool) has become the de facto standard. It brilliantly allows data teams to apply software engineering best practices—things like version control, automated testing, and documentation—to the messy work of data transformation. Using simple SQL, analysts can build clean, reliable data models that everyone from finance to marketing can trust for their reports.
Orchestration: The Factory Manager
With all this data moving between ingestion, storage, and transformation, something needs to keep it all straight. You need a system to manage the entire workflow, making sure every job runs in the right order and on time. This is where orchestration comes in. It’s the factory’s diligent floor manager, clipboard in hand, making sure the entire production line runs without a hitch.
Tools like Dagster or Airflow let teams define the dependencies between all their data jobs. For example, the orchestrator makes sure the daily sales data is fully loaded before the transformation job that calculates monthly recurring revenue kicks off. This prevents a world of pain and ensures your dashboards are always showing numbers based on the latest, complete data.
Business Intelligence and Analytics: The Showroom
Okay, the data has been collected, stored, and cleaned. Now it's time for the big reveal. The business intelligence (BI) and analytics layer is the interactive showroom where your business users can finally explore the finished products.
This is where your teams build dashboards, run reports, and ask all their questions. Modern BI tools like Querio, Looker, or Tableau connect directly to the data warehouse and provide a user-friendly way for non-technical folks to slice, dice, and visualize information. The goal is to get out of the way and let everyone answer their own questions without having to write a single line of SQL.
Reverse ETL: The Shipping Department
Last but certainly not least, insights are pretty useless if they just sit in a dashboard. The most valuable data is data that gets put to work. Reverse ETL is the shipping department that takes the finished insights and calculated metrics from your warehouse and sends them back into the operational tools your teams live in every day.
With Reverse ETL, you can sync data like a "product-qualified lead" score directly into Salesforce for the sales team. Or you could send a list of users at risk of churning into your marketing automation tool to automatically trigger a re-engagement campaign. This concept, often called "operational analytics," is what closes the loop. It turns data from a passive reporting tool into an active driver of business actions.
Choosing the Right Tools for Your Stack
Trying to assemble your modern data stack can feel a lot like walking into a massive, bustling hardware store. Every aisle is packed with specialized tools, each one promising to be the perfect solution for your project. The sheer number of options is enough to cause analysis paralysis.
But here’s the secret: don't get distracted by the shiniest new tool or the one everyone is talking about. Instead, focus on finding the right tool for your team, your budget, and your specific problems. A ten-person startup has wildly different needs than a Fortune 500 company, and the tools they choose should reflect that.
A Framework for Tool Evaluation
Before you even start browsing vendor websites, the first step is to look inward. A quick internal audit will give you a compass to navigate the crowded marketplace and keep you grounded.
Start by asking these questions:
Who is on our team? Do you have dedicated data engineers ready to write custom code, or will your analysts be managing the pipelines? Choosing tools that match your team's existing skillset is critical for quick adoption. For example, a platform like dbt is a fantastic fit for teams who live and breathe SQL.
What's our budget? Are you looking for a predictable monthly bill, or does a consumption-based (pay-as-you-go) model make more sense for your cash flow? Remember that open-source tools might have a $0 price tag upfront, but they come with hidden costs for maintenance, hosting, and engineering time.
How much will we grow? Think about your data volume today and where you realistically see it in two years. The last thing you want is a tool that works perfectly now but collapses under the weight of your future data needs.
How well does it play with others? Your data stack is an ecosystem. Does this new tool connect easily with the other components you're already using or planning to use? Seamless integration isn't a "nice-to-have"—it's a necessity.
Navigating the Tool Landscape
With your evaluation framework in hand, you can finally start exploring the options. The goal here isn't to become an expert on every single tool, but to understand the fundamental trade-offs in each category.
Let's take data ingestion as an example. You'll find tools like Fivetran and Stitch that offer hundreds of managed, automated connectors. They are incredibly easy to set up but can get pricey. On the other end of the spectrum, open-source alternatives like Airbyte give you more flexibility and control, but they demand more engineering effort to run and maintain. A good overview of the best data pipeline tools can help you decide which path makes sense for your team's resources.
To help you get started, here’s a quick look at some of the most popular tools and what to consider for each layer of the stack.
Modern Data Stack Tool Comparison
The sheer number of vendors can be overwhelming. This table breaks down some of the most well-known players in each category to help you see how they stack up.
Category | Popular Tools | Key Consideration (e.g., Use Case, Pricing Model) |
|---|---|---|
Data Ingestion | Fivetran, Stitch, Airbyte | Ease of Use vs. Customizability and Cost |
Data Warehouse | Snowflake, BigQuery, Databricks | Performance, Pricing Model, and Ecosystem Integration |
Transformation | dbt (data build tool), Dataform | SQL-based vs. GUI-based, Version Control Capabilities |
BI & Analytics | Querio, Looker, Tableau, Power BI | AI Capabilities, Ease of Use for Non-Technical Users |
This list is just a starting point, but it highlights the core trade-offs you'll encounter as you build out your stack.
Crucial Takeaway: Your business intelligence (BI) tool is the most user-facing part of your entire stack. This is where your team will spend their time turning raw data into actual decisions. Prioritizing a tool that truly empowers self-service is arguably the most important choice you will make.
The final layer, analytics, is where all your hard work pays off. It’s where the value of your modern data stack finally comes to life. As you look at different platforms, really dig into how well they support genuine self-service exploration for everyone, not just data experts. To learn more, check out our guide on the best self-service analytics tools and discover what it takes to break down data silos for good.
Building Your First Modern Data Stack
Diving into the modern data stack doesn't mean you have to sign a dozen expensive software contracts overnight. For startups and product teams just getting started, the goal is to start lean. Think of it like building a functional go-kart before you even attempt to design a Formula 1 race car—you want to get moving quickly with just the essential parts.
The whole idea of a "lean stack" is to get the most impact for the least amount of complexity and cost. It's about picking tools that are easy to manage, can grow with you, and solve your most pressing data problems right now. Are you trying to understand user engagement? Track your first few KPIs? That's the focus. The single biggest mistake we see at this stage is over-engineering a solution for problems you don't even have yet.

A Lean Stack Recipe for Startups
To get off the ground, focus on a core set of user-friendly, cost-effective tools that handle the most critical jobs. This simple but powerful combination can get you surprisingly far on your data journey.
Here's a sample recipe for a startup's first modern data stack:
Data Ingestion (Choose One): Start with an open-source tool like Airbyte. It’s perfect for pulling data from your main sources (like your production database, Stripe, or Google Analytics), and its free, self-hosted option is a lifesaver for early-stage budgets.
Data Warehouse (Choose One): Pick a cloud warehouse that offers a generous free tier and pay-as-you-go pricing. Google BigQuery or Snowflake are excellent starting points because they handle scaling automatically and need very little admin work.
Transformation (The Go-To): dbt (data build tool) is the undisputed champion here. Its free, open-source core lets your team start modeling data with plain old SQL, a skill many on your team probably already have.
Analytics (The Final Layer): This is where you actually see the value. An AI-powered BI platform like Querio empowers everyone—from product to marketing—to ask questions in plain English and get answers on the spot. This completely removes the bottleneck of needing a dedicated data analyst to write every single query.
This setup gives you a fully functional, end-to-end data platform without the scary enterprise price tag. You can start tracking user behavior and making data-driven product decisions right from the get-go.
Critical Decision Points and Common Pitfalls
As your company grows, so will your data needs. The beauty of a lean stack is that it's modular, so you can swap components out as you scale. The real trick is knowing when to upgrade to manage costs and complexity without getting ahead of yourself.
A common pitfall is premature optimization. Don't invest in a complex orchestration tool like Airflow when your dbt Cloud job scheduler works just fine. Wait until you have dozens of interdependent models before adding that layer of complexity.
Here are a few signs that it might be time to graduate to more powerful tools:
You hit your data source limit: If you're spending more time building custom connectors than you are analyzing data, it’s a clear signal to consider a paid, managed ingestion tool like Fivetran.
Your query costs are spiking: As your data volume explodes, you might need to introduce stricter cost controls and query optimization. This is where the more advanced features of your warehouse will come in handy.
Data quality becomes a recurring issue: When people on other teams start questioning the reliability of your data, that's your cue. It's time to invest in data observability and testing tools to rebuild that trust.
The push for smarter data management is happening everywhere. In the industrial sector, for instance, the data management market is projected to skyrocket to $213.20 billion by 2030, up from an estimated $105.10 billion in 2025. This explosive growth just shows the universal need for organizations to get a handle on their data—a journey that almost always starts with building a solid, modern data stack. You can read more about the industrial data management market growth on MarketsandMarkets.com.
Ultimately, your first stack is a starting point, not a final destination. By starting lean and making practical upgrades based on real business pain points, you can build a powerful data foundation that grows right alongside you.
Unlocking True Self-Serve Analytics
Let's be honest, the real magic of a modern data stack isn't just the fancy tech or the lightning-fast queries. It’s about what that technology unlocks for your people. For years, the process was painful: a business user has a simple question, they file a ticket with the data team, and then they wait. And wait. By the time they get a report back, the moment has often passed.
This cycle was a creativity killer. It trained people not to ask questions and slowed down decision-making across the entire company.
A well-built modern data stack flips that script entirely. Its ultimate goal is to deliver true self-serve analytics, turning data from a locked-away treasure into a public utility that anyone can access. When your data is clean, reliable, and all in one place, it sets the stage for a completely different way of working.

From SQL Queries to Plain English
The next big leap forward in analytics is knocking down the final wall for non-technical folks: the need to write code. New AI-powered BI tools are emerging that plug right into your data warehouse and act like a translator. So, instead of wrestling with SQL, a product manager can just ask a question like they would ask a colleague: "What was our user retention rate for Q2 signups, and can you break that down by marketing channel?"
This conversational approach changes everything. It means your team can explore data, poke at interesting numbers, and follow their curiosity without hitting a technical dead end. This is what it really means to democratize data. If you’re curious about how to get started, our beginner's guide to self-service analytics lays out a practical path.
This shift empowers teams to move at the speed of thought. When answers are instantaneous, data becomes part of the daily workflow rather than a special project, leading to a culture of continuous learning and faster, more informed decisions.
Turning Your Stack into a Customer-Facing Asset
But why should the benefits stop with your internal teams? One of the most powerful moves you can make is to point your data stack outward with embedded analytics. This involves building data visualizations and exploration tools directly into your own product, turning your internal infrastructure into a valuable feature for your customers.
Think about a SaaS platform for e-commerce shops. Instead of just being an inventory tool, what if it also provided store owners with interactive dashboards showing their sales trends, customer behavior, and marketing ROI? That's powered by the exact same modern data stack your internal teams are using.
This strategy pays off in a few huge ways:
Increased Product Stickiness: When your app gives customers crucial insights they can't get elsewhere, it becomes essential to their business.
New Revenue Streams: You can package advanced analytics as a premium tier, opening up a brand-new way to monetize your product.
Enhanced Customer Experience: You're not just selling a tool; you're actively helping your customers succeed with their own data.
By embracing embedded analytics, you stop just analyzing your business and start using your data to directly improve your customers' businesses. It’s the final step in becoming a truly data-driven organization, turning an internal asset into a real competitive advantage.
Future-Proofing Your Data Strategy
Building a modern data stack is less like building a house and more like tending a garden. It's not a one-and-done project. You can't just set it up and walk away; it requires constant attention and adaptation to thrive as the data world evolves around it.
The tools and techniques we swear by today will almost certainly be old news in a few years. Future-proofing your strategy isn't about predicting the future perfectly. It's about building for change, staying ahead of major trends, and making sure your stack remains a competitive advantage, not a piece of technical debt you have to drag around.
This means you have to look beyond the problems you're solving today and think about the forces that are shaping tomorrow's data architecture. A few key trends are already drawing the map for the next generation.
Embracing the Next Wave of Data Innovation
To build a stack that has a real shelf life, you need a sense of where the industry is pointed. Three areas, in particular, are quickly shifting from "nice-to-have" to "can't-live-without."
Real-Time Data Streaming: For a long time, processing data in batches overnight was good enough. Those days are over for many businesses. If you're doing things like fraud detection, dynamic pricing, or just need to know what's happening right now, you need real-time streaming.
Automated Data Governance: When you only have a few data sources and a small team, you can manage governance manually. But as your data and team grow, that approach falls apart fast. A future-proof stack has to include automated tools for discovering data, checking its quality, and managing who can see what. This is the only way to keep your data secure and trustworthy at scale.
Data Observability: This is much more than just basic monitoring. True data observability gives you a deep, end-to-end view into the health of your data pipelines. It helps your team spot, diagnose, and fix data quality problems before they poison your analytics and break everyone's trust in the data.
The Rise of Data Contracts and Cost Management
As your company grows, one of the biggest headaches is keeping data quality high as it moves between different teams. This is exactly the problem data contracts are designed to solve.
Think of a data contract as a service-level agreement (SLA) for your data. It’s a formal handshake between a data producer (like a software engineering team) and a data consumer (like the analytics team). This agreement spells out the exact schema, meaning, and quality standards for a dataset, ensuring the data stays reliable even when the apps that create it are updated.
Data contracts are fundamentally about building trust. When you have these explicit agreements in place, you put an end to the dreaded "my dashboard is broken" emails and prevent flawed analyses from leading the business astray.
At the same time, you have to keep an eye on the bottom line. Most modern data tools run in the cloud on a consumption-based model, which is great for flexibility but can be dangerous for your budget. Without careful oversight, your cloud bill can explode.
Smart cost management means optimizing queries, setting up policies to automatically archive old data, and using observability tools to hunt down and eliminate waste. This kind of financial discipline is what makes your modern data stack sustainable, ensuring it delivers value for years to come without breaking the bank.
Frequently Asked Questions
When you start digging into the modern data stack, a lot of practical questions pop up, especially if you're used to older, more traditional systems. We get these questions all the time from founders, product managers, and data pros. Here are some quick, straightforward answers to the most common ones.
The goal here is to cut through the jargon and get to the heart of what you need to know when you're thinking about building one of these powerful setups for your business.
What’s The Real Difference Between A Modern And A Legacy Data Stack?
At its core, the difference is a complete shift in philosophy and architecture. A legacy stack is usually a closed, on-premise system from a single vendor. It's built around a rigid ETL process, which makes it slow to adapt and a pain to change.
The modern data stack, on the other hand, is born in the cloud. It's modular, meaning you can pick the best tool for each specific job—ingestion, storage, transformation, you name it. And it’s built on an ELT process. This design makes it incredibly flexible, easy to scale, and open for more people in the company to use, not just a siloed IT department.
Is A Modern Data Stack Just For Big Companies?
Absolutely not. While big enterprises get a lot out of it, you could argue the modern data stack is a game-changer for startups and growing businesses. With pay-as-you-go pricing models and powerful open-source tools, a small team can spin up a seriously capable data platform without a huge upfront check.
We’ve seen startups get a lean stack running in a few days. That means they can start making sharp, data-backed product decisions right from the get-go. It really does level the playing field, giving smaller players the kind of analytical power that used to be reserved for corporations with massive budgets.
The modern data stack isn't about company size; it's about the need for speed and agility. If your organization needs to move fast, test ideas, and give teams the data they need to win, this approach is for you.
Can't We Just Move Our Old Systems To The Cloud?
You can, but it's often a trap. Just lifting your old systems and shifting them to a cloud server—what's called a "lift-and-shift"—rarely gives you the benefits you're hoping for. Sure, you might save a bit on hardware maintenance, but you’re still wrestling with the same inflexible architecture and data bottlenecks that held you back in the first place.
A true modernization project means rethinking how your data flows from the ground up. It’s about adopting cloud-native tools and fully embracing that modular, ELT way of thinking. That’s how you unlock the real power of the modern data stack: the scalability, the self-service analytics, and the speed.
Ready to eliminate data bottlenecks and empower your entire team with true self-serve analytics? Querio's AI-powered platform connects to your modern data stack, allowing anyone to ask questions in plain English and get trusted answers in seconds. See how Querio can transform your business.

