Enterprise Data Warehouse Definition: A Founder's Guide
Get a clear enterprise data warehouse definition. Learn how an EDW helps startups scale analytics, eliminate data bottlenecks, and enable self-service BI.
https://www.youtube.com/watch?v=AHR_7jFCMeY
published
Outrank AI
enterprise data warehouse definition, data warehouse, business intelligence, data architecture, self-service analytics
59aff95f-c9d1-42b5-8821-74684492c6ee

Your head of product asks a simple question before the weekly meeting: “Which customers adopted the new feature, and did it reduce churn risk?”
The data exists. Some of it lives in Stripe. Some in Salesforce. Some in your product database. Some in support tickets. By the time an analyst pulls it together, the meeting is over and the decision moves on without facts.
That is the daily reality in many startups and mid-market companies. Data teams become a human API. Everyone waits in line. Every new question becomes a ticket, a dashboard request, or a Slack thread that ends with “I’ll get back to you.”
The enterprise data warehouse definition matters because it describes the system that breaks that pattern. An enterprise data warehouse, or EDW, is not just a bigger database. It is the organized foundation that lets a company answer questions consistently, quickly, and across departments.
Tired of Waiting for Data Answers?
A product manager wants activation by segment. Finance wants revenue by cohort. Customer success wants a renewal risk view. Marketing wants campaign influence. All four teams are asking reasonable questions. The problem is that each team pulls from a different system, with different definitions and different timestamps.
That is how companies end up debating numbers instead of making decisions.

When data work turns into waiting
Without a shared data foundation, one analyst becomes the translator between systems. They pull exports, join spreadsheets, fix naming issues, and explain why “active customer” means one thing in a dashboard and another thing in a board deck.
That bottleneck hurts more than reporting speed. It slows pricing decisions, product launches, forecasting, and customer follow-up.
If your team is still relying on one-off reports, it helps to understand the difference between operational questions and exploratory ones. This short guide to ad hoc queries is a useful companion: https://querio.ai/blogs/ad-hoc-queries
Why EDWs keep gaining ground
The clearest signal that this is not an edge problem is market adoption. The global enterprise data warehouse market was valued at approximately $14 billion in 2023 and is projected to reach $71.5 billion by 2030, reflecting a CAGR of 26.3%, driven by centralized data consolidation and AI-driven analytics, according to Peliqan’s enterprise data warehouse overview.
Executives are not investing in EDWs because they like infrastructure. They invest because they need a dependable place where product, finance, sales, and operations can work from the same facts.
Key takeaway: An EDW is the structural answer to the human API problem. It gives teams a shared, trusted system for analytics so routine questions stop flowing through a handful of overloaded specialists.
For leaders evaluating reporting tools, it also helps to understand where front-end BI fits. This overview of Power BI is a practical primer on how business users consume warehouse data once the foundation is in place.
What an Enterprise Data Warehouse Is
The simplest enterprise data warehouse definition is this: an EDW is the central data library for your business.
A normal pile of books may contain everything you need. But if the books are scattered across rooms, unlabeled, and duplicated, nobody can find the answer quickly. A library solves that with cataloging, organization, and rules.
An EDW does the same for business data.
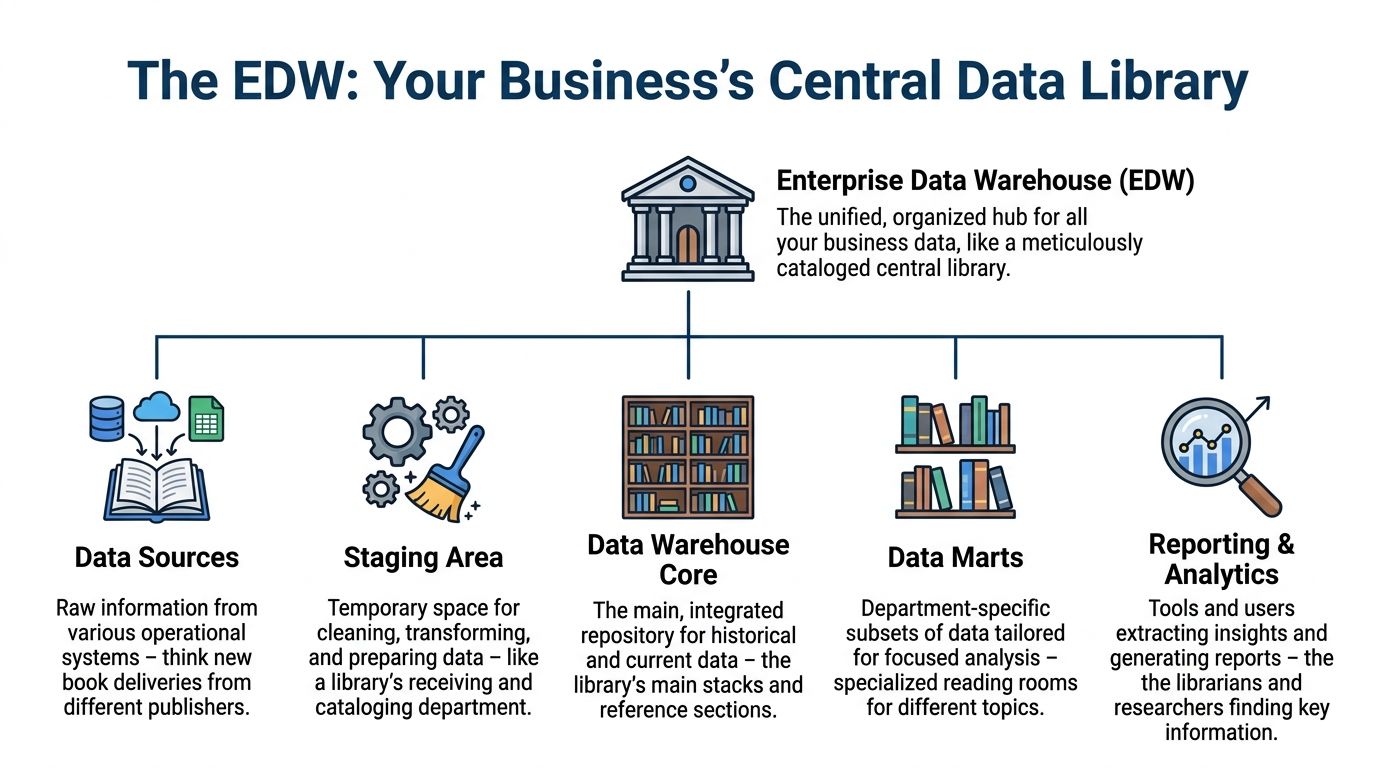
The library analogy in business terms
Your source systems are the incoming books. CRM records, billing data, support logs, product events, and finance exports all arrive in different formats.
The EDW receives that material, cleans it up, organizes it, and stores it so people can ask reliable questions later. If the CEO asks for revenue by region and the product lead asks for retention by plan, both should be drawing from the same underlying catalog.
If you want a broader primer on warehouse basics before focusing on the enterprise version, this overview is helpful: https://querio.ai/blogs/what-is-a-data-warehouse
The four principles that define an EDW
The modern idea of the EDW was formalized in the 1990s by Bill Inmon. He described enterprise data warehouses as integrated, subject-oriented, time-variant, and non-volatile, a framework that remains the standard for enterprise-scale analytics, as explained in Athena Solutions’ EDW guide.
Here is what those terms mean in plain English.
Integrated
Data from different systems is standardized into one environment.
If Salesforce says “Acme Inc.” and Stripe says “ACME,” the warehouse should reconcile that so teams are not treating one customer as two. Integration is what turns scattered records into a coherent picture.
Subject-oriented
The data is organized around business subjects such as customers, products, orders, or subscriptions.
This is different from operational systems, which are built around daily transactions. In an EDW, all relevant customer information can be analyzed together, even if it originated in sales, support, and product systems.
Time-variant
The warehouse keeps history.
That matters because executives rarely ask only “What is true right now?” They ask, “How has this changed over time?” An EDW is designed for trend analysis, cohort reporting, and before-and-after comparisons.
Non-volatile
Once data is stored for analysis, it is meant to be stable rather than constantly rewritten by day-to-day transactions.
That stability builds trust. Teams can revisit last quarter’s numbers and understand what happened, instead of chasing moving targets.
Practical test: If your system cannot reliably answer “what changed, for whom, and when?” across departments, you probably do not have an enterprise-ready analytics foundation yet.
The Core Components of a Modern EDW Architecture
Most executives do not need to know every database setting. They do need to know why an EDW answers questions faster and more reliably than a collection of operational tools.
A modern EDW usually follows a three-tier architecture. Think of it as a supply chain for analytics.
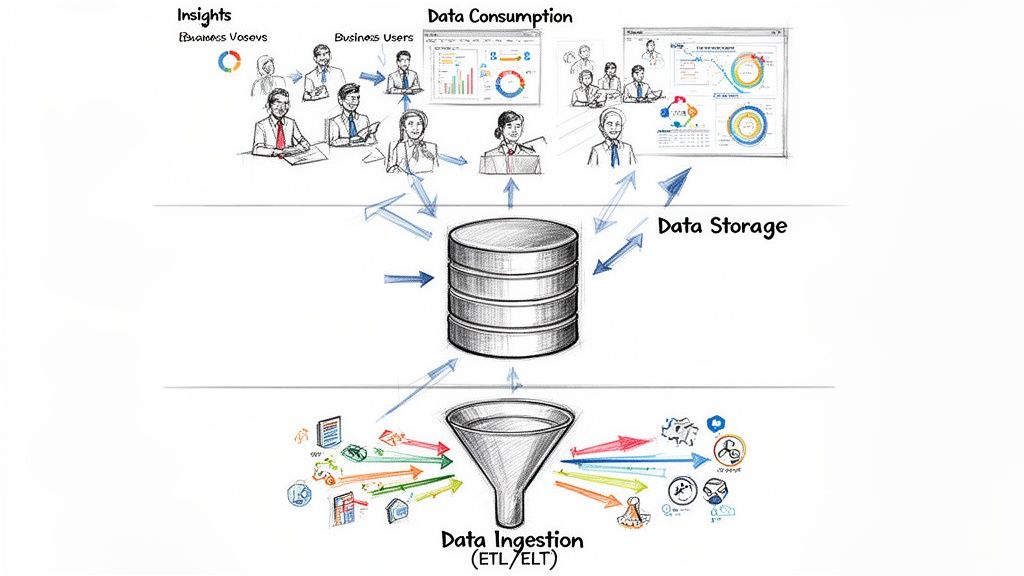
Bottom tier ingestion and preparation
This layer pulls data from systems your business already uses, such as HubSpot, Salesforce, NetSuite, Zendesk, or your product database.
The work here is often called ETL or ELT:
ETL means extract, transform, load. Data is cleaned before it lands in the warehouse.
ELT means extract, load, transform. Raw data lands first, then gets shaped inside the warehouse.
For teams trying to understand pipeline mechanics, this guide to ETL with Python gives a grounded view of how engineers automate data movement and transformation.
The business outcome of the bottom tier is simple. It removes the manual copy-paste work that creates conflicting spreadsheets and one-off logic.
Middle tier storage and processing
Here, the warehouse earns its keep.
The middle tier stores data in a form built for analytics, not for transaction processing. One important design choice is columnar storage. Instead of reading an entire row every time, the system can read only the columns needed for a query.
That is why EDWs can handle analytical workloads far better than many operational databases. The middle tier of an EDW, especially columnar storage, can outperform traditional row-based databases by 10-50x on analytical queries, enabling scans of 100TB of data in under a minute through massively parallel processing, according to Boomi’s enterprise data warehouse guide.
For a non-technical leader, the practical translation is this: dashboards refresh faster, large queries stop timing out, and analysts spend less time waiting for compute.
Top tier access for business users
The top tier is the interface many users see. This includes BI tools, SQL editors, dashboards, notebooks, and AI assistants that sit on top of the warehouse. Here, self-service either becomes real or remains a slogan. If the top layer is connected to well-modeled warehouse data, product managers can explore usage, finance can validate trends, and operations can monitor performance without rebuilding the logic each time.
A deeper walkthrough of common warehouse design patterns is here: https://querio.ai/blogs/data-warehouse-architectures
Here is a short visual overview of how these layers fit together in practice.
Why this matters to executives: The architecture is not academic. Each layer exists to reduce delays, increase consistency, and let more people answer their own questions safely.
EDW vs Data Lake vs Data Lakehouse
Leaders often hear three terms in the same meeting: enterprise data warehouse, data lake, and data lakehouse. They are related, but they are not interchangeable.
The easiest way to separate them is by the job each one is meant to do.
An EDW is built for trusted business reporting. A data lake is built for flexible storage of raw data. A lakehouse tries to combine elements of both.
The core distinction
An EDW expects structure before analysis. Data is cleaned, modeled, and governed before business users rely on it.
A data lake is more open-ended. Teams can store raw, semi-structured, or unstructured data there and decide later how to interpret it. That makes lakes attractive for experimentation, but it can also make them messy if governance is weak.
A lakehouse aims to offer warehouse-style query performance and governance on top of lake-style storage. For some companies, that hybrid is appealing. For others, it adds another layer of architectural choice before basic reporting is stable.
EDW vs. Data Lake vs. Data Lakehouse at a Glance
Criterion | Enterprise Data Warehouse (EDW) | Data Lake | Data Lakehouse |
|---|---|---|---|
Primary purpose | Reliable reporting and analytics across the business | Flexible storage for raw and varied data | Hybrid environment for both reporting and broader analytics |
Data style | Structured, cleaned, curated | Raw, semi-structured, unstructured, or mixed | Mixed, with more structure than a pure lake |
Schema approach | Schema-on-write | Schema-on-read | Hybrid approach |
Best for | Executive reporting, KPI tracking, finance, product analytics | Data science exploration, log storage, experimentation | Teams that want one platform for multiple workload types |
Typical user | Analysts, business users, executives | Data engineers, data scientists | Mixed teams |
Strength | Trust, consistency, repeatability | Flexibility, scale, exploratory freedom | Broader workload coverage |
Common risk | Can feel rigid if modeling is slow | Can become disorganized and hard to trust | Can be harder to govern and explain clearly |
Which one solves the human API problem
For startup and mid-market leaders, the question is usually not “Which architecture is most fashionable?” It is “Which setup helps my teams get dependable answers without always waiting on specialists?”
That usually points back to the EDW.
If your recurring need is board reporting, customer analytics, margin visibility, forecast inputs, or a clean Customer 360 view, the enterprise data warehouse definition fits your problem more directly. It gives business users a governed, structured place to ask known questions repeatedly.
A lake can still be useful. So can a lakehouse. But if your company cannot yet agree on core metrics, adding more flexibility often increases confusion instead of reducing it.
Rule of thumb: Start with the system that makes everyday decisions easier. For most operating teams, that is the EDW because trust beats raw flexibility when the business is moving fast.
Key Business Benefits and Strategic Use Cases
The strongest argument for an EDW is not technical elegance. It is organizational clarity.
When a company runs on multiple tools, each team tends to create its own version of the truth. Sales has one customer count. Finance has another. Product has its own definition of engagement. An EDW gives those teams a shared foundation.
What leaders get from a good EDW
A well-run EDW supports several business outcomes at once:
A single source of truth. Teams stop arguing over whose spreadsheet is correct.
Historical visibility. Leaders can track changes over time, not just point-in-time snapshots.
Cross-functional analysis. Product usage, billing, support, and CRM data can be analyzed together.
Safer self-service. More people can explore data without inventing their own metric logic.
A common use case is Customer 360. That means bringing together account data from CRM, subscription data from billing, support history from help desk tools, and behavior data from the product itself. The result is a fuller view of account health, expansion opportunity, and churn risk.
Why this matters more in the mid-market
Many mid-market companies know they need better data access but do not have deep in-house warehouse expertise. That gap is real. A 2025 dbt Labs survey found that 68% of data teams at mid-market companies lack the specialized SQL expertise required to build and maintain complex transformation pipelines, creating bottlenecks that self-service platforms on an EDW can help alleviate, according to dbt Labs.
That statistic explains why leaders often feel stuck. They want better analytics, but they cannot hire a large specialist team for every transformation, dashboard, and ad hoc question.
The answer is not to avoid structure. It is to build the right structure once, then let more of the business use it.
Strategic use cases that show up quickly
Some of the fastest wins come from a short list of repeatable needs:
Board and investor reporting Finance and leadership need consistent metrics at regular intervals.
Product and growth analysis PMs need activation, retention, and feature adoption tied to accounts and revenue.
Revenue operations alignment Sales, success, and finance need one view of pipeline, bookings, renewals, and expansion.
Support and service insight Teams can connect ticket volume or response patterns to customer health and product usage.
Executive lens: An EDW is not just a repository. It is a way to turn fragmented operational systems into a common decision surface for the whole company.
Implementing an EDW Without Breaking Your Budget or Team
The hard part is not understanding the enterprise data warehouse definition. The hard part is implementing one in a way your team can sustain.
Many companies overbuild early. They choose too many tools, ingest too many sources, or try to model the entire business before anyone gets value. Others go too loose, load everything, and discover later that nobody trusts the outputs.
Start with a narrow business scope
Do not begin by asking, “How do we warehouse all company data?”
Start by asking, “Which decisions are currently slowed by missing or inconsistent information?” For many teams, the first domain is revenue, customer health, or product usage. Those areas usually create visible pain and clear executive demand.
A focused first phase lets the team define a handful of trusted metrics, document ownership, and prove the operating model before expanding.
Prefer cloud-native patterns with clear governance
Most modern teams choose cloud-native warehouses because they are easier to scale than older on-premise patterns. They also fit the way startups and mid-market firms grow, which is unevenly.
The key architectural shift is not just “move to the cloud.” It is adopting a model where the warehouse can serve as the central governed layer for analytics while tools connect directly to it.
That requires governance from the beginning:
Access rules so teams see what they should see
Metric definitions so revenue, churn, and activation mean one thing
Model ownership so every important table has a responsible team
Query monitoring so costs do not drift upward
Treat cost control as part of design
Budget overruns are common in EDW projects. Recent 2025-2026 data shows that 72% of EDW projects exceed their budgets by an average of 40% within the first year, often because of unoptimized queries and unexpected cloud infrastructure costs, according to Skyvia’s enterprise data warehouse article.
That is not a reason to avoid an EDW. It is a reason to manage it deliberately.
Common mistakes include loading too much low-value data, letting every dashboard run expensive logic, and failing to define which transformations belong in the warehouse versus in downstream tools.
Build for self-service, not ticket volume
The point of the EDW is not to create a cleaner backlog for analysts. The point is to reduce dependence on them for routine work.
That means your top layer matters as much as your storage layer. Business users need interfaces they can use, while data teams keep control over definitions and permissions.
A platform like Querio also fits naturally here. It deploys AI coding agents directly on the data warehouse so teams can query and build on governed warehouse data through custom Python notebooks, instead of routing every request through analysts.
One practical model is to pair a cloud warehouse with lightweight transformation and documentation standards, then add tools that let users query governed data directly. For teams exploring that approach, this example stack is relevant: https://querio.ai/articles/the-budget-friendly-ai-bi-stack-warehouse-querio
Tools differ in approach. Some focus on dashboards. Some focus on notebooks. Some focus on semantic layers or natural language access. The right choice depends on who needs answers and how they work.
A practical rollout pattern
A sensible implementation usually follows this rhythm:
Choose one high-stakes domain such as revenue, customer health, or product analytics.
Map the source systems involved in that domain.
Define core business entities like customer, account, subscription, event, or invoice.
Standardize a small set of metrics before expanding.
Give users governed access through BI, notebooks, or AI-assisted tools.
Review usage and cost monthly so architecture stays aligned with business value.
Final advice: A good EDW does not remove the need for a data team. It changes their role. Instead of answering every question by hand, they create the environment where many more people can answer questions safely on their own.
If your team is stuck in analyst queues and conflicting dashboards, Querio is one way to turn an enterprise data warehouse into a self-service workspace. It connects directly to your warehouse, lets users work on governed live data, and helps data teams shift from report producers to infrastructure owners.

