Mastering Star and Snowflake Schema: A Data Leader's Guide
Star and snowflake schema - Navigate the complexities of data warehousing. Understand the differences, pros, and cons of star and snowflake schema to optimize y
https://www.youtube.com/watch?v=hQvCOBv_-LE
published
Outrank AI
star and snowflake schema, data warehouse design, dimensional modeling, business intelligence, data modeling
e77eb574-1e3f-4917-8231-031889f3f7cf

For data leaders and engineers, the choice between a star and snowflake schema really comes down to a classic trade-off. A star schema is all about speed and simplicity. It's a denormalized design that makes it perfect for fast-paced reporting. The snowflake schema, on the other hand, puts data integrity and storage efficiency first, which means a more complex, normalized structure.
Choosing Your Data Warehouse Blueprint
Picking the right schema is one of those foundational decisions that will define the speed, integrity, and future scalability of your entire business intelligence setup. This choice directly controls how easily your team can get to the data they need and actually make sense of it. It’s a decision that either unlocks self-serve analytics or puts a roadblock in front of it, so understanding the deep architectural give-and-take is essential.
This guide goes past the simple pros and cons. We're going to look at how this choice truly shapes the outcomes for your business, depending on your goals and your team's skills. A well-designed schema is the backbone of any successful https://querio.ai/blogs/data-warehouse-model.
Core Architectural Trade-Offs
The main difference is all about how each model treats dimension tables. In a star schema, you keep the dimensions "denormalized." Think of a single Product table that holds all its related attributes—category, brand, and supplier—all in one place. This makes for a simple, flat structure where queries run incredibly fast because you're doing fewer joins.
A snowflake schema takes the opposite approach by "normalizing" those same dimensions. The Product table would only contain a product key, linking out to separate Category, Brand, and Supplier tables. This cuts down on redundant data and keeps things clean, but it comes at the cost of more complex queries that need those extra joins to pull everything together.
Aspect | Star Schema | Snowflake Schema |
|---|---|---|
Structure | Denormalized & simple | Normalized & complex |
Query Speed | Faster (Fewer Joins) | Slower (More Joins) |
Storage | Higher (Data Redundancy) | Lower (More Efficient) |
Maintenance | Easier to manage | More complex to update |
Best For | Fast BI dashboards & ad-hoc reports | Complex hierarchies & data integrity |
The core difference is simple yet profound: the star schema is built for speed and simplicity, while the snowflake schema is built for accuracy and efficiency.
Ultimately, the blueprint you select for your data warehouse must be the one that best supports the critical process of turning data into actionable insights. Your choice will define the everyday balance between performance and maintenance, shaping how your entire organization works with its data.
The Architectural Showdown
When you’re designing a data warehouse, the choice between a star and a snowflake schema isn't just a technical detail—it's a fundamental decision that shapes how your data is stored, queried, and maintained. These two approaches represent distinct philosophies in data modeling, and your choice will have a direct impact on query performance and how easily your team can make sense of the data.
The star schema is all about simplicity and speed, achieved through a denormalized structure. Think of it like a central fact table—holding your core business metrics like SalesAmount or QuantitySold—surrounded by several directly connected dimension tables. These dimensions, like Product, Customer, and Date, provide the "who, what, where, and when" context for your facts.
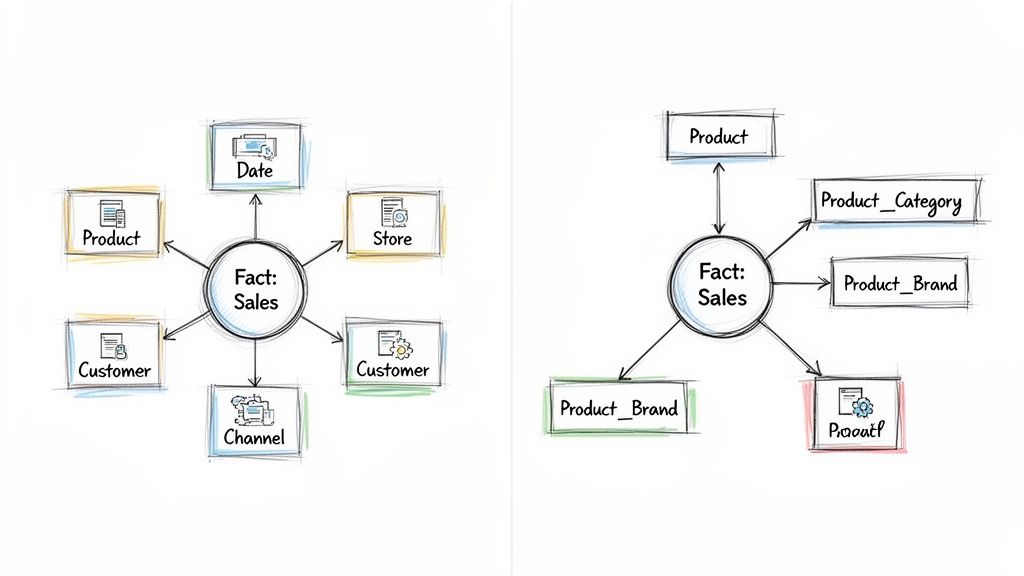
As you can see in the diagram, every dimension table connects to the fact table with just a single join. This clean, star-like structure is intuitive for analysts and incredibly efficient for BI tools to navigate.
The Star Schema Blueprint
What really defines a star schema is its denormalized design. For example, a single Product dimension table would contain everything related to the product: its name, category, sub-category, and even the brand. Yes, this means you'll have some data redundancy—the brand "Apple" might appear thousands of times—but that's a deliberate trade-off.
A star schema's main purpose is to make querying as simple as possible. By flattening hierarchies into wide dimension tables, you create a model where most reports can be generated with very few joins, resulting in a major performance boost for analytics.
This structure is a game-changer for reporting speed. Compared to a more normalized model, the star schema's design can cut down the number of JOINs needed for common analytical queries by 70-80%, based on 2026 industry benchmarks. That's why it's a favorite for many BI applications. If you want to dive deeper into the nuts and bolts, our guide to star schema data modeling is a great place to start.
The Snowflake Schema Alternative
On the other hand, the snowflake schema prioritizes storage efficiency and data integrity by embracing normalization. It also starts with a central fact table, but it handles dimensions very differently. Instead of large, denormalized tables, it breaks them down into smaller, related tables in a process known as snowflaking.
For instance, that single Product dimension from the star schema would be split apart in a snowflake model:
A
Producttable links to aSubCategoryID.A
SubCategorytable then links to aCategoryID.Finally, a
Categorytable holds the top-level category names.
This creates a branching, snowflake-like pattern that eliminates data redundancy. If you need to update a category name, you only have to change it in one place, which is great for data consistency. The downside? Answering a simple business question now requires stringing together multiple joins to reconstruct the full context, which can bog down query performance.
Comparing Performance And Cost
When you get right down to it, choosing between a star and snowflake schema is all about a single, fundamental trade-off: query performance versus storage cost. This isn't just a technical detail for data engineers to debate. Your choice has a direct impact on everything from the responsiveness of your BI tools to your monthly infrastructure bill and how quickly your analytics team can deliver insights.
The two models were designed with entirely different goals in mind. One is engineered for pure speed, the other for efficiency.
The star schema is built for one thing above all else: blazing-fast query performance. Its magic lies in a denormalized design where dimension tables are intentionally kept wide and flat. By cutting down on the number of joins needed to connect a fact table to its descriptive context, queries simply run faster. This is the foundation of modern, interactive business intelligence.
This structure makes the star schema the go-to choice for most OLAP (Online Analytical Processing) workloads, where reading data is far more common than writing it. To get a better feel for these workload differences, you can check out our deep dive on the key distinctions between OLTP and OLAP systems.
The Star Schema Query Speed Advantage
Let's say an analyst needs to calculate total sales by product category and customer region. In a well-designed star schema, this query might only involve two joins—one from the Fact_Sales table to Dim_Product and another to Dim_Customer. That simplicity is what gives it speed, which is absolutely critical for BI tools where users expect near-instant responses as they slice and dice data.
And this performance gain is no small matter. For most common reporting tasks, a star schema will handily outperform a comparable snowflake model. This makes it the clear winner for:
Interactive Dashboards where every filter and drill-down needs to feel immediate.
Self-Service Analytics platforms where business users need an intuitive, responsive experience without having to understand the underlying structure.
High-Concurrency Scenarios that involve many users hitting the same dataset at once.
The star schema deliberately trades storage efficiency for raw query speed. By pre-joining hierarchical data into wide dimension tables during the ETL process, it shifts the computational work away from the query engine, ensuring analysts get answers faster when it counts.
The Snowflake Schema Storage Efficiency Edge
On the other side of the scale, the snowflake schema’s main claim to fame is its storage and maintenance efficiency. By fully normalizing its dimension tables, it methodically roots out data redundancy. For example, in a star schema, an attribute like "United States" might be repeated millions of times in a huge customer dimension. In a snowflake schema, it's stored just once in a separate Dim_Country table and referenced by a simple key.
For truly massive data warehouses with dimensions holding hundreds of millions or even billions of rows, this normalization can translate into significant storage cost savings. This was a huge deal back in the days of on-premise data warehousing, when every gigabyte of storage was a major capital expense.
But that efficiency comes at a cost. Our sales query from before would now require several additional joins to navigate the normalized hierarchies. The query engine has to piece together the Product -> SubCategory -> Category chain, which adds computational overhead and slows down response times.
To help you visualize the key differences at a glance, here’s a quick breakdown of how the two schemas stack up.
Star Vs Snowflake Quick Comparison Matrix
This table provides a side-by-side view of the most important attributes, making it easier to see which model aligns with your priorities.
Attribute | Star Schema | Snowflake Schema |
|---|---|---|
Primary Goal | Maximize query performance for fast analytics | Minimize storage footprint and data redundancy |
Query Path | Simple, direct joins from fact to dimension tables | Complex, multi-step joins through normalized hierarchies |
Data Redundancy | High; descriptive attributes are repeated | Low; attributes are stored once and referenced by keys |
Ideal Workload | Read-heavy, interactive analytics and reporting | Environments with frequently updated, complex dimensions |
Cost Driver | Higher storage costs from data duplication | Higher compute costs from more complex queries |
Ultimately, the choice depends on what you value more: the immediate performance gains of a star schema or the long-term storage and maintenance benefits of a snowflake.
How Modern Cloud Warehouses Changed The Game
The old-school debate of performance-versus-cost has been turned on its head by modern cloud data warehouses like Snowflake, Google BigQuery, and Amazon Redshift. These platforms changed the rules by separating storage from compute, and that has had two major consequences.
First, the cost of cloud storage has dropped dramatically, which significantly weakens the snowflake schema’s main selling point of space efficiency. Second, the powerful, massively parallel query engines in these platforms are exceptionally good at handling complex joins and scanning wide tables.
This architectural evolution has tilted the scales heavily in favor of the star schema for most modern analytics use cases. While a snowflake schema still has its place for managing extremely complex hierarchies or enforcing data integrity in certain niche domains, the star schema's simplicity and raw performance are a much better fit for today's fast-paced, data-hungry organizations. The speed you gain almost always outweighs the now-marginal savings on storage.
Matching The Schema To The Use Case
Deciding between a star and snowflake schema isn't about finding the "best" model. It’s about matching the architecture to your business. The right choice boils down to what questions your team needs to answer, how fast they need those answers, and what kind of data governance you're required to follow. All the theoretical benefits in the world don’t matter if the model doesn't work in practice.
For most modern businesses that need to move quickly, the star schema has become the go-to standard. Its simple, flat structure is a perfect fit for the fast-paced world of analytics in retail, e-commerce, and product management.
Star Schema For Speed And Simplicity
Think of an e-commerce company trying to figure out if its marketing campaigns are working. The team needs to see daily sales, conversion rates, and ROI across different channels, and they need to see it now. A star schema with a central fact_sales table linked directly to dimensions like dim_date, dim_product, and dim_campaign gives them the quickest path to those insights.
Analysts can run simple queries with just a few joins to answer make-or-break questions:
How much revenue did our "Summer Sale" email campaign bring in last week?
Did the conversion rate on our new product line change based on traffic source?
Which customer segments bought the most during the Black Friday sale?
This directness is also why product teams analyzing user behavior lean so heavily on star schemas. If you model user actions in a fact_events table connected to dimensions like dim_user, dim_feature, and dim_session, you can build funnels and track cohorts efficiently. Because the design is denormalized, dashboards tracking user engagement and retention load in a snap, helping teams make decisions on the fly.
At its core, the star schema trades storage efficiency for raw query speed and simplicity. It's built for environments where getting insights quickly gives you a real competitive advantage.
Snowflake Schema For Integrity And Complexity
On the other side of the coin, the snowflake schema really shines in environments where data integrity, regulatory compliance, and complex hierarchies are top priorities. You'll often find it in heavily regulated industries like finance and healthcare, where its normalized structure provides an essential layer of control.
Take a large financial institution that has to generate detailed regulatory reports. The data often needs to be rolled up through multiple levels—from individual accounts to branches, then to regions, and finally to national divisions. A snowflake schema handles this kind of hierarchy beautifully.
A
dim_branchtable links out to adim_regiontable.The
dim_regiontable then links to adim_countrytable.
This normalized setup means that if a region's name needs to be updated, you change it in one single row in the dim_region table. That change automatically flows through all your reports, preventing data errors and ensuring everything stays consistent for audits. Trying to manage that same hierarchy in a star schema would be a maintenance headache waiting to happen.
It's a similar story in healthcare analytics, where patient data is organized into deep, complex taxonomies. A dim_patient_record might be "snowflaked" out into separate, smaller dimensions for diagnoses (using standard codes like ICD-10), treatments, and providers. This highly organized, normalized structure is non-negotiable for ensuring data is accurate enough for research and compliant with strict governance rules.
In the end, your business reality points the way. A startup obsessed with rapid growth will almost always get more value from a star schema's speed. But a large, established company in a regulated field will find the snowflake schema's discipline and data integrity indispensable. The choice between a star and snowflake schema is a strategic one that should reflect what your organization truly values.
Making The Right Choice For Your Team
Choosing between a star and snowflake schema isn’t just a technical debate—it's a strategic call that comes down to your team’s skills, your business goals, and the messiness of your data. There's no single "best" answer. The right choice is the one that fits your organization's reality and helps your team actually deliver insights.
A schema that flies for one company can grind another to a halt. The decision requires an honest look at your team's experience, how fast you need answers from your data, and the nature of the information you're wrangling. This isn't just about picking a design; it's about laying a foundation that will either speed up or slow down your entire data operation.
The Case For Star Schema Simplicity
For most teams, especially those trying to build a self-service analytics culture, the star schema's simplicity is its biggest strength. The structure is immediately understandable: a central fact table surrounded by directly connected dimension tables. This design dramatically lowers the barrier to entry for business users and analysts who don't need to be normalization experts to start exploring data.
That straightforward design translates directly into speed. Teams can spin up dashboards faster, and writing ad-hoc queries becomes far less of a headache. If your main objective is to get a wide range of people comfortable with asking their own questions of the data, the star schema is almost always the best place to start.
A star schema is the path of least resistance to a strong self-service analytics culture. Its intuitive design means less time spent on training and more time focused on analysis, which is a massive win for business users.
For product managers or startup leaders, the decision is often pretty clear-cut. Using a star schema for read-heavy analytics like growth tracking is a safe bet. The snowflake schema is usually reserved for situations with complex data hierarchies where saving on storage is a top priority. In the real world, a star schema can slash query times by up to 50% in performance-critical applications. On the other hand, a snowflake model can trim storage costs by around 30% in massive data warehouses, a trend noted in emerging best practices on platform expansion.
This decision tree gives you a simple way to think about which path to take based on what matters most to you—query speed or storage efficiency.
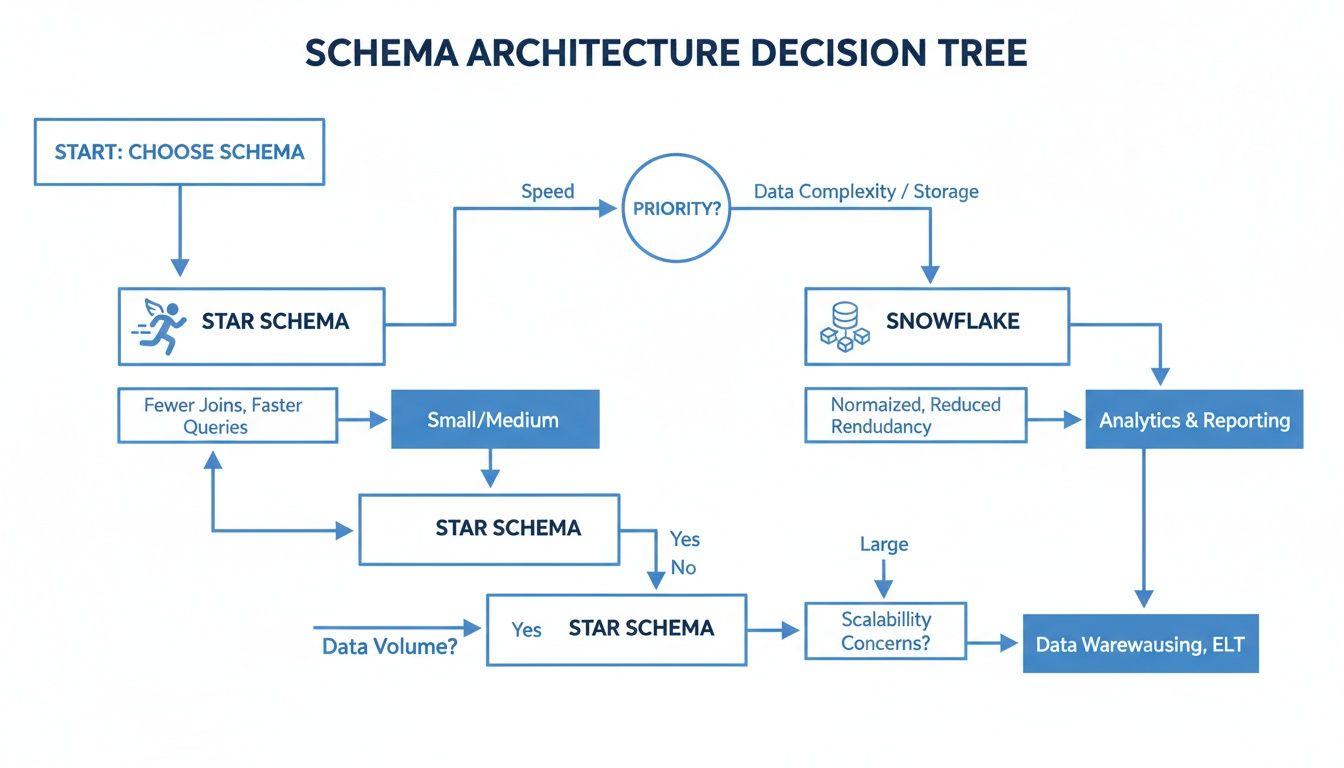
As the diagram shows, if your top priority is fast query performance for BI tools and dashboards, the star schema is your answer. But if you’re more concerned with managing complex, multi-level relationships and cutting down on data redundancy, the snowflake schema is the more logical choice.
When Snowflake And Hybrid Models Make Sense
Of course, the simplicity of a star schema comes with trade-offs. As your dimension tables swell and your business logic gets more tangled, keeping a denormalized model clean can become a real chore. This is where the snowflake schema earns its keep. It’s more demanding on your data engineering team, as it requires them to manage more complex ETL jobs and write queries with more joins.
If your team has solid data engineering chops and you're wrestling with deeply nested data—like complex product catalogs or multi-level organizational charts—the disciplined, normalized structure of a snowflake schema can be a lifesaver. It helps enforce data integrity and makes updating dimension attributes much cleaner.
For many, a hybrid approach is the most practical solution. You can use star schemas for the bulk of your analytics, particularly for the high-demand data marts that power your main BI dashboards. Then, for specific areas with exceptionally large or complex dimensions, you can selectively implement a snowflake design. This gives you the performance of a star schema where it counts most, while still getting the structural benefits of a snowflake where you need it.
Here’s a simple framework to guide your decision:
Look at Your Team's Skills: Can your team comfortably handle queries with multiple joins and sophisticated ETL pipelines? If not, sticking with a star schema is the lower-risk option.
Clarify Your Analytics Goals: Is your main goal to enable fast, self-service BI? A star schema is a perfect match. Or are you focused on guaranteeing absolute data integrity in a highly regulated field? A snowflake schema might be the better, safer choice.
Think About Growth and Complexity: It's almost always best to start simple. A star schema is a great first step. You can always evolve parts of your data warehouse into a snowflake structure later on if the scale and complexity truly demand it.
By thinking through these factors, you can make a smart choice between a star and snowflake schema that truly fits your team's abilities and supports your company's data ambitions for the long haul.
ETL And Maintenance Considerations
When you’re evaluating a data model, its real cost isn't just in the initial design—it's in the day-to-day effort required to keep it running. The ongoing work for ETL (Extract, Transform, Load) and routine maintenance is where the differences between a star and snowflake schema really start to show.
This is where your data engineering team will either thank you or curse you, as the choice directly shapes their workload and how quickly your analytics pipeline can adapt to change.
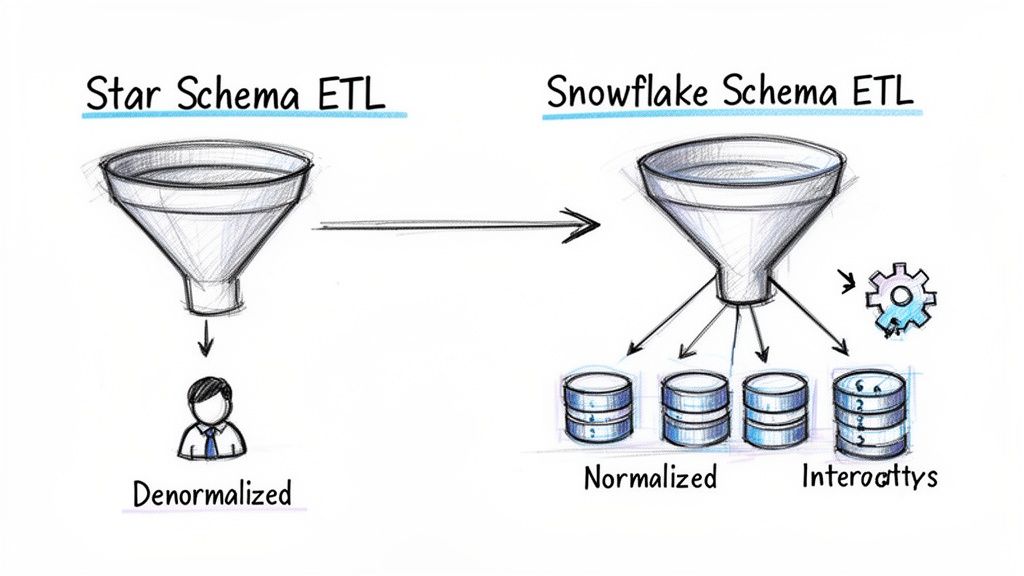
The Star Schema ETL Process
With a star schema, most of the heavy lifting happens in the transformation stage. Data engineers have to write the logic to denormalize the data, which means pre-joining source tables to build those wide, flat dimension tables. This is where a lot of business logic gets baked directly into the ETL code.
While this means more work upfront, the payoff comes during the load. The ETL job is beautifully simple: it just has to push data into one fact table and a few dimensions. It's a straightforward process that’s easier to debug and monitor because there are fewer moving parts.
The Snowflake Schema ETL Process
A snowflake schema, on the other hand, flips this dynamic. The transformation logic is much simpler because the dimension tables remain normalized, often closely mirroring the source systems. You don't need complex pre-joining logic.
The complexity shifts to the loading process. Now, the ETL job has to populate a web of interconnected tables, all while meticulously managing their referential integrity. If a job fails to load a small sub-dimension table, it can trigger a cascade of failures, preventing the main dimensions and fact table from loading correctly.
The core trade-off is this: A star schema puts the complexity into the transformation step to make loading and querying simple. A snowflake schema simplifies the transformation, but you pay for it with a more fragile loading process and more complex queries.
Long-Term Maintenance And Updates
This is where the structural differences can cause real-world pain or provide welcome relief.
Star Schema Maintenance: Updating attributes can be a major headache. If a "Product Category" name changes, your ETL process has to find and update every single row in the
Dim_Producttable that uses that category. This design is prone to update anomalies, especially when dealing with slowly changing dimensions. If you're managing historical data, our guide on implementing Slowly Changing Dimensions offers some practical strategies for this.Snowflake Schema Maintenance: Here, the normalized structure shines. To change a category name, you only update a single row in the
Dim_Categorytable. This high level of data integrity makes the snowflake model much cleaner and safer to maintain over the long run.
But that ease of maintenance isn't free. The sheer number of tables in a snowflake schema can become its own bottleneck. It demands more thorough documentation just so analysts can figure out the relationships, and it often requires more specialized data engineers to manage the intricate data flows, which can slow down new development.
Frequently Asked Questions
When you get into the weeds of data modeling with star and snowflake schemas, a few key questions always pop up. Let's tackle them head-on, based on what we see happening in the real world.
Can You Use A Hybrid Approach Combining Both Schemas?
Absolutely. In fact, you’d be hard-pressed to find a large organization that doesn’t use a hybrid model. It’s an incredibly common and practical strategy. Most data teams will build a star schema for the data marts that get hit the most, making sure core business dashboards and self-service tools are as fast as possible.
At the same time, they might introduce a snowflake schema for certain complex domains. This is perfect for areas with deep, multi-level hierarchies (like product categories or geographical regions) or where strict data integrity and storage efficiency are non-negotiable. This approach isn't about compromise; it's about matching the right architecture to the right job.
How Do Cloud Data Warehouses Affect The Choice?
Modern cloud platforms like Snowflake, BigQuery, and Redshift have completely changed the game. Their architecture, which separates storage from compute, has made storage costs a much smaller part of the equation. This one shift dramatically weakens one of the main historical arguments for the snowflake schema.
Cloud data warehouses have definitely tipped the scales in favor of the star schema. While their powerful query engines can chew through the extra joins of a snowflake model better than ever, the star schema's simplicity and raw query speed still make it the go-to for most analytical workloads.
Is One Schema Better For Self-Service Analytics?
When it comes to empowering your team with self-service analytics, the star schema wins, hands down. Its structure is just far more intuitive for business users, analysts, and anyone who isn't a data engineer. The model—a central fact table surrounded by descriptive dimensions—dramatically lowers the learning curve.
This simplicity is what makes or breaks a self-service initiative. It reduces the constant back-and-forth with the data team for every little report, freeing everyone up to do more meaningful work.
When Should You Evolve From A Star To A Snowflake Schema?
You should only think about evolving parts of your model to a snowflake schema when you hit very specific pain points. This move is usually triggered when:
A dimension table gets so massive and full of redundant data that storage costs actually start to become a real problem again.
You're trying to manage extremely complex, multi-level hierarchies that are becoming a nightmare to maintain in a flat, denormalized star schema.
Keep in mind, this is rarely an all-or-nothing decision. What usually happens is that teams will selectively "snowflake" a single, problematic dimension while leaving the rest of the model as a clean and simple star schema.
At Querio, we believe data exploration should be fast and flexible, no matter your schema. Our AI coding agents work directly on your data warehouse, empowering your entire team to query, analyze, and build on company data without creating bottlenecks for analysts. Replace outdated BI tools and scale your data team's impact. Discover how Querio enables true self-service analytics.

