Nested Select Queries: Optimize & Master Subqueries
Master nested select queries (subqueries). Learn optimization, correlated vs. uncorrelated types, and rewrites using JOINs & CTEs for peak performance.
https://www.youtube.com/watch?v=TUxadt94L0M
published
Outrank AI
nested select queries, sql subqueries, sql optimization, data analytics, querio
3f5f9d85-8ce0-4e5c-a5d0-6eb864200e7d

A product manager sends a message at 4:40 p.m. They need a list of users who signed up last quarter, belong to a specific plan, and have engagement above the average for their own cohort. The question sounds simple until you try to write it.
You can’t answer it with one flat filter. You need one result to calculate another. First find the cohort average. Then compare each user against it. That’s the moment nested select queries become useful.
Many teams learn subqueries as syntax. They learn where the parentheses go, how IN works, and how to return a scalar value. Then they hit production data and discover the hard part isn’t writing the query. It’s knowing whether the query will behave well when the table is large, the schema is messy, and a self-service user runs it against live warehouse data.
That gap is real. Documentation mentions that nested queries can be slow, especially when they run for each row in the outer query, but practical guidance on performance trade-offs is thin, a factor especially important in self-serve analytics environments where non-technical users need efficiency without deep database expertise (Codefinity on nested query optimization gaps).
Good SQL teams don’t just ask, “Does this return the right answer?” They ask, “Is this the right pattern for the warehouse, the workload, and the people who will maintain it?”
Your Data Has the Answer If You Ask Correctly
Nested select queries solve a common analytics problem. You need an answer from one query before you can ask the next question.
Take a startup with three core tables:
userscohortsengagement_events
A Head of Product wants to identify users whose engagement is above the average for their own signup cohort. That request has two layers. You need the cohort average, then you need the users above it.
A nested query handles that effectively.
Why teams reach for subqueries
A subquery lets you write a question within a question. That’s cleaner than exporting data into a spreadsheet, creating temp tables, or splitting the task into several manual steps.
For example, if you want all users on premium plans, you can ask the inner question first:
The inner query produces a set of plan_id values. The outer query uses that set as a filter.
That pattern feels intuitive because it matches how people reason. First identify the qualifying group. Then pull the records.
Where people get stuck
Confusion starts when readers see that some subqueries run once, while others run again and again during execution.
That difference matters more than syntax.
Nested queries are easy to read at first glance. The hard part is knowing what the database has to do behind the scenes to execute them.
For analytics teams, that distinction affects dashboard latency, notebook responsiveness, and the quality of self-service SQL generated by internal tools.
A practical mindset
When I mentor teams, I frame subqueries this way:
Use them to express logic clearly
Inspect whether the inner query depends on the outer row
Rewrite when repeated execution becomes expensive
That mindset keeps SQL readable without treating readability and performance as opposites. They aren’t. The strongest teams write queries that explain the business question clearly and respect how modern warehouses execute work.
Understanding Nested Select Queries
A nested select query is a SELECT statement inside another SQL statement. You’ll hear it called a subquery.
If you remember one mental model, use this one: the inner query gathers context, and the outer query uses that context to return the final result.
A simple way to think about it
Suppose your company has multiple offices. You want the employees in the New York office, but your employees table stores office_id, not office names.
You can ask two questions in one query:
The inner query finds the office ID. The outer query finds the employees with that ID.
This is easier to read than writing two separate queries by hand and copying values across.
Common places subqueries appear
Nested select queries can sit in several parts of a statement. Each placement changes how the result is used.
In the WHERE clause
This is the most familiar pattern. The subquery acts like a filter.
Use this when the inner query returns values that decide which rows the outer query keeps.
In the FROM clause
Here, the subquery behaves like a temporary result set. People call this a derived table.
This is useful when you want to aggregate first, then query the aggregate.
In the SELECT clause
This form returns a single value for each row, often for labeling or side-by-side comparison.
This can be readable on small problems, but it’s a place where performance issues can creep in if the lookup repeats row by row.
Two rules that save people trouble
Scalar subqueries must return one value. If the database expects one value and gets many, the query fails.
Aliases matter. Once you nest a query in
FROM, give it a clear alias so the outer query can reference it.
Practical rule: If your nested query feels like “find a list, then filter by that list,” you’re in good shape. If it feels like “look something up again for every row,” slow down and inspect it.
For analysts who use modern SQL, it helps to learn when a window function would express the same idea more directly. This walkthrough on window functions in SQL is worth keeping nearby because many “compare this row to a group average” problems fit both patterns.
Uncorrelated vs Correlated Subqueries
A self-service analytics team often hits this fork early. One query pattern asks the warehouse for a reusable answer once. The other asks it to recalculate context for each row.
That difference affects both readability and runtime.
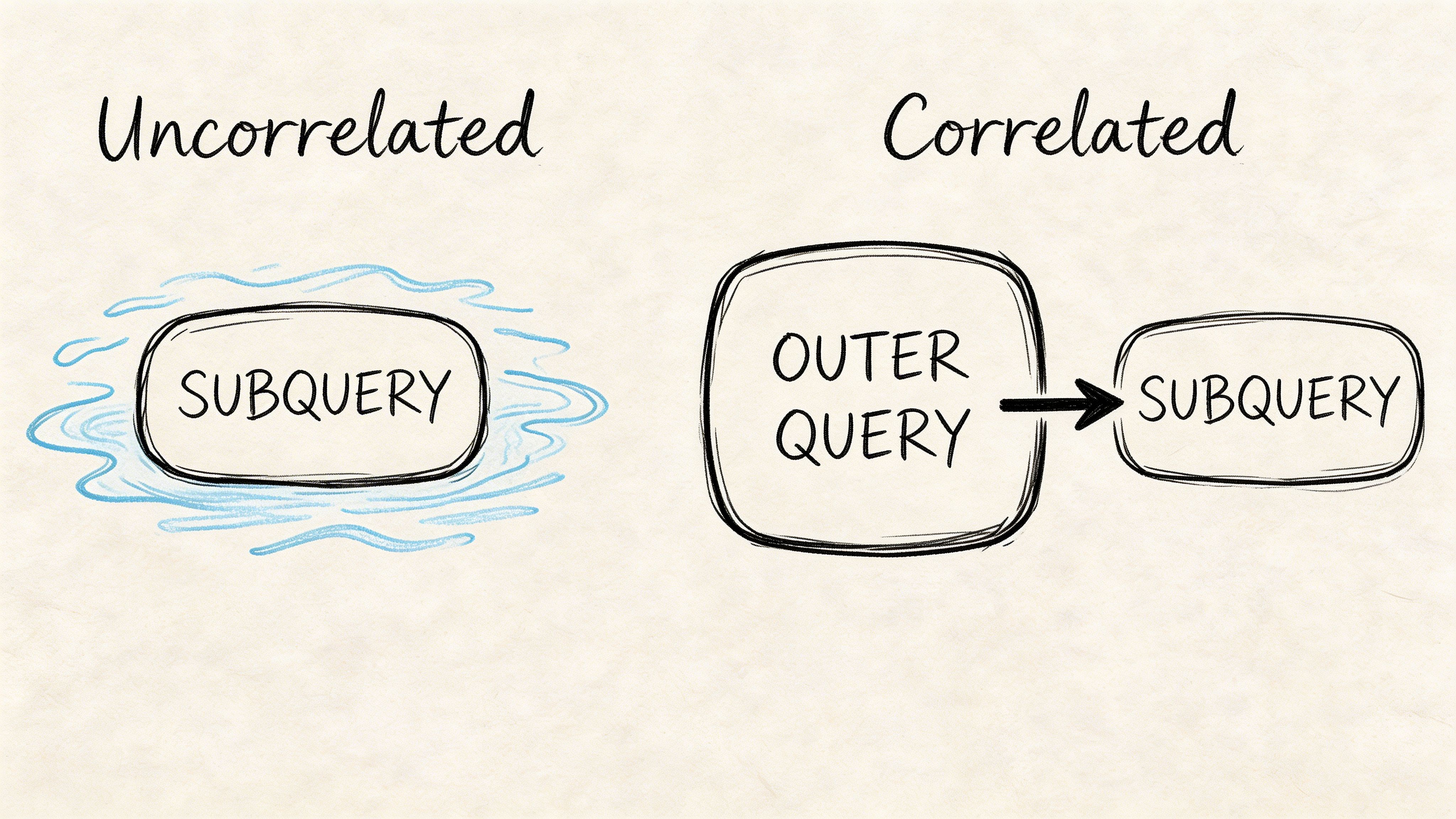
Uncorrelated subqueries
An uncorrelated subquery is independent. You can run the inner query on its own, inspect the result, and then use that result in the outer query.
It works like preparing a shortlist before a meeting. You decide the criteria once, then everyone works from the same list.
The inner query has no reference to users. It returns a set of annual plan IDs, and the outer query filters against that set.
For analysts, this pattern is easier to test. You can validate the inner result first, confirm that the right IDs came back, and only then plug it into the full query.
Correlated subqueries
A correlated subquery depends on the current row from the outer query. The inner query cannot stand alone because part of its logic comes from outside it.
A practical way to spot one is to look for an outer alias inside the subquery.
The condition u2.cohort_id = u.cohort_id creates the dependency. For each user row, the database finds that user’s cohort, calculates the cohort average, and compares the current user against it.
This reads close to the business question. “Show me users performing above their cohort average.” That clarity is why correlated subqueries appear so often in analyst-written SQL.
Why performance can diverge
The trade-off is execution cost.
An uncorrelated subquery often behaves like a reusable lookup. A correlated subquery can behave like a repeated calculation tied to each outer row. Modern warehouses sometimes optimize that pattern well, but they do not always do so, especially when the logic is more complex or the filters are not selective.
For a startup team working in a notebook, that difference matters. A query that feels fine on a few thousand rows can slow down once product usage, event volume, or customer history grows. The SQL still looks correct. The warehouse bill and wait time tell a different story.
A faster rewrite pattern
Correlated subqueries are not wrong. They are often just a first draft.
If the business question is “compare each row to a group statistic,” a window function expresses that intent more directly and gives the optimizer a cleaner plan:
You can also rewrite the same logic with a CTE that calculates cohort averages once, then joins back:
For self-service teams, these rewrites have two advantages. They often run more predictably, and they make the transformation steps easier to explain in a shared Querio notebook.
How to identify the pattern quickly
Use a simple review habit before you run a large query:
Run the inner query by itself. If it works without any outer reference, it is uncorrelated.
Scan for outer aliases inside the subquery. If you see one, it is correlated.
Listen to the business wording. Requests that start with “for each user,” “for each account,” or “within their segment” often lead to correlation.
Check whether a join, CTE, or window function states the logic more directly.
This matters even more in schemas with layered joins across users, accounts, subscriptions, and events. Clear table relationships reduce both logic mistakes and rewrite effort. A quick refresher on relationships in relational databases helps when you are deciding whether a subquery should stay as-is or become a join.
Side-by-side comparison
Here is the contrast in one glance.
Uncorrelated
Correlated
The first query asks for one reusable set of cohort IDs. The second asks for a row-specific comparison.
That is the decision point to teach junior analysts. If you need one shared answer, an uncorrelated subquery is often fine. If you need a per-row calculation, start by asking whether a correlated subquery is the clearest version, or whether a CTE or window function will be easier to maintain once your dataset gets bigger.
Running Subqueries in a Querio Notebook
A product team doesn’t ask for “an uncorrelated subquery.” They ask for a list of customers worth attention.
A common startup request sounds like this: find users on paid plans, then flag the ones whose monthly login count is above the average for their subscription tier.

Assume you have these tables:
usersplansmonthly_user_activity
The first task is simple. Pull users on premium plans.
Example one with an independent subquery
This works well for self-service analysis because the business logic is visible in one place. You don’t need to remember internal IDs for each plan.
In a notebook workflow, the result feeds directly into a grid, then into a chart or follow-up question from the PM.
Example two with a correlated subquery
Now move to a richer question. Which users logged in more than the average for their own subscription tier this month?
This query is readable because it mirrors the business request. “Compare each user’s login count to the average login count for users on the same plan in the same month.”
That’s why analysts write it this way first.
When you’re exploring a question for the first time, clarity often matters more than cleverness. Start with a query you can explain out loud.
A notebook is a good environment for that first pass because you can inspect intermediate outputs, annotate assumptions, and save the query beside the analysis that motivated it.
A video walkthrough can also help if your team is learning notebook-based warehouse workflows:
What a team should check before sharing results
Before you pass a subquery-backed result into a product review or leadership update, validate three things:
Date grain Make sure the subquery and outer query use the same month, week, or day logic.
Population alignment If the outer query filters to paid users but the average includes free-tier users, the comparison is wrong.
Null behavior Missing activity rows can exclude users or distort averages.
That notebook habit matters because nested select queries can hide mistakes in otherwise valid SQL. The query runs. The result looks reasonable. The business interpretation is still off.
When to Rewrite Nested Queries for Performance
A correlated subquery can feel fine in development. Then someone points it at a large warehouse table and the query stalls, scans too much data, or monopolizes compute.
That’s the moment SQL style turns into systems design.
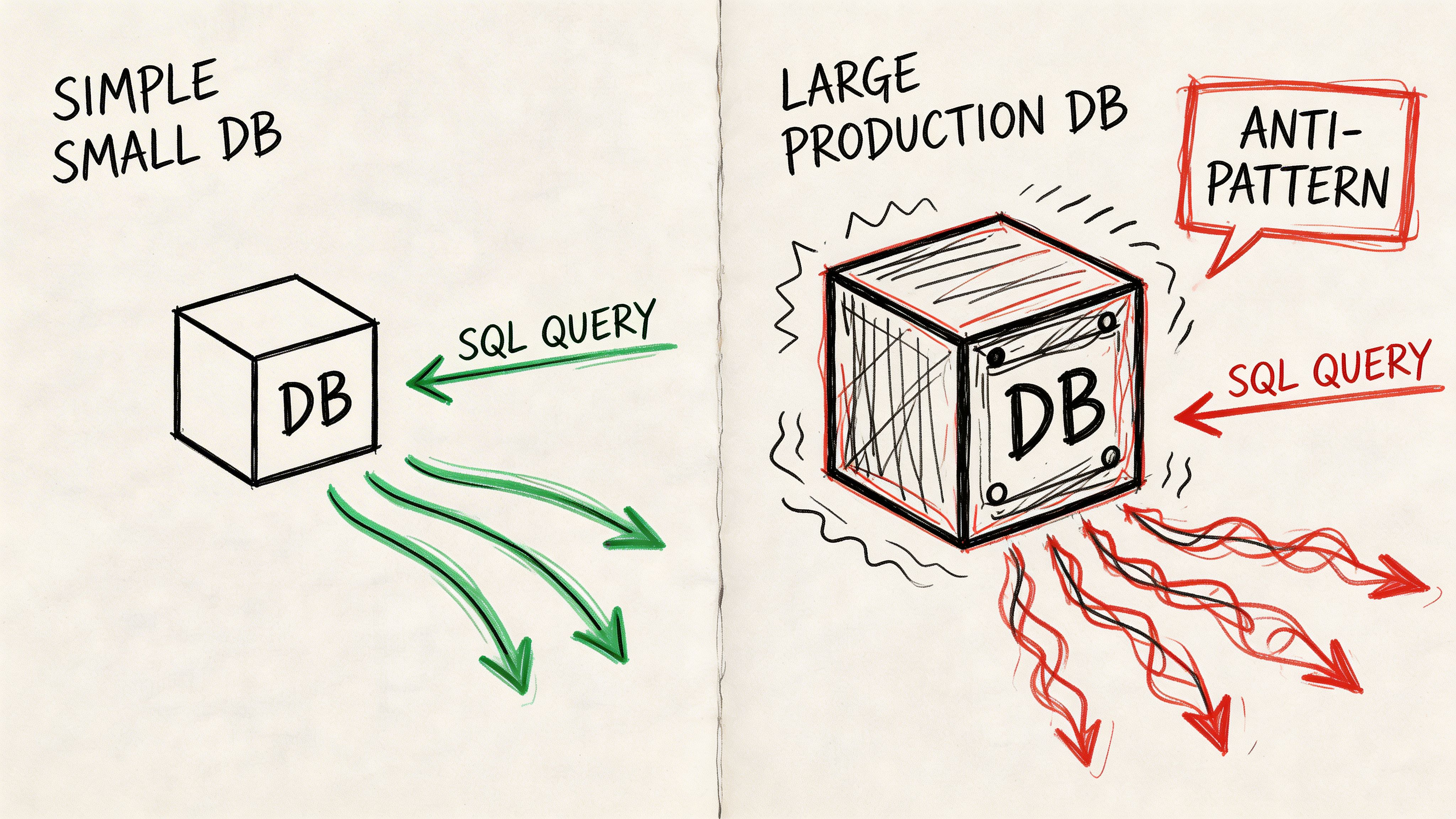
The warning sign to watch for
In SQL Server, correlated subqueries can cause O(n^2) degradation on large tables, and Microsoft benchmarks show 10 to 50 times slowdowns versus JOINs on AdventureWorks datasets. The same source notes that rewriting with CTEs or window functions can cut execution time by 70 percent in mid-market analytics environments (Microsoft subquery performance guidance).
You don’t need to memorize the formal complexity term to act on it. The practical signal is easier:
the inner query references the outer row
the outer table is large
the logic computes an aggregate or lookup repeatedly
That combination deserves scrutiny.
A slow version of the power user query
Suppose you need users whose engagement score is above their cohort average.
It’s readable. It’s a classic candidate for rewrite.
Rewrite option one with a JOIN
Precompute the cohort average, then join it back.
This works well when the aggregated result is small and reusable. The warehouse can optimize it more predictably than a correlated expression.
Rewrite option two with a CTE
A CTE improves legibility when you want named steps.
This pattern is easier for teams to maintain because the business concept gets a name. Instead of decoding nested parentheses, a reviewer can read cohort_averages and move on.
If your team wants a practical checklist for query review, this guide on how to optimize SQL queries is a useful companion.
Rewrite option three with a window function
A window function expresses “compare each row to its group” most directly.
This is the version I recommend for analytics work when the question is row-versus-group comparison.
Why? Because the logic stays in one pass of the dataset. You aren’t mentally jumping between outer and inner scopes. You can read the partition key and see the grouping rule.
How to choose among them
Use a rewrite based on the shape of the business problem, not on habit.
Pattern | Best For | Performance | Readability |
|---|---|---|---|
Subquery | Straightforward filtering and one-off logic | Fine for simple independent lookups. Risky when correlated on large tables | Intuitive at first |
JOIN | Reusing lookup or aggregate results across many rows | Often stronger for large datasets and optimizer-friendly plans | Clear once aliases are named well |
CTE | Multi-step logic that benefits from named intermediate results | Often similar to JOIN-based rewrites, depends on engine behavior | High for teams reviewing shared SQL |
Window Function | Row-to-group comparisons, rankings, moving aggregates | Often strong for analytical comparisons | Very high once the team understands |
A practical rewrite test
When I review SQL for self-service environments, I use this short decision test:
Keep the subquery if the inner result is independent and the logic is easiest to express that way.
Use a JOIN when you’re matching against a reusable set or aggregate.
Use a CTE when the team needs named steps for debugging and review.
Use a window function when each row needs context from its group.
For platform teams working on governed self-service, tooling also matters in this context. Teams inspect plans manually in dbt, warehouse consoles, or notebook environments. Some centralize this workflow in tools like Querio’s query optimization guidance, where generated SQL can be reviewed and rewritten before it spreads into repeated usage.
Design advice: Don’t reward SQL that is merely short. Reward SQL that explains the business rule and respects the execution model.
How Modern Data Warehouses Handle Subqueries
Your team ships a dashboard for weekly revenue, and it works fine at 50,000 rows. Three months later, finance runs the same logic against hundreds of millions of events in BigQuery or Snowflake, and the query that felt harmless now burns minutes and budget. The SQL did not change. The execution conditions did.
Modern warehouses do not read a nested query like a person reading top to bottom. They parse the statement, build an execution plan, and look for safer or cheaper ways to produce the same result. A subquery that looks nested on the page may be flattened, merged into a join strategy, or turned into an internal temporary result.
That behavior helps self-service teams, but only up to a point.
What warehouses optimize well
Independent subqueries are the easiest case. If the inner query can be computed once, the planner can treat it like a reusable input instead of reevaluating it row by row. Simple filters, clear join keys, and predictable aggregations also give the optimizer room to choose a better plan.
A good mental model is a warehouse loading pallets in a distribution center. If every box is labeled and grouped correctly, the forklifts can reroute work fast. If boxes arrive half-labeled and mixed together, people start opening cartons by hand.
That is why modeling choices matter alongside SQL shape. Teams working through broader data warehouse architecture decisions see this firsthand. Partitioning, clustering, and clean grain definitions often determine whether a nested query stays cheap or turns into repeated large scans.
Where query planners still struggle
Trouble starts when the outer query changes how the inner query behaves for every row. Correlated logic can force repeated lookups. Scalar subqueries can hide expensive assumptions. Several layers of nesting can also make a plan harder to reason about, even when the SQL reads cleanly to an analyst.
For self-service analytics teams, this is the practical risk. A query can be logically correct, pass review, and still be expensive enough to slow shared workloads in Querio notebooks or warehouse consoles.
Read the plan, not just the SQL
EXPLAIN is how you check what the engine decided to do.
When a nested query runs slower than expected, inspect the plan for:
repeated scans on the same large table
nested loop joins against large row counts
materialized intermediate results
filters applied later than you expected
subqueries that were preserved instead of flattened
Those clues tell you whether the warehouse helped or whether your team still needs to rewrite the query.
A startup example
Suppose a growth team wants all accounts whose latest monthly spend is above their segment average. The first version arrives as a layered subquery because that matches the business question.
A modern warehouse may optimize parts of this. It may also keep the row-dependent logic intact, especially at large scale. For a startup with rapidly growing event volume, query cost becomes significant. The warehouse is doing its job, but it is still constrained by the shape you gave it.
Upstream setup matters too. Teams integrating data with BigQuery learn that ingestion patterns, table design, and partition strategy directly affect how well these plans perform.
The practical lesson is simple. Trust the optimizer to help. Do not assume it can rescue every nested pattern once your self-service analytics workload grows.
Conclusion: Enabling True Self-Service Analytics
Nested select queries matter because they match how people think about business questions. Find one thing. Use it to answer another. That’s a natural pattern for product analytics, finance reporting, and customer behavior analysis.
The problem isn’t the syntax. The problem is stopping at syntax.
Teams get more value from SQL when they can tell the difference between an independent subquery that’s easy for the warehouse to optimize and a correlated subquery that may become expensive under load. That judgment is what turns a query writer into a reliable analytical operator.
A strong self-service culture depends on that judgment. Product managers and founders need the freedom to ask layered questions without waiting in a queue. Data teams need confidence that shared patterns won’t create performance headaches.
That’s why modern alternatives matter. JOINs help when you want to reuse a computed set. CTEs help when the team needs named, reviewable steps. Window functions express row-versus-group logic more cleanly than nested queries.
The mature approach isn’t “never use subqueries.” It’s “use them with intention.”
When a team understands nested select queries, they start asking better questions and writing SQL that scales with the company. They create a healthier relationship between business users and the warehouse. Analysts spend less time rescuing ad hoc work. Data engineers spend less time untangling slow patterns after they spread.
That’s the ultimate win. Not faster queries alone. Better shared thinking about how data questions should be asked.
If your team wants a practical way to turn complex warehouse questions into notebook-based analysis without routing every request through analysts, Querio is worth a look. It uses AI coding agents directly on the data warehouse and supports Python notebooks, SQL generation, and collaborative self-service workflows for both technical and non-technical users.

