Case statement in sql with examples: Case Statement in SQL w
Master the CASE statement in SQL with examples for analytics. Learn syntax, conditional logic, segmentation, and KPIs across data warehouses.
https://www.youtube.com/watch?v=Twusw__OzA8
published
Outrank AI
case statement in sql, sql examples, sql conditional logic, data analytics, sql for data science
3f8d9562-d532-453e-8295-5628e8b9bb7f

Your product manager needs a user engagement report before the afternoon sync. Not tomorrow. Not after the analytics team has time to build a model. Today.
They want users grouped into buckets like “Power User,” “Active,” “Occasional,” and “Churn Risk,” based on behavior that doesn’t live in one neat column. Login frequency matters. Feature usage matters. Maybe plan type matters too.
Without CASE, teams often solve that request the hard way. They run multiple queries, export to Sheets, add manual labels, then spend the next week arguing about why the numbers changed. That’s the kind of reporting work that turns a data team into a ticket queue.
A good case statement in sql with examples shows why this feature matters so much. CASE lets you encode business logic directly in the query that already touches the data. It keeps classification, aggregation, and reporting in one place. That’s why experienced analysts reach for it constantly, especially in cloud warehouses where every extra scan and every messy workaround costs time.
Why the SQL CASE Statement is Your Analytics Superpower
A CASE statement is the practical fix for “Can you just bucket this data for me?” requests.
Suppose your Head of Product asks for a weekly table of user segments. They don’t want raw events. They want labels the business can use in a meeting. Something like this:
Power User for highly engaged users
Active for regular users
Occasional for low-frequency users
Churn Risk for users fading out
That logic belongs close to the data, not in a spreadsheet after the fact.
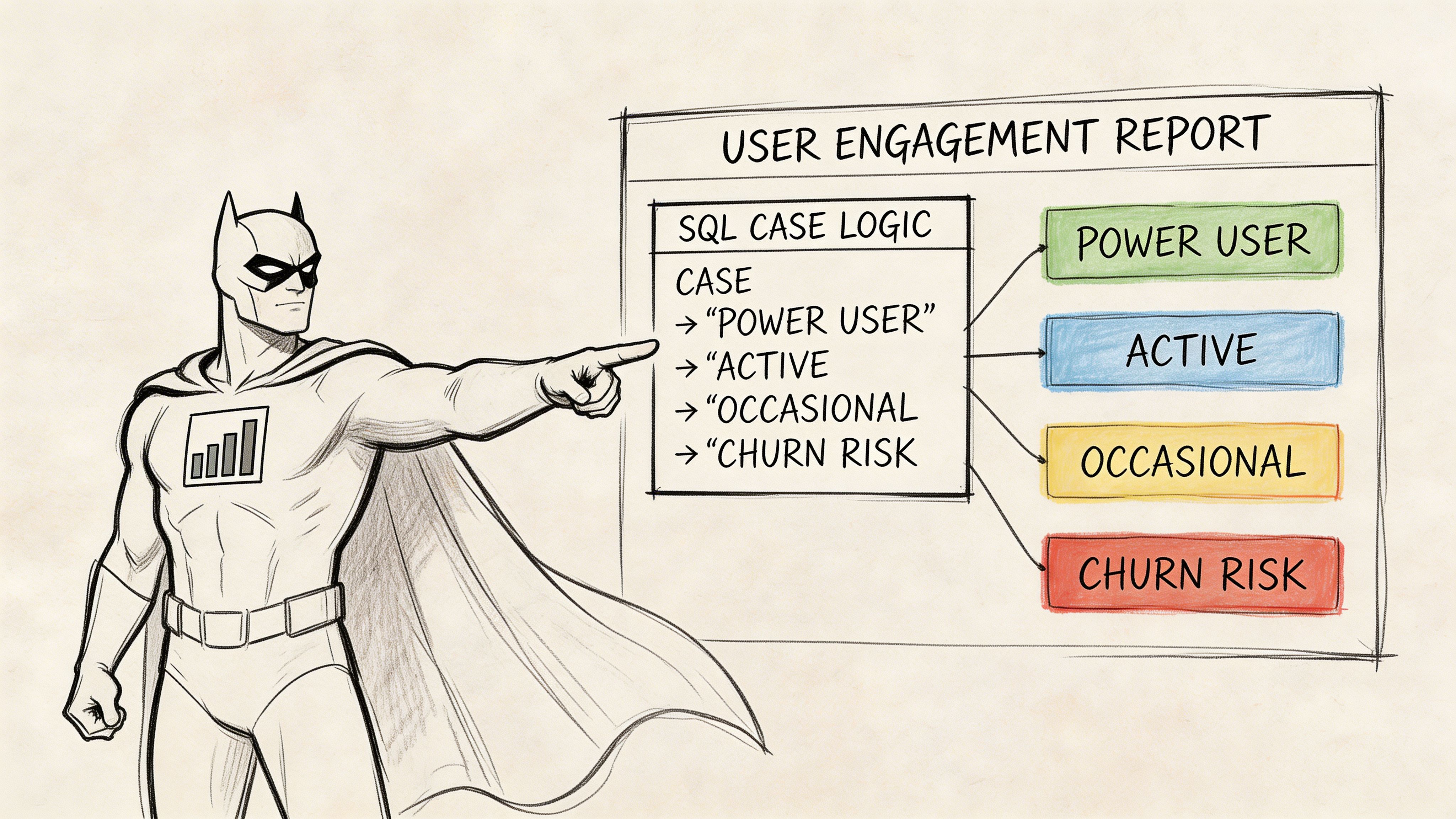
A real reporting pattern
Here’s a simple version:
That’s the difference between raw telemetry and a report a PM can use.
Before CASE became standard, analysts often had to rely on vendor-specific tricks or multiple UNION queries. The SQL CASE statement was introduced as part of the ANSI SQL-92 standard in 1992, and one cited summary notes that by 2026, over 90% of SQL usage in major markets involves CASE in production queries for self-serve analytics (dbvis guide to the SQL CASE statement).
Why this matters for self-serve work
A strong CASE statement does three jobs at once:
It standardizes business logic so “active user” means the same thing across reports.
It reduces analyst handoffs because product and ops teams can read the query output directly.
It keeps logic versioned in SQL instead of buried in slide decks or spreadsheet formulas.
Practical rule: If a business stakeholder keeps asking for the same classification, move that logic into SQL with
CASEbefore it spreads into five conflicting definitions.
That’s why CASE feels less like syntax and more like a powerful tool.
Understanding CASE Syntax Simple vs Searched
There are two forms of CASE, and choosing the right one makes queries easier to read and sometimes faster to run.

Simple CASE for direct matches
Use simple CASE when one expression is being matched against a set of values.
This is the cleaner option when your logic is basically “if this value equals X, return Y.”
Consider it a switch. One input. Several possible direct matches.
A common reporting use case is mapping codes to labels:
Searched CASE for business rules
Use searched CASE when each branch has its own condition.
This version is more flexible because each WHEN can evaluate a different boolean expression. You can compare multiple columns, combine conditions, and build logic that reflects how teams think about customers, products, and revenue.
For analytics, searched CASE is the one you’ll use more often:
First match wins
CASE evaluates conditions in order and returns the first match.
That means order matters.
This works because high spend is checked first. Reverse the order and every value above 1000 would already match the >= 500 rule.
Put your most specific logic first. Broad rules belong lower in the statement.
When to use which
A quick decision table helps:
Situation | Better choice | Why |
|---|---|---|
Mapping one code to one label | Simple CASE | Cleaner and easier to scan |
Bucketing by ranges | Searched CASE | Each bucket needs its own condition |
Multiple columns in logic | Searched CASE | Simple CASE can’t express that cleanly |
Equality checks on one indexed field | Simple CASE | Often more efficient |
One cited summary says searched CASE evaluates boolean conditions sequentially, while simple CASE compares a single expression to literal values. It also notes 10-15% better performance for simple CASE in high-cardinality scenarios and says simple CASE can be 2x faster than searched CASE on indexed varchar columns in certain MySQL 8.0 analyses (Codecademy article on the SQL CASE statement).
A small habit that saves debugging time
Always include an ELSE unless you explicitly want NULL.
Without ELSE, unmatched rows return NULL. Sometimes that’s correct. Often it just creates a silent reporting problem you discover later in a dashboard filter.
Building Dynamic Reports with CASE Statement Examples
Teams often seek solutions to business problems rather than more syntax examples.
Segment customers by lifetime value
A classic request from finance or growth is customer tiering.
That looks simple, but it solves a real reporting problem. Teams can now group retention, support load, and expansion performance by a stable business segment instead of raw revenue values.
You can push it one step further and aggregate immediately:
That’s often enough for a board slide or growth review.
Flag a product cohort inside the query
Product teams ask questions like, “Which recently acquired users adopted the new feature?”
CASE lets you turn that question into a reusable flag.
That pattern is useful because it avoids creating separate temp tables just to define a cohort.
If you want more practical SQL reporting patterns, this complete guide to top 10 SQL queries for analytics is a useful companion.
Build a health score people can read
Executives rarely want three raw metrics side by side. They want a label that points to action.
Suppose you have account usage data with logins, support tickets, and feature adoption. You can turn that into a first-pass health score:
This isn’t a machine learning model. It doesn’t need to be. For many operating reviews, a transparent rule set is better because everyone can inspect it and challenge it.
A readable
CASEstatement beats a mysterious score that nobody trusts.
Here’s a short walkthrough if you want to see how analysts explain conditional logic in practice:
What works well in production
Three habits make these examples hold up in real reporting work:
Name categories in business language. “At Risk” is better than “bucket_3.”
Keep thresholds reviewable. Store them in the query or model where teams can inspect them.
Use
CASEfor interpretation, not raw cleanup. If the source data is broken, fix that upstream first.
What usually goes wrong
Analysts often overpack one CASE block with every exception the company has ever invented.
That creates brittle logic. If your labels depend on many intermediate checks, split the query into CTEs and calculate helper fields first. CASE works best when each branch expresses one clear business rule.
Advanced Analytics with Conditional Aggregation
Conditional aggregation is where CASE stops being convenient and starts becoming a serious analytics tool.
You use it when you need one summary table to answer several questions at once. Instead of running separate queries for online sales, retail sales, and total sales, you can calculate all three in one pass.
The core pattern
That query behaves like a small pivot table inside SQL.
For counts, the pattern changes slightly:
COUNT(CASE WHEN ... THEN 1 END) works because unmatched rows return NULL, and COUNT ignores NULL.
Why analysts use this constantly
A lot of business reporting is really just “count or sum this subset, then compare it with that subset.”
Conditional aggregation handles:
Channel splits such as online vs retail
Lifecycle reporting such as active vs inactive accounts
Cohort summaries such as new users who adopted a feature
Operational dashboards such as tickets by severity or status
The alternative is usually worse. You either write several subqueries, self-join the same table, or push the reshaping into Excel or BI tooling.
One cited benchmark summary says that on PostgreSQL 15+, CASE-based pivots execute 20-40% faster than equivalent self-joins on tables with 10M+ rows because they reduce table scans to a single pass (Intellipaat article on CASE in SQL).
Grouping on computed buckets
You can also use CASE inside GROUP BY to build segments on the fly:
If you want a stronger foundation for grouping logic before you stack conditional aggregates on top, this guide to the GROUP BY clause for advanced analytics is worth reviewing.
Windowed summaries pair well with CASE too. If you’re building rolling or partitioned metrics, this overview of SQL window functions is a good next read: https://querio.ai/blogs/window-functions-sql
The senior analyst move isn’t writing more queries. It’s getting more answers out of one scan.
What this solves in cloud warehouses
In Snowflake, Redshift, BigQuery, and similar platforms, query shape matters. Re-reading a large fact table multiple times adds latency and cost. Conditional aggregation helps because it keeps the logic centralized and usually cuts down the number of scans.
It’s also more maintainable. One query with well-named calculated columns is easier to review than five separate queries stitched together in a dashboard tool.
Optimizing Your CASE Statements for Performance
A correct CASE statement can still be expensive.
That matters more in cloud warehouses because performance and cost usually move together. If your segmentation logic sits inside a dashboard query that runs all day, small inefficiencies stop being small.
Order conditions with intent
CASE returns the first matching branch. That means branch order affects work done.
If your most common category appears early, the database can stop evaluating later conditions for those rows. That’s especially useful in searched CASE logic with expensive expressions.
Bad pattern:
If most rows are free users, you’ve put the common branch second.
Better pattern:
Keep return types consistent
Don’t mix numeric and text outputs in one CASE unless you know exactly how your warehouse will coerce them.
This is risky:
Keep all THEN and ELSE values aligned by type. If you need both a machine-friendly field and a display label, create two separate expressions.
Know when FILTER is better
A lot of teams default to COUNT(CASE WHEN ...) forever, even when their database gives them a better option.
One cited summary notes that interest in CASE versus FILTER performance surged, with Google Trends for that comparison up 150% in the last 12 months. The same summary says unoptimized CASE-based pivots can scan 2.7x more data, while alternatives like PostgreSQL’s FILTER clause can cut latency by 60% by enabling index-only scans (ThoughtSpot SQL CASE tutorial).
For example, instead of:
PostgreSQL supports:
That doesn’t mean FILTER is always the winner. Dialect behavior differs, and many warehouses still optimize CASE well. But if you’re working in PostgreSQL and counting many categories, it’s worth testing both versions with EXPLAIN.
If your team is actively tuning heavy warehouse queries, this walkthrough on query optimization is useful: https://querio.ai/blogs/optimizing-a-query
A short checklist before you ship
Check branch order when one category dominates the data.
Avoid repeated expressions inside several
WHENclauses. Compute once in a CTE if needed.Benchmark alternatives like
FILTERwhere your dialect supports them.Inspect the execution plan before assuming the cleanest-looking query is the fastest.
Cloud SQL performance rewards skepticism. Test, don’t guess.
Common Mistakes to Avoid with CASE Statements
Most broken CASE logic isn’t broken because of syntax. It’s broken because the query became hard to reason about.
Nested CASE gets ugly fast
Analysts often keep nesting until the statement looks like a logic puzzle.
That usually starts with good intent. One exception becomes three. Then region-specific logic appears. Then sales wants one extra override. Soon the query is unreadable.
A cited summary notes that nested CASE queries in SQL tags spiked 35% YoY in 2025, with 68% of top-voted questions unresolved due to performance pitfalls. It also says unoptimized nesting can cause 5-10x slowdowns on datasets above 1M rows (Microsoft documentation page cited in the verified data).
If you can’t explain a
CASEblock out loud in under a minute, refactor it.
Better ways to handle complexity
Instead of one giant nested expression, try this:
Use CTEs for intermediate logic. Create helper columns first, then apply a simpler final
CASE.Separate classification stages. For example, derive usage tier first, then derive account health.
Move stable business rules upstream. If every dashboard needs the same logic, model it once.
Two smaller mistakes that cause real problems
One is forgetting how NULL behaves.
If churn_date is NULL, the comparison won’t be true. That may be correct, or it may hide missing data. Be explicit when NULL has business meaning.
The other is omitting ELSE unintentionally. That returns NULL, which can inadvertently break grouping, filtering, or chart labels later.
A clean CASE statement should be readable, testable, and boring. Boring is good. Boring queries survive handoffs.
Integrating CASE into Your Self-Serve Analytics Workflow
CASE is one of the features that turns SQL from data retrieval into decision support.
When teams can classify customers, bucket usage, and build report-ready metrics directly in queries, they stop waiting for one analyst to translate every business question into a dashboard change. That’s the foundation of self-serve analytics. Shared logic lives in the warehouse, not in private spreadsheets.
In practice, that means using CASE for reusable segments, conditional KPIs, and clear business labels that non-technical teammates can understand. If you’re building that kind of operating model, this overview of self-serve analytics is a useful reference: https://querio.ai/blogs/self-serve-analytics
Used well, CASE doesn’t just clean up SQL. It removes reporting bottlenecks.
If your team is buried in ad hoc reporting and repetitive warehouse queries, Querio is one option to evaluate. It deploys AI coding agents directly on the data warehouse and uses notebook-style workflows so teams can build and reuse analytics logic, including SQL patterns like CASE, without pushing every request through a central analyst queue.

