How to Write SQL Queries a Practical Guide for 2026
Learn how to write SQL queries from basic SELECT statements to advanced window functions. This practical guide covers joins, aggregation, and performance tips.
https://www.youtube.com/watch?v=G3lJAxg1cy8
published
Outrank AI
how to write sql queries, sql tutorial, learn sql, sql for data analysis, sql basics
d37c33c0-5f04-4b98-8c16-b3a5245fb775

You probably know the situation. You need one number for a product review, a board update, or a customer conversation. The data exists somewhere in the warehouse, but getting it means opening a ticket, explaining the metric, waiting for context switching on the data team, then revising the request when the first cut isn't quite right.
That delay isn't just annoying. It changes how teams work. People ask fewer questions, decisions get made on partial context, and analysts become a reporting queue instead of a force multiplier.
Learning how to write SQL queries changes that dynamic. It gives you a direct way to inspect the data, test assumptions, and answer business questions without waiting on a handoff. If you're working toward self-serve analytics, SQL is the skill that enables it.
Table of Contents
Why Learning SQL Is Your Analytics Superpower
The fastest analysts aren't always the ones who know the most syntax. They're the ones who can turn a vague business question into a clean query and get to a trustworthy answer without a long dependency chain.
That's why SQL matters so much. It became the standard language for relational databases by the 1970s and remains the core way to retrieve, update, and join data. A 2020 survey reported that SQL was used by 80% of data professionals according to IBM's overview of SQL. That staying power matters because it means the time you spend learning SQL transfers across systems and roles.
For someone in product, growth, operations, or finance, this isn't about becoming a database engineer. It's about being able to answer questions like:
Product usage: Which users adopted the feature after launch?
Revenue: Which customers expanded after the pricing change?
Operations: Which accounts haven't placed an order recently?
Marketing: Which acquisition channels bring users who convert?
SQL gives you a path from "I need a report" to "I can test this right now."
That shift is especially valuable if you're building a career in analytics-heavy roles. If you're browsing Web3 data jobs, you'll notice a recurring pattern: teams want people who can reason with data directly, not just consume dashboards.
If databases still feel abstract, read this plain-English explanation of databases, Excel, and SQL. It helps clarify why SQL sits at the center of modern reporting while spreadsheets usually sit at the edge.
The real advantage isn't syntax
Organizations don't need more dashboards. They need more people who can inspect the source data, spot broken assumptions, and turn a business question into reusable logic.
That's the strategic value of learning how to write SQL queries. You stop being a passive consumer of metrics and become someone who can interrogate the system. In companies trying to build self-serve analytics, that skill compounds quickly because one good query often becomes the starting point for many future answers.
The Building Blocks of Every SQL Query
A good SQL query starts small. Not elegant. Not clever. Small.
The three commands you need first are SELECT, FROM, and WHERE. They answer three basic questions. What columns do you want, which table are they in, and which rows should be included?
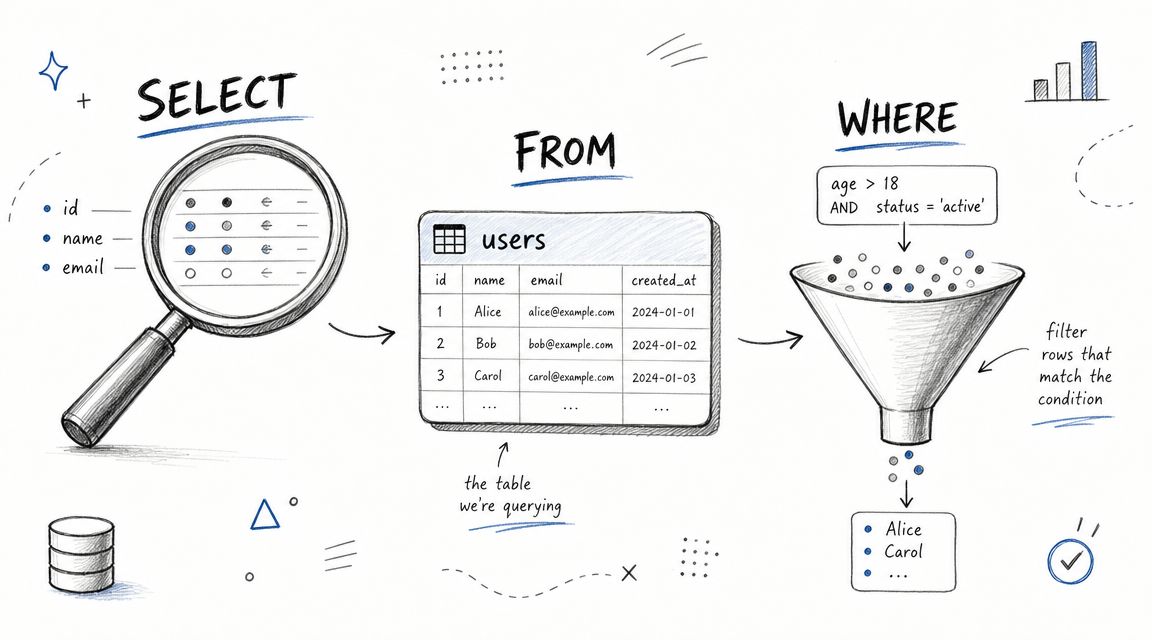
Start with inspection, not ambition
When you're learning how to write SQL queries, don't begin with a complicated KPI. Begin by looking at the raw table.
A practical workflow recommended in Metabase's SQL best practices guide is to validate correctness before optimizing. Start by inspecting source tables with SELECT * ... LIMIT, narrow to the minimum columns needed, add filters, and only then tune performance.
That looks like this:
This isn't how you'd write a production query. It's how you avoid making silly mistakes early. You confirm column names, check data types, and spot oddities like nulls, duplicates, or timestamps stored in unexpected formats.
Practical rule: If you haven't looked at sample rows first, you probably don't understand the table as well as you think you do.
Build the query in layers
Once you've inspected the table, shrink the query to only what matters.
Now you're no longer pulling every column. That's a habit worth building immediately because SELECT * makes debugging harder and often pulls data you don't need.
Next, add a filter:
This is the pattern you'll use constantly:
Inspect the table with a limited sample.
Select the needed columns only.
Filter the rows that match the business question.
Check the output before adding more logic.
A beginner mistake is trying to write the final query in one pass. That usually leads to confusion because you don't know which step introduced the error.
A simple mental model
Here's a short table I use when mentoring new analysts:
SQL clause | What it does | Business translation |
|---|---|---|
| Chooses columns | "Show me these fields" |
| Names the source table | "Pull from this dataset" |
| Filters rows | "Only include records matching this condition" |
| Restricts returned rows | "Let me inspect a small sample first" |
If you can write these confidently, you already have the base needed for useful work. Most ad hoc analysis starts here.
What doesn't work is memorizing syntax without tying it to a real question. Query writing gets easier when each clause has a purpose. You're not just typing SQL. You're translating business intent into database logic.
Connecting Your Data with JOINs
Single-table queries are useful, but they won't get you far in a real company. Most business questions live across multiple tables. Users sign up in one table, orders appear in another, subscriptions in a third, and support activity somewhere else.
That's where JOINs matter. If you can join tables correctly, you can answer questions that dashboards often hide behind prebuilt metrics.
Choose the join based on the business question
Use a users table and an orders table as the basic example.
If you want users who have placed at least one order, use an INNER JOIN:
This returns only rows where the key exists in both tables.
If you want all users, including those who never ordered, use a LEFT JOIN:
This keeps every row from users. If a user has no order, the order fields come back as NULL.
Later in the analysis, you can isolate users with no orders like this:
That pattern is one of the most useful in analytics. It answers questions like inactive accounts, unconverted signups, or customers with no follow-through after onboarding.
A FULL OUTER JOIN is broader:
It returns matched rows plus unmatched rows from both sides. It's helpful for reconciliation work, especially when you're checking whether two systems line up.
For a deeper comparison of join types, this guide on inner join and outer join SQL patterns is a useful follow-up.
A quick join decision table
Join type | Keeps which rows | Best for |
|---|---|---|
| Only matched rows from both tables | Converted users, paid accounts, fulfilled orders |
| All rows from left table, matched rows from right | Coverage checks, drop-off analysis, finding missing activity |
| All rows from both tables | Reconciliation, mismatch checks, system comparisons |
A join isn't just syntax. It's a statement about what should count in the analysis.
Here's a visual explanation before we go further:
Common join mistakes that create bad reporting
The most common problem isn't using the wrong join keyword. It's joining at the wrong grain.
Suppose users has one row per user and orders has many rows per user. If you join them and then count users without thinking, you'll often overcount because one user can appear many times.
Watch for these issues:
Duplicate inflation: A user with multiple orders appears multiple times after the join.
Weak join keys: Joining on email instead of a stable ID often creates messy matches.
Filters in the wrong place: A condition on the joined table can accidentally turn a
LEFT JOINinto something closer to anINNER JOIN.
If your result set suddenly gets much larger after a join, stop and ask whether the row grain changed.
Good analysts learn to ask one question before every join: what does one row represent before and after this query? That habit prevents a lot of bad metrics.
Summarizing Data with Aggregations
Most stakeholders don't want raw rows. They want a summary that helps them decide what to do next.
That means moving from transaction-level data to grouped metrics using aggregate functions like COUNT, SUM, AVG, MIN, and MAX. At this point, SQL starts feeling less like data retrieval and more like analysis.
Move from rows to metrics
Start with a basic count. If you want the number of users by acquisition channel:
GROUP BY changes the shape of the output. Instead of one row per user, you now get one row per channel.
You can also summarize revenue by month:
This is how teams build the first draft of a KPI table. Not with a dashboard builder first. With a query that makes the metric explicit.
Where and having do different jobs
This distinction trips up a lot of people.
Use WHERE to filter rows before aggregation:
Use HAVING to filter grouped results after aggregation:
The first query says, "only include US users, then count them by channel."
The second says, "count all users by channel, then keep only channels with more than 10 users."
A useful shortcut is this.
WHEREfilters records.HAVINGfilters summaries.
A business-focused aggregation pattern
When you're building reporting for a team, I recommend this sequence:
Start with the metric definition: What exactly are you counting or summing?
Choose the grouping level: By day, month, channel, account, or product?
Apply row filters first: Limit the data to the relevant population.
Use aliases clearly: Name outputs so other people can read them.
Inspect odd groups: If one category looks too large or too small, drill back into the raw rows.
Here's a cleaner example:
If you're heading toward more advanced analysis from here, especially rolling totals or ranking within groups, this introduction to SQL window functions is the next concept to pick up.
Aggregation is where self-serve analytics starts becoming practical. Once you can summarize at the right grain, you can answer many common business questions without waiting for a custom dashboard.
Writing Cleaner and More Powerful Queries
At some point, basic SELECT, JOIN, and GROUP BY queries start getting messy. You add one more condition, then another subquery, then a special case for active users, and suddenly the logic is hard to read and harder to trust.
The fix usually isn't more clever SQL. It's better structure.
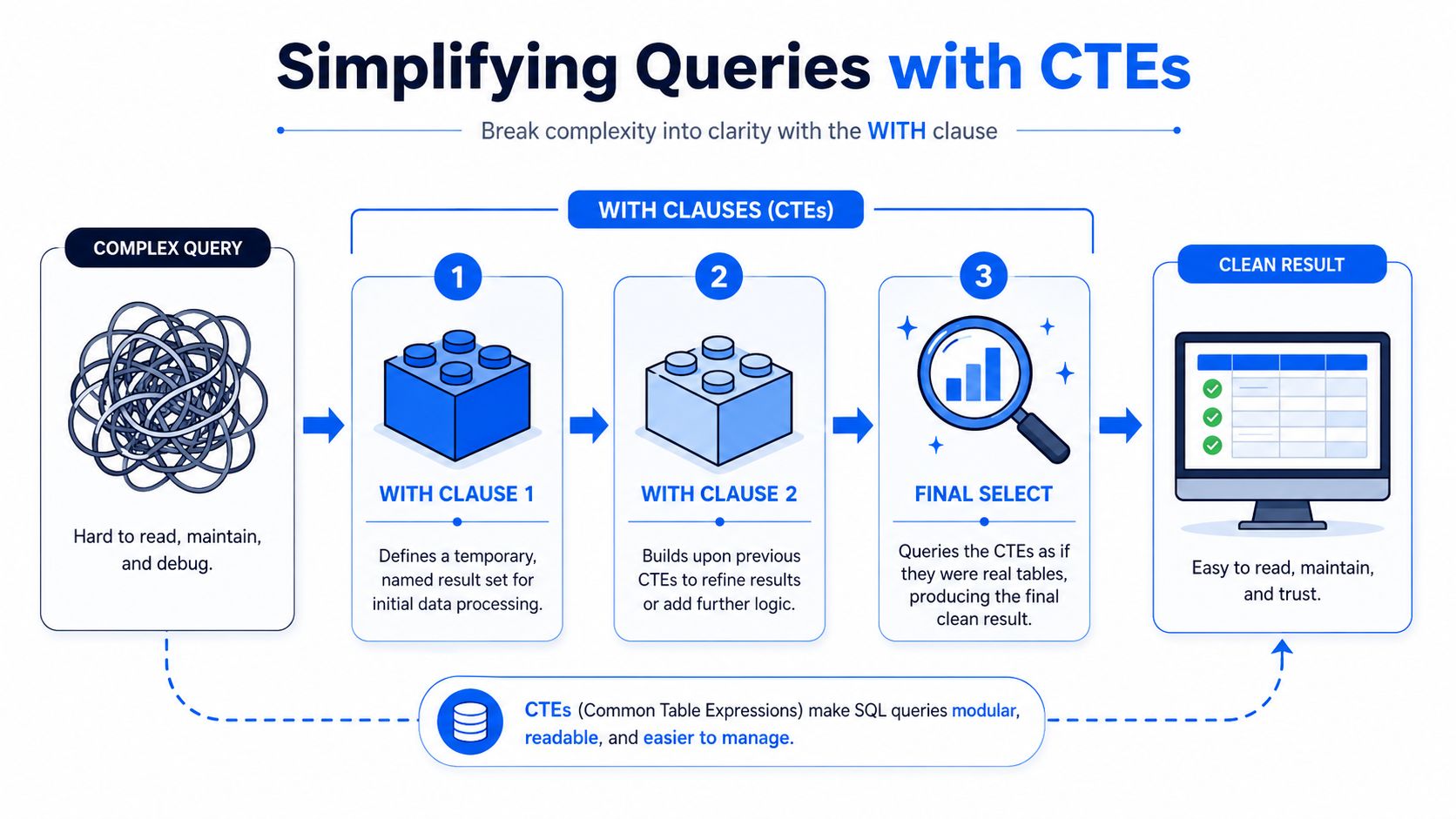
Use CTEs to name your thinking
A Common Table Expression, usually written with WITH, lets you break a query into named steps.
Instead of nesting everything inside parentheses, write each intermediate dataset clearly:
This is easier to debug because each step has a job. You can run one CTE at a time while building. It's also easier for another analyst to review.
Nested subqueries can still work, but they often hide intent. CTEs make the logic readable in the order you think about it.
Window functions keep row-level detail
Aggregations collapse rows. Window functions don't.
That's what makes them powerful. You can calculate rankings, running comparisons, or previous values while keeping each original row visible.
For example, if you want the top-selling products within each category:
If you want one row number per category, often for deduping or selecting the latest record:
And if you want to compare a value to the previous row, LAG() is a strong pattern:
That kind of query is much cleaner than self-joining a table to itself just to get the prior row.
What cleaner SQL looks like in practice
Here are the habits that usually separate maintainable SQL from fragile SQL:
Name intermediate steps clearly.
active_usersis better thant1.Keep each CTE focused. One transformation per step is easier to validate.
Avoid stacking business logic in one giant clause. Spread it across readable steps.
Prefer explicit column names. They make review and downstream reuse easier.
Leave enough context for the next person. In many teams, that next person is you in two weeks.
You can also use tools that expose the generated SQL instead of hiding it. For example, Querio shows AI-generated queries in explicit SQL form so users can inspect and edit the code rather than treating the result like a black box.
Clean SQL isn't about style points. It's about making sure someone else can verify the business logic without reverse-engineering your thought process.
If your query is doing real business work, readability is part of correctness.
Writing Queries That Run Fast and Respect Resources
A query can be logically correct and still be a bad query. If it scans far more data than needed, stalls shared compute, or becomes impossible to use in a dashboard refresh, it isn't finished.
Performance isn't a separate topic for database administrators. It's part of writing SQL well.
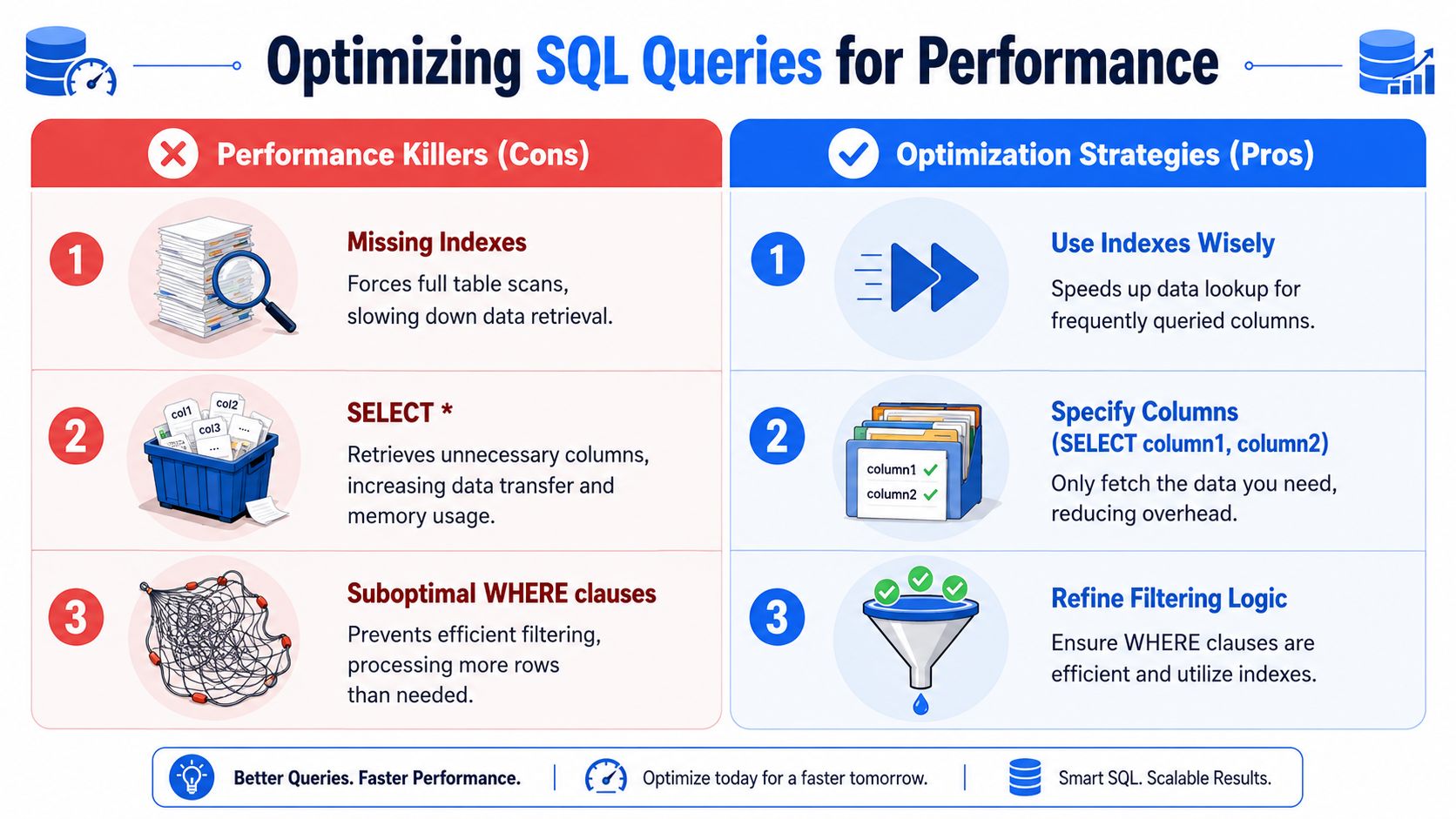
What slows queries down
One common performance problem is making a query non-sargable. Microsoft notes that functions in a WHERE clause can prevent index use and slow execution, while indexing foreign-key and frequently queried columns can significantly decrease query times in its documentation on SQL Server statistics and optimization.
In practice, that means this pattern can be costly:
It often works better to filter in a way that preserves index use, depending on your database and schema design.
Another common issue is pulling more data than you need. SELECT * feels convenient, but in production it often wastes memory, bandwidth, and attention. If a dashboard only needs five columns, select five columns.
For a more detailed walkthrough, this guide to optimizing a query is a useful complement.
A practical performance checklist
I usually teach new analysts to check these first:
Filter early: Reduce rows as soon as you can, especially before large joins.
Select narrowly: Fetch only the columns needed for the question.
Watch your
WHEREclause: Avoid patterns that block index use.Index the right columns: Foreign keys and heavily queried fields deserve attention.
Check the plan: Use
EXPLAINor your warehouse's equivalent to see what the engine is doing.
Here's a simple do-this-not-that comparison:
Avoid | Prefer |
|---|---|
| Select only required columns |
Filtering late after huge joins | Filtering as early as possible |
Wrapping indexed fields in functions inside | Writing predicates that preserve index use |
Ignoring execution plans | Reviewing query plans for expensive scans |
Fast SQL is considerate SQL. You're sharing compute with other analysts, dashboards, scheduled jobs, and applications.
You don't need to become a performance specialist to get strong results. Most query slowdowns come from a short list of avoidable habits. Fix those first, then profile the queries that matter most.
From Query Writer to Self-Serve Analytics Champion
Writing a good query is useful. Making that query reusable is what changes a team.
The difference is documentation, naming, and packaging. If you save a messy one-off query on your laptop, you've answered one question. If you turn it into a clean snippet with clear filters, defined grain, and readable output names, you've created something other people can build on.
That's how self-serve analytics grows inside a company:
Save reusable query patterns for common questions like active users, revenue by period, or accounts with no recent activity.
Document assumptions so nobody has to guess what a metric includes.
Use parameters where possible so non-technical teammates can rerun the same logic with different dates or segments.
Treat SQL as shared infrastructure rather than personal scratch work.
The long-term win is that analysts stop functioning as a human API. They spend less time answering the same request repeatedly and more time improving the system people use to answer their own questions.
If you're learning how to write SQL queries, that's the bigger payoff. You're not only getting better at syntax. You're helping your team move faster, ask sharper questions, and trust the path from raw data to decision.
If your team wants that self-serve model without hiding the underlying logic, Querio is one option to evaluate. It lets users work from natural-language prompts while keeping the generated SQL visible and editable, which is useful when you want speed for non-technical users without giving up code review, reuse, or warehouse-native analysis.

