Software Data Modeling: A Modern Practical Guide for 2026
Master software data modeling from core concepts to modern warehouse governance. Learn key patterns and see how agent-driven tools simplify the process.
https://www.youtube.com/watch?v=RJ9TpkWKyU0
published
Outrank AI
software data modeling, data modeling guide, dimensional modeling, data governance, data architecture
2d7f090a-84d1-4ecf-a793-9a6c785eab7c

A product manager asks for one new metric. Finance wants the same number split a different way. Growth needs it in a dashboard before the next planning meeting. None of those requests sound hard, yet they disappear into a queue because the answer is always the same: the model needs to be updated first.
That's the core problem with software data modeling in most companies. The model isn't failing because the team forgot how to design tables. It becomes a bottleneck because the workflow around it is slow, centralized, and tied to tools that make every change feel heavier than it should.
Founders usually see the symptoms before they see the cause. Teams stop trusting metrics. Analysts spend more time maintaining joins than answering questions. Engineers avoid touching schemas because one small change can break reporting downstream. The business calls it a data problem. In practice, it's often a modeling process problem.
Table of Contents
Why Your Data Model Is a Bottleneck (And How to Fix It)
The usual story goes like this. A PM asks for “weekly activated users by workspace type.” The analyst can't ship it immediately because the event table and account table don't line up cleanly. The data engineer says the join logic is fragile. The BI owner says they don't want another quick fix inside the semantic layer. Two weeks later, the meeting happens without the metric.
Nothing about that delay is caused by a lack of intelligence. It's caused by a rigid operating model. Software data modeling sits in the middle of every reporting flow, every metric definition, and every query path. When the modeling workflow is slow, the whole business moves slowly.
That's why data teams end up acting like a ticket queue instead of an enabling function. They're not only defining business entities and relationships. They're also mediating every request that touches them. Even a basic change can require schema review, tool updates, testing, deployment, and dashboard refactoring.
Practical rule: If a simple business question requires a modeling specialist, a BI developer, and a deployment cycle, the bottleneck isn't the question. It's the process.
A lot of founders try to solve this by pushing teams to “just be more self-serve.” That rarely works if the underlying model is still trapped inside brittle tooling. Better query performance helps, and so does cleaner SQL, but neither fixes a workflow that's structurally slow. That's why it's worth understanding how query optimization affects analytics responsiveness, while also recognizing that performance tuning alone won't remove modeling friction.
The better path is to keep the discipline of modeling and change the way teams create, validate, and maintain models.
The Three Levels of Software Data Modeling
Software data modeling makes more sense when you treat it like building a house. You don't start by choosing screw sizes or debating paint colors. You start with what needs to exist, how the parts connect, and only then decide how it gets built in a specific environment.
A lot of confusion comes from collapsing those steps into one conversation.
Here's the visual version:
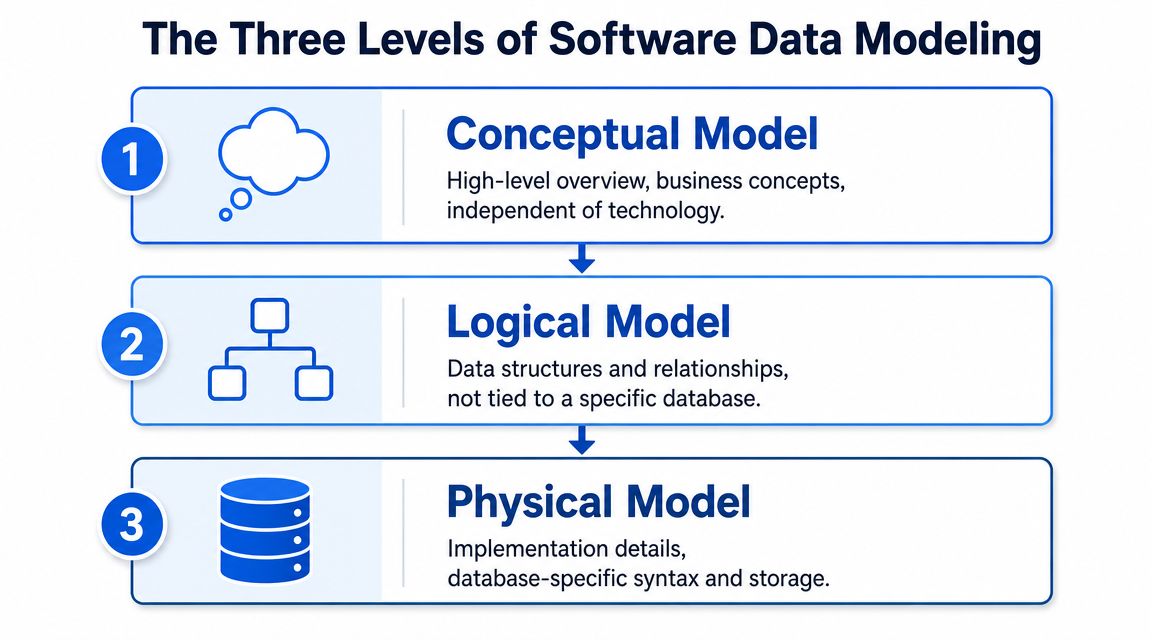
The structure isn't new. The historical foundation described in SQLDBM's timeline traces modern software data modeling back to 1970, when Edgar F. Codd's relational model introduced normalized relations, tuples, and keys. By the 1990s, SQL and OLAP had made that theory mainstream for analytical systems. The abstractions are old. The workflows around them are what need modernization.
Conceptual model
The conceptual model is the business sketch. It names the important things without worrying about the database yet.
If you're running a SaaS company, that might include customers, workspaces, subscriptions, invoices, product events, and users. At this level, the key question is simple: what does the business need to describe clearly?
This model is useful because it forces alignment before anyone starts building tables. Founders often skip this step because it feels abstract. Then they pay for it later when “customer” means account in one system, billing entity in another, and workspace owner in a dashboard.
A conceptual model should answer questions like:
What are the core entities: users, teams, orders, subscriptions, sessions.
How do they relate: one workspace has many users, one invoice belongs to one billing account.
What rules matter: an order can't exist without a customer, a trial must map to a plan state.
A short explainer helps here for teams that also need clarity on OLTP versus OLAP system design, because the intended workload affects what comes next.
After the business shape is clear, you can get more precise.
Logical model
The logical model is the detailed floor plan. You still aren't choosing warehouse-specific implementation details, but now you define structure.
Entities become attributes, keys, and relationships. A user table gets fields. An order table gets status logic. Primary keys and foreign keys become explicit. Cardinality matters.
The logical model is where data teams usually discover whether the business really agreed on definitions. If marketing says “active user” means a visit, product says it means a core action, and customer success says it means paid seat usage, the model won't save you. It will expose the disagreement.
A strong logical model does a few things well:
Names things cleanly so teams don't create five versions of the same metric.
Makes joins predictable so downstream analysis isn't guesswork.
Preserves business rules that would otherwise live in analysts' heads.
Physical model
The physical model is the construction plan for the actual system you run, where the design meets a specific DBMS and becomes operational.
According to Agile Data Engine's explanation of physical modeling, physical data modeling translates a logical model into implementation details like tables, columns, data types, constraints, and indexes. This is the stage where design decisions affect query latency and storage efficiency.
The physical layer is where elegant theory turns into expensive scans or fast answers.
This is also where many startup teams accidentally create long-term pain. They design a perfectly reasonable logical model, then implement it in ways that don't match real workloads. The result is a model that's technically correct but painful to use.
Choosing Your Philosophy Normalized vs Dimensional Models
Most debates about modeling go wrong because they ask which approach is better. That's the wrong question. The useful question is which failure you're trying to avoid.
If you want transaction integrity, you usually lean toward normalized design. If you want fast, intuitive analytics, you usually lean toward dimensional design. In practice, teams move between the two and often borrow from both.
What normalized models optimize for
A normalized model tries to reduce redundancy and preserve integrity. You split data into related entities so the same fact doesn't live in ten places.
That's why normalized models are a natural fit for operational systems. Product databases, billing platforms, and back-office applications usually need this discipline. You don't want duplicate customer addresses drifting apart or order states being stored inconsistently across multiple tables.
The trade-off is query complexity. The cleaner the normalization, the more joins analysts often need to reconstruct the business question.
What dimensional models optimize for
A dimensional model is built for analysis. It usually organizes data around facts and dimensions, often in a star schema, so BI tools and analysts can answer common questions quickly.
This approach works well when users need stable business metrics, not a full reconstruction of application logic. Revenue by month. Retention by cohort. Product usage by segment. Those are warehouse questions, and dimensional models make them easier to answer repeatedly.
Teams rarely stay pure. As Splunk's overview of iterative data modeling notes, effective modeling is iterative, and teams balance normalization to reduce redundancy with denormalization when performance or analytics SLAs require fewer joins and faster scans.
Criterion | Normalized Model (ER) | Dimensional Model (Star Schema) |
|---|---|---|
Purpose | Preserve integrity in operational data | Speed up analytics and reporting |
Structure | Many related entities with less redundancy | Facts and dimensions shaped for business questions |
Query pattern | More joins, more reconstruction | Fewer joins for common reporting paths |
Change management | Cleaner for transaction logic | Cleaner for repeated analytical use |
Main risk | Hard for non-specialists to query | Can drift from source truth if not governed carefully |
A founder-friendly way to understand this:
Choose normalized first when the system of record matters most.
Choose dimensional first when teams need consistent reporting paths.
Blend carefully when product analytics, finance reporting, and operational apps all pull from the same warehouse.
What doesn't work is dogma. Teams that normalize everything often produce elegant models no one can use quickly. Teams that denormalize everything usually move fast for a while, then spend months untangling inconsistent definitions.
Modern Data Modeling Challenges and Governance
The hard part of software data modeling today isn't drawing entities on a diagram. It's keeping those definitions stable while the business changes underneath them.
A startup adds a pricing tier. Product instrumentation changes. Sales introduces a new account hierarchy. An AI workflow starts emitting semi-structured payloads. Every one of those changes pressures the model. Traditional workflows break because they assume change is occasional and centrally managed.
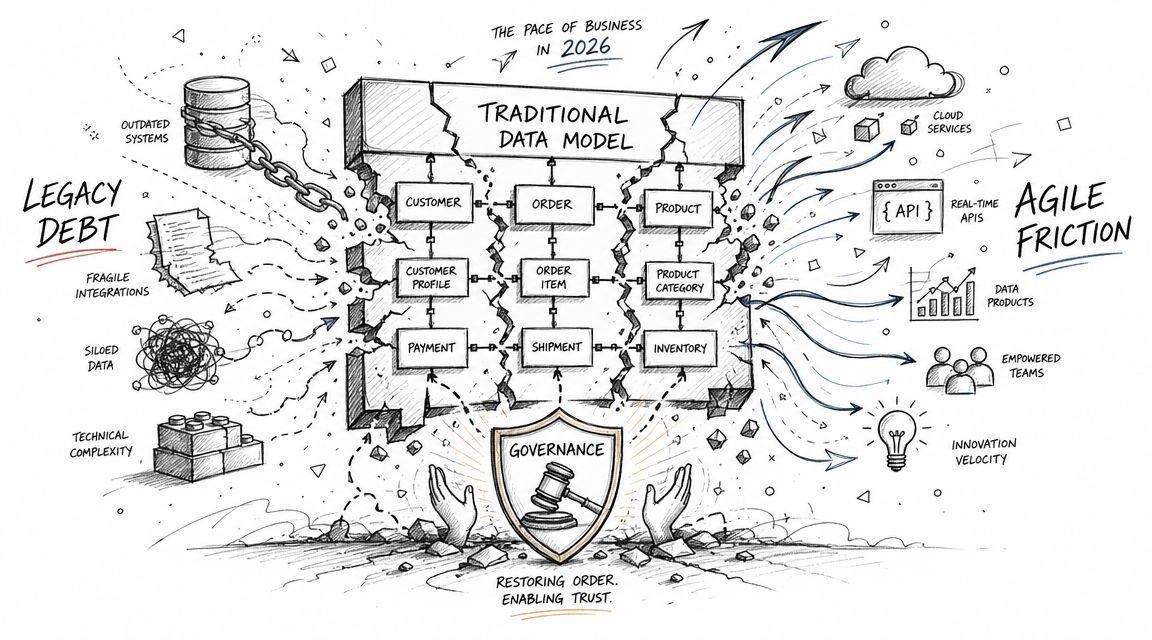
Where traditional workflows break
The first failure mode is schema drift. A source system changes field names or payload structure. The warehouse still loads, but downstream logic starts returning partial truth. Dashboards don't always fail loudly. They just get weird.
The second is the governance trap. Data leaders want controlled definitions, documentation, and trust. Business teams want speed. If governance lives only in approval gates, users route around it. If self-service has no guardrails, trust disappears.
A third pressure point is workload variety. Modern teams don't only model warehouse tables for BI. They also deal with event streams, JSON payloads, document-style structures, graph-like relationships, and data products used by AI systems. Old playbooks focused too narrowly on relational design.
Brittle schemas break: a rename upstream can invalidate a metric without anyone noticing immediately.
Centralized ownership slows everything down: every change waits for the same small team.
Rigid warehouse shapes don't fit every use case: forcing every dataset into one pattern usually creates awkward compromises.
A bad model is fixable. A brittle modeling process keeps producing bad outcomes even after you fix the model.
Governance has to live in the model
Data contracts matter. Gable's guidance on data contracts and modeling makes the key point that modern modeling must define stable interfaces between producers and consumers, because schemas function as technical contracts. That framing matters. Governance isn't something you bolt on after modeling. It's part of modeling.
For startup teams, this changes the operating question from “How do we diagram the warehouse?” to “How do we prevent one team's change from breaking another team's decisions?” If you're actively formalizing that process, this practical guide to data governance implementation is useful because it ties ownership and control back to operational workflows.
A workable governance stance usually includes:
Clear ownership for critical subject areas such as revenue, product usage, and customer identity.
Versioned definitions so changes are visible before they become breakage.
Interfaces that stay stable even when internals evolve.
Models validated against real business questions, not just technical neatness.
Implementation Best Practices for Performance
A startup usually notices modeling performance problems in the same moment trust starts to slip. Finance exports data because the dashboard is slow. Product analysts copy logic into ad hoc tables because joins take too long. Engineering gets pulled into query tuning after the warehouse bill jumps.
By then, the issue is rarely a single bad query. It is a modeling workflow that treated physical design as cleanup work instead of part of the implementation plan.
What good physical modeling looks like
Physical modeling decides how the warehouse behaves: table shapes, data types, sort and partition choices, clustering, indexes where the platform supports them, and how much denormalization the team is willing to carry. These decisions affect latency, cost, and how often analysts need workarounds.
Teams get into trouble when they stop at the logical model. A clean diagram can still produce slow joins, wasteful scans, and brittle transformations if the warehouse layout does not match the way people query data.
A sound implementation practice usually includes:
Data types picked on purpose: identifiers, timestamps, currencies, and status fields should be unambiguous from the start.
Storage patterns matched to query behavior: partition, cluster, distribute, or index based on repeated access patterns, not generic defaults.
Denormalization used selectively: duplicate data only where the speed gain is clear and the ownership of that logic is still manageable.
Performance checks built into modeling work: test model changes against real dashboards, recurring reports, and known heavy queries before they become production pain.
Good teams also accept a simple trade-off. The fastest model for one workload is often the wrong model for another.
What usually goes wrong
The common failure mode is local optimization. A team speeds up one dashboard by flattening everything into a wide table, then spends months reconciling inconsistent business logic across downstream models. Another team keeps every subject area strictly normalized, then forces analysts to rebuild the same joins and filters in every query.
The better approach is to optimize the paths that carry repeat demand and keep the rest flexible. Month-end finance reporting deserves stable, tuned access patterns. Exploratory product analysis usually needs looser structures and faster iteration.
Operating advice: Optimize repeated questions. Keep exploratory paths cheap to change.
The workflow matters as much as the schema. Performance tuning often depends on a small group that understands warehouse internals, BI query patterns, and business definitions well enough to change the model safely. That creates a queue. The queue becomes the bottleneck. Then performance work arrives late, under pressure, and with too little context.
That is why mature teams treat modeling and implementation as one operating loop, not separate phases. They review query behavior, refine physical design, and update shared definitions continuously. If your process still relies on handoffs between modeling, SQL generation, review, and deployment, it is worth revisiting your data modeling best practices for production scale.
The Querio Way Agent-Driven Modeling for Speed
The biggest misconception in software data modeling is that the bottleneck comes from the model itself. Usually, it comes from the handoffs.
A business user asks a question. An analyst interprets it. A data engineer checks the schema. Someone edits a semantic layer or BI definition file. Then the team waits for review and deployment. Even if each step is reasonable, the chain is slow. The workflow assumes modeling changes should move through a narrow funnel.
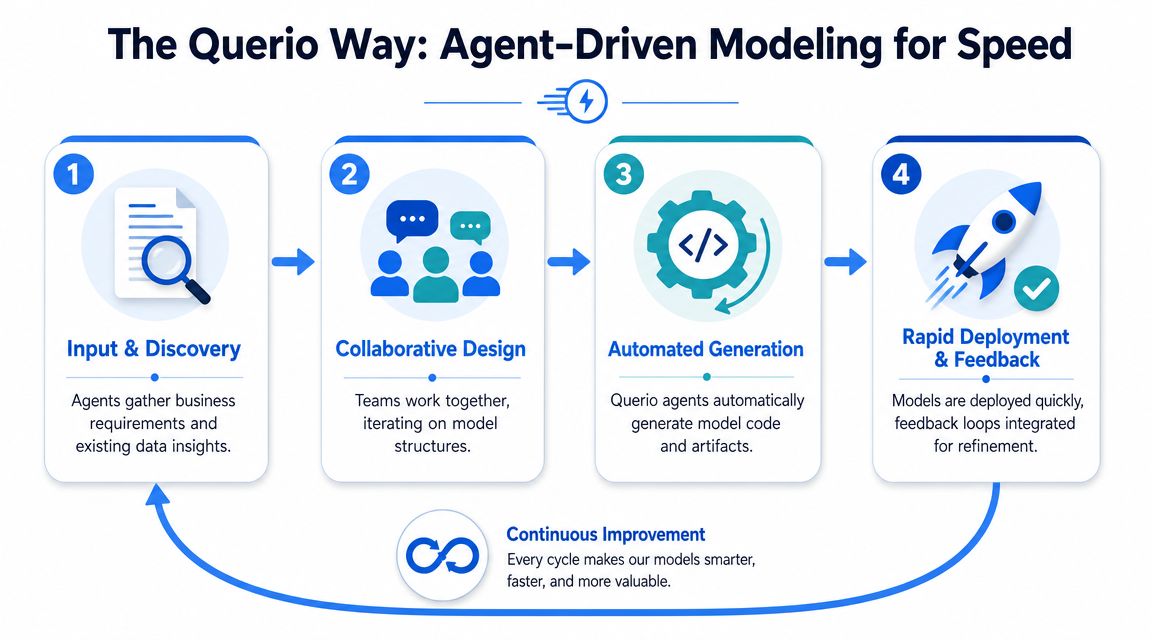
The old workflow is the real constraint
Traditional BI tooling encourages centralized control because it ties business logic to rigid modeling layers. That can work in a stable environment. It struggles when product definitions change weekly and teams need to explore before they formalize.
The result is a familiar anti-pattern:
Discovery happens outside the model: people test logic in ad hoc SQL or spreadsheets.
Formalization happens later: the “real” definition gets added only after repeated requests.
Maintenance keeps piling up: the semantic layer becomes crowded with half-obsolete logic and exception handling.
That's why many data teams feel trapped between two bad options. They can either protect the model and slow the business down, or loosen control and let metric trust erode.
A faster modeling loop
An agent-driven approach changes the workflow by shrinking the gap between exploration, validation, and operationalization. Instead of forcing every request through a tool-bound deployment cycle, teams can work in a notebook-style environment where logic is inspectable, collaborative, and closer to the warehouse.
That matters because modeling is iterative by nature. A useful workflow should support a loop like this:
Start from the business question. Define the metric or entity in plain language first.
Inspect existing structures. Check what already exists in the warehouse, semantic layer, or source tables.
Generate or draft the logic. Let agents propose joins, dimensions, and metric logic based on current data shape.
Validate with humans. An analyst, engineer, or domain owner confirms whether the logic matches the business rule.
Materialize only what deserves to persist. Not every experiment should become permanent infrastructure.
Products employing warehouse-native notebooks and agent assistance can be particularly helpful. Querio provides one such instance. It deploys AI coding agents on the warehouse and uses a file-system approach with Python notebooks, so teams can inspect logic, iterate on models, and create reusable artifacts without routing every change through a traditional BI modeling bottleneck.
That doesn't mean governance disappears. It means governance shifts upward. The data team stops spending all day answering one-off requests and spends more time defining interfaces, ownership, review patterns, and reusable building blocks.
The mature data team isn't a human API. It's the team that creates safe, fast paths for everyone else.
A founder should care about this because the value isn't only technical. Faster modeling loops change how quickly teams can test pricing logic, understand product adoption, and answer board-level questions without waiting on a queue.
Build a Data Model That Empowers Not Restricts
The core principles of software data modeling haven't changed. Clarity still matters. Integrity still matters. Performance still matters. What has changed is the cost of keeping those principles inside a workflow built for slower companies and fewer requests.
Founders don't need less modeling discipline. They need a modeling workflow that matches how modern teams operate. Business definitions evolve. Data sources shift. Users expect self-service, but they also expect trust. That combination breaks rigid, centralized systems.
The practical standard is simple. Keep conceptual clarity. Keep logical rigor. Keep physical performance work close to the warehouse. But stop treating every model change like a small software release that only a specialist can touch.
That's also why strong product leaders increasingly care about the mechanics of decision quality, not just the dashboards. If you want a useful companion read on how PMs can structure better operating decisions around data, Aakash Gupta's PM strategies are worth your time.
A good data model should make the company faster. If it makes every reasonable question slower, the design may be sound but the workflow is wrong.
If your team is stuck maintaining dashboards, patching schema issues, and acting as a reporting help desk, it's worth looking at Querio as a different operating model. The point isn't to abandon modeling. It's to keep the rigor and remove the queue so analysts, engineers, PMs, and founders can work from the same warehouse with less waiting and more confidence.

