Data Management Services: Your 2026 Guide to Growth
Unlock growth with our 2026 guide to data management services. Explore service types, vendor selection, ROI, and build a self-service data culture.
https://www.youtube.com/watch?v=uSHIiBNoE0E
published
Outrank AI
data management services, data governance, master data management, self-service analytics, querio
c2b1880a-c30f-4afe-b6c8-8d1d98b6f823

By the time a company feels it has a data problem, the issue usually isn’t storage. It’s throughput.
The product team wants a retention cut by onboarding path. Finance wants a cleaner revenue view. Sales wants account health in the CRM to match what success sees in the support tool. The CEO asks a simple question in Monday’s meeting, and the honest answer is, “We can get that by Thursday if analytics has time.”
That’s the moment data stops being a back-office function and starts acting like a growth constraint.
I’ve seen the same pattern across startups and mid-market teams. A handful of analysts become the company’s unofficial operating system. They patch spreadsheets, reconcile definitions, rerun SQL, and answer the same question five different ways because each team uses a different source of truth. Nobody planned for this. It just happens when headcount, tools, and customer complexity outgrow the habits that worked at ten people.
Data management services matter because they turn that reactive mode into an operating model. Done well, they don’t just clean data. They create the conditions for trustworthy, repeatable, self-service analytics.
Your Scaling Company Has a Data Problem
A familiar version of this story starts with a healthy sign. The company is growing. There are more customers, more systems, more dashboards, more stakeholders asking sharper questions. Then the data team starts drowning.
Marketing pulls numbers from one platform. Product defines activation differently. Finance closes the month with a spreadsheet nobody wants to touch. Support logs useful customer signals, but those signals never make it into analysis because the data sits in tickets, chat transcripts, and exports. Leaders feel the drag before they can name it.
The expensive part isn’t bad reporting. It’s delayed decisions.
What bottlenecked teams look like
When a scaling company lacks a real data foundation, the symptoms are usually operational, not technical:
Requests pile up: analysts spend their time answering one-off questions instead of building durable models and pipelines.
Definitions drift: “customer,” “active user,” and “qualified lead” mean different things in different meetings.
Trust erodes: teams rerun reports because they don’t believe the first answer.
Recovery gets harder: when something breaks, cleanup becomes manual and slow. In the worst cases, teams need specialized help such as data recovery services just to restore business continuity after loss or corruption.
A lot of founders still treat this as normal startup messiness. Some of it is. But past a certain point, ad hoc fixes turn into compounding operational debt.
Raw access to data doesn’t create speed. Shared definitions, governed access, and reliable pipelines do.
The market direction reflects that shift. The industrial data management market is projected to grow from USD 105.10 billion in 2025 to USD 213.20 billion by 2030, with a CAGR of 15.2%, according to MarketsandMarkets’ industrial data management market outlook. That projection matters because it signals something leaders already feel firsthand: formal data strategy is moving from optional infrastructure to core operating discipline.
The problem is usually silos
Most scaling teams don’t fail because they lack data. They fail because useful data is fragmented across apps, warehouses, docs, and people. If that’s already happening inside your company, a practical starting point is understanding how data silos form and how to break them down.
The founders who solve this early don’t ask for more dashboards first. They ask a harder question: how do we make trustworthy answers available without routing every request through the same two overloaded people?
That’s where data management services start to matter.
Thinking Like a City Planner for Your Data
A scaling company usually hits this moment fast. Sales asks for pipeline by product line. Finance wants revenue by customer segment. Product wants activation broken down by account tier and support history. Everyone assumes the answer should be easy because the data exists somewhere.
Data management services are best understood through the lens of city planning. The goal is not just to store more data or move it faster. The goal is to make the company operable, so teams can answer routine questions on their own without creating new inconsistencies every week.
A city functions because infrastructure, access rules, and shared standards are designed together. Data environments work the same way. Warehouses, SaaS tools, notebooks, dashboards, and documents all matter, but they only become useful as a system when data can move reliably between them, core definitions stay consistent, and access is controlled without blocking work.
Without that planning, every new tool adds another intersection, another naming conflict, and another version of the same metric.
What planning actually means
A practical data management program answers five operating questions:
Where does data come from
How is it cleaned and standardized
Where does it live for analysis
Who can use it and under what rules
How do people know it’s current and correct
These are not abstract architecture questions. They determine whether self-service analytics becomes a force multiplier or just spreads bad numbers faster across the company.
The trade-off is straightforward. Tight control slows teams down if every request needs approval from data or engineering. Loose control creates reporting drift, duplicate logic, and avoidable mistakes in pricing, forecasting, and customer analysis. Good planning sets enough structure to make self-service safe.
That matters even more because a large share of business context sits outside clean relational tables. About 80-90% of enterprise data is unstructured, and 55% of AI projects fail due to inadequate unstructured data preparation, according to Gartner data cited by Hyland in its discussion of unstructured data management and AI readiness. Support threads, contracts, call summaries, PDFs, and internal notes often contain the context leaders want in analysis, but they are usually the last assets to be governed properly.
Why startups feel this sooner than they expect
Early-stage teams can get away with workarounds because the same few people still remember how everything fits together. That breaks once headcount grows and decisions need to move faster than tribal knowledge.
The first expensive mistake usually is not a broken dashboard. It is letting every team define the business independently. Marketing invents its own customer definition. Finance uses a different revenue logic. Product tracks accounts one way, while sales tracks them another. At that point, self-service does not reduce load on the data team. It increases it, because every number needs arbitration.
A few principles help keep that from happening:
Model core entities early: customer, account, workspace, subscription, product, and event need clear definitions that survive org changes.
Separate raw from trusted data: ingest flexibly, but publish governed datasets that business users can rely on.
Design for change: tool migrations, pricing updates, and new product lines will happen, so avoid hard-coding assumptions into every model.
Document business meaning, not just schemas: column names are not enough if nobody knows how a metric is calculated or when it should be used.
For teams trying to reduce reporting disputes and make self-service analytics viable, data modeling best practices usually matter more than buying another dashboarding tool.
Practical rule: If a metric definition only lives in one analyst’s head, it isn’t managed data. It’s a dependency risk.
Strong data management does not exist to make the stack look tidy. It exists so more people can answer more questions correctly, with less waiting, less rework, and fewer expensive debates about whose number is right.
The 5 Core Types of Data Management Services
If you’re buying, building, or restructuring a data function, it helps to separate the major service categories. Teams often lump everything together and then wonder why the implementation stalls. Each category solves a different failure mode.
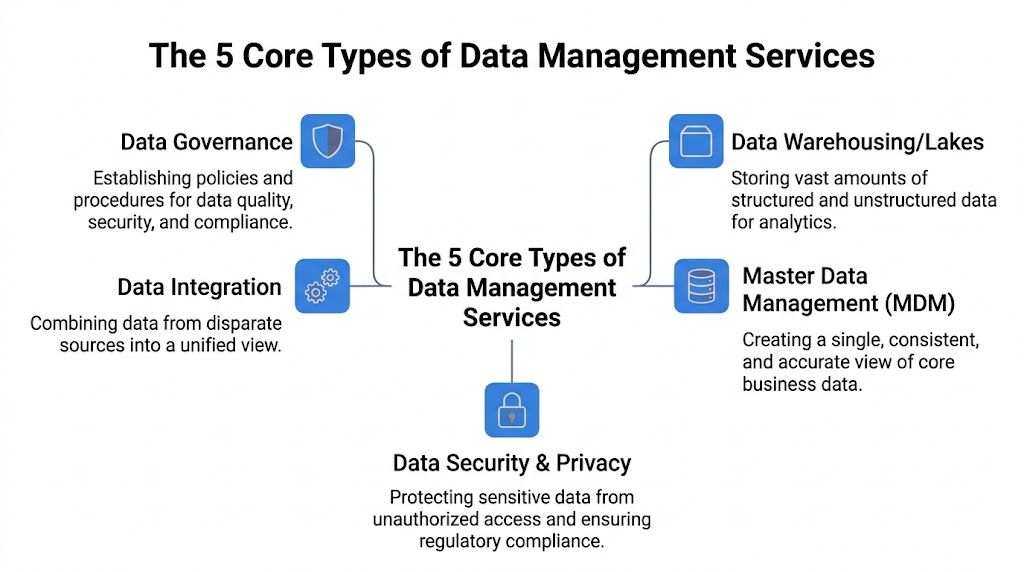
Data integration
This is the plumbing. Data integration moves information from operational tools into systems where teams can analyze and act on it.
For a startup, that usually means pulling from systems like Stripe, HubSpot, Salesforce, Postgres, Segment, Zendesk, or app event streams and making them available in one place. The trap is assuming integration is solved once connectors are live. It isn’t. The hard part is handling late-arriving data, schema drift, duplicated events, and mismatched identifiers across systems.
What works:
Prioritizing high-value sources first: billing, product usage, and CRM usually provide the most value.
Tracking lineage: teams need to know where a number came from and what transformed it.
Making ingestion observable: failures should be visible quickly, not discovered in the board deck.
What doesn’t work:
Blindly syncing every field from every tool
Using spreadsheet exports as a long-term integration layer
Treating reverse ETL or operational sync as the first priority before the core model is stable
Data warehousing and lakes
Data becomes available for broad analysis. Warehouses and lakes give you a shared analytical environment instead of scattered application views.
A warehouse is where a founder asks, “How do trial-to-paid conversion rates differ by acquisition source and implementation path?” and gets one answer sourced from a governed model instead of three conflicting exports. Tools differ, but the operating principle is the same. Centralize access to analytical data and make the trustworthy version easy to use.
A lot of teams overbuild here. They chase a future-proof architecture before they’ve created one stable revenue model or one dependable customer table. Storage design matters, but relevance matters more. If your warehouse is technically elegant and commercially unusable, it’s not helping.
For teams sorting through architecture decisions, the trade-offs in a modern data stack are usually more important than vendor logos.
Data governance
Governance gets dismissed as bureaucracy right up until a company can’t answer who changed a metric, who can access sensitive records, or which dashboard is safe to use.
Good governance isn’t a committee. It’s a set of operating rules:
Who owns each critical dataset
How definitions are approved
Who can access what
What counts as certified for broad consumption
How changes are communicated
This is the difference between open access and responsible access. Self-service without governance creates noise, duplicate logic, and exposure risk. Governance without usability creates shadow analytics. The sweet spot is clear ownership with low-friction consumption.
The strongest governance models don’t block data use. They make safe use the easiest path.
Master data management
MDM becomes important when the same core entity exists in multiple systems and nobody agrees on the canonical record. Customer and product data are the usual pain points, but supplier, account, location, and asset data can become just as messy.
A classic example: sales tracks accounts in the CRM, product tracks workspaces in the application database, finance bills legal entities, and support tags contacts in a helpdesk. Everyone says “customer,” but they don’t mean the same thing.
That’s where MDM earns its keep. Effective MDM systems can reduce data duplication by 20-30% and improve data accuracy to 99.9% by enforcing golden records through automated matching and survivorship rules, according to Gartner benchmarks summarized by Profisee in its overview of core MDM capabilities.
In practice, MDM is less about abstract data purity and more about operational sanity. It gives the business one consistent view of the things that matter most.
Data quality and security
Some organizations split these into separate workstreams. In day-to-day operations, they’re tightly linked. Data quality asks whether the data is complete, valid, timely, and consistent. Security asks whether the right people can use it without exposing the wrong things.
You can’t build self-service analytics on top of broken or unsafe data. A few concrete checks matter more than long policy documents:
Service type | Core question | Real business impact |
|---|---|---|
Data quality | Can people trust the record and the metric | Fewer reruns, fewer manual reconciliations |
Data security | Can people access what they need without overexposure | Lower compliance and operational risk |
Strong teams operationalize this with tests, permissions, review workflows, and named owners. Weak teams rely on tribal knowledge and hope.
The five categories fit together. Integration brings data in. Warehousing makes it usable. Governance defines the rules. MDM reconciles the core entities. Quality and security keep the whole system trustworthy. Miss one layer and self-service analytics usually collapses under the weight of exceptions, rework, or access disputes.
In-House Team vs Managed Services A Strategic Choice
A familiar pattern shows up around Series A or B. The company has a warehouse, a few dashboards, and one or two people everyone depends on for answers. Then growth adds new tools, new teams, and new definitions of the same metric. What looked like a tooling question becomes an operating model question. Who should own the work that turns raw data into something the business can use without waiting in line?
The wrong answer creates a different kind of bottleneck. An underbuilt internal team spends its time firefighting pipelines and permissions. An overextended vendor relationship keeps the systems running but leaves metric definitions, trust, and adoption unresolved. If the goal is self-service analytics, the question is not just who can manage the stack at the lowest cost. The question is which capabilities need to stay close to the business so teams can answer their own questions correctly.
The real trade-off
Control matters. Cost matters. The harder trade-off is deciding where judgment should live.
Keep the work in-house when it depends on product context, commercial nuance, or constant iteration with business teams. That usually includes semantic modeling, metric definitions, data contracts with internal stakeholders, and the training needed to make self-service analytics work. Outsource the work that is operationally heavy and relatively standardized, such as infrastructure administration, backup and recovery, routine monitoring, or some compliance tasks, if your team is thin there.
That split is easy to say and harder to execute. Managed services can reduce pressure on a small team, but they also introduce distance between the people who know the business and the people running part of the platform. In practice, companies get into trouble when they outsource the technical layer and assume the analytical layer will organize itself.
In-House Data Team vs. Managed Data Services
Criterion | In-House Team | Managed Services (DMaaS) |
|---|---|---|
Control | High control over architecture, priorities, and internal standards | Less direct control over day-to-day operations and some tooling decisions |
Speed to implementation | Slower if hiring, architecture, and operating processes all need to be built | Faster if the provider already has delivery patterns, coverage, and support |
Business context | Context stays close to product, finance, ops, and GTM teams | External teams need repeated onboarding to understand definitions and exceptions |
Self-service readiness | Better for building shared metrics, semantic layers, and analyst relationships | Often weaker unless someone internal owns definitions, adoption, and governance |
Specialized expertise | Depends on current team depth | Useful for platform administration, recovery, security operations, and maintenance |
Long-term flexibility | Better for custom workflows and product-linked use cases | Better for standardized functions with clear service boundaries |
When in-house is the better choice
Build more internally when data is part of how the company competes, not just how it reports. Product-led companies, usage-based businesses, and teams with frequent pricing, lifecycle, or experimentation changes usually benefit from having data modeling and governance close to product and revenue leaders.
This path also makes sense when leadership is serious about self-service. Self-service analytics does not come from handing business users a BI tool. It comes from repeated work on definitions, ownership, documentation, permissions, and semantic consistency. Those are operating habits, not vendor features.
A similar decision pattern shows up in other functions. The logic in in-house marketing vs agency applies here too. Keep strategy and differentiated knowledge close to the company. Use outside specialists where repeatable execution matters more than internal depth.
When managed services make sense
Managed services are often the right call when the company needs reliability first. If analysts are acting as part-time platform engineers, or if a small team is buried in connectors, failed jobs, access requests, and cloud admin, buying support can be the cheaper option even if the monthly invoice looks higher.
The key is scope. A provider can run infrastructure well and still fail your business if no one internally owns the metric layer. Before deciding, it helps to review the usual buy versus build trade-offs in data systems. The strategic mistake is not using a vendor. It is outsourcing the parts of the data function that determine whether teams can trust and use data without opening a ticket.
Do not outsource accountability. Even with a provider, someone inside the company must own definitions, priorities, access rules, and business alignment.
For many startups, the best model is mixed. Keep semantic modeling, KPI governance, and user enablement in-house. Use managed services for the infrastructure-heavy layers that would otherwise consume the same people you need to build a data-enabled organization.
Your Vendor Selection and Implementation Roadmap
A founder usually feels the data problem at the worst possible moment. The board deck is due, sales and finance are using different revenue numbers, product wants self-service access, and the data team is stuck comparing dashboard logic instead of fixing the system. That is the context for vendor selection. The job is to choose a partner and rollout plan that reduce dependency on analysts over time, not one that creates a cleaner version of the same bottleneck.
What to check before you buy
Strong demos hide operational friction. A vendor can look polished for 45 minutes and still fail once it meets your permission structure, inconsistent source naming, undocumented metric logic, and real support load.
Check five things before you sign:
Integration fit: Can the provider work with your warehouse, core operational systems, and identity setup without creating extra copies of data you will later have to govern?
Governance model: Can data access, metric ownership, and approval flows be managed in a way that supports wider self-service without creating security risk or definition sprawl?
Operational visibility: Will your team be able to see failed jobs, freshness issues, lineage, and ownership clearly, or will support depend on opening tickets with the vendor?
Scalability in practice: Can the setup absorb new business domains, changing logic, and higher query volume without a redesign six months later?
Support quality: When something breaks, do you get implementation help from people who understand pipelines, modeling, and access controls, or only an account layer that relays messages?
The practical test is simple. Ask whether this vendor helps your company answer more questions without analyst intervention, while keeping shared metrics trustworthy. If not, the service may improve infrastructure hygiene but still miss the business goal.
The buying logic is similar to other outsourced functions. The same judgment used in in-house marketing vs agency decisions applies here. Look closely at handoff quality, speed of execution, and how much company context an outside partner can realistically absorb.
The roadmap that avoids rework
Teams get into trouble when they treat implementation like a tool installation. Good implementations change operating habits, ownership rules, and how business users get answers. That takes sequencing.
Phase 1 discovery and audit
Start with the current failure points, not the future architecture diagram.
Map your source systems, critical dashboards, key metric definitions, access patterns, manual workarounds, and known trust issues. Then tie each of those to a business consequence. Which weekly reviews slow down because numbers are disputed? Which teams export data into spreadsheets because the approved dashboard does not answer the actual question? Which metrics change meaning across sales, finance, and product?
A short, honest audit beats a long planning document built on assumptions.
Phase 2 strategic planning
Choose business outcomes first. Common examples include faster board reporting, consistent pipeline numbers, cleaner revenue reporting, safer access for non-technical teams, and a smaller analyst request queue. “Modernize the stack” is a budget line, not an outcome.
Set scope with discipline. Pick the first domain, decide which datasets will be governed first, assign business and technical owners, and define what self-service should mean in practice. For one company, that may mean certified KPI dashboards with drill-down access. For another, it may mean controlled ad hoc exploration for product managers. Those are different designs.
Decision test: If the first phase tries to standardize every source, rebuild every dashboard, and settle every metric dispute, the scope is too broad.
Phase 3 phased execution and migration
Roll out in controlled waves. That lowers risk and gives the business a chance to adopt new habits before the next domain goes live.
A few patterns work well:
Start with one business domain: revenue, customer health, and product usage are common starting points because they affect frequent decisions.
Run old and new in parallel for a short period: compare outputs, find logic gaps, and fix trust issues before cutover.
Certify shared datasets before broad access: self-service fails quickly when users are pointed at unstable tables or conflicting definitions.
Train by role: an executive, a RevOps lead, and a product manager do not need the same workflow or level of detail.
The point of migration is not to move reporting to a new home. It is to reduce repeated requests to the data team while improving consistency.
Phase 4 optimization and governance
Go-live is where the critical test starts. If governance stops after launch, the system drifts back toward duplicate reports, conflicting metrics, and side-channel analysis in spreadsheets.
Review how people use the new setup. Identify where users still bypass the approved path. Tighten definitions, retire duplicate assets, add monitoring where failures create business risk, and update access controls as teams and responsibilities change. A metric layer that supports self-service today can become confusing fast if ownership is vague.
A useful operating rhythm often includes:
Monthly ownership review
Change control for shared metrics
Freshness and quality checks on critical datasets
A clear intake path for new self-service use cases
Vendor selection is an operating model decision. Choose the provider your team can work with under real conditions, and the one most likely to help the business move from ticket-driven reporting to trusted self-service analytics.
Measuring Success with ROI and Key KPIs
Data management work often gets approved as infrastructure and judged as overhead. That’s a mistake. If you want durable support from founders, finance, and the board, you need to tie the work to operating outcomes.
The cleanest way to do that is to measure success in two buckets. First, direct efficiency gains. Second, decision velocity and trust.
Start with business friction
Before choosing KPIs, identify where the current system wastes effort. Common examples include analysts answering repeat questions, teams reconciling conflicting numbers before meetings, and leaders delaying decisions because the data isn’t trusted. Those are measurable problems even if the fix spans multiple tools and processes.
A good KPI set usually includes a mix like this:
Time to insight: how long it takes a business user to get a reliable answer to a recurring question
Analyst capacity shift: whether the team is spending less time on ad hoc pulls and more time on modeling, experimentation, and strategic analysis
Report consistency: whether core dashboards and recurring business reviews rely on the same certified definitions
Data quality trend: whether freshness, completeness, and validation issues are decreasing
Self-service adoption: whether non-technical teams can answer more questions without direct analyst intervention
Avoid vanity metrics
The wrong KPI is often the easiest one to collect. Number of dashboards created, number of tables in the warehouse, and number of connectors deployed may describe activity, but they don’t prove business value.
A better question is whether the company now makes faster, better, safer decisions.
For example, if governance is working, fewer meetings should be spent arguing over whose number is right. If modeling is working, product and finance should stop maintaining parallel definitions for revenue or active customers. If self-service is working, the queue of basic requests should shrink.
A healthy data management program doesn’t just produce more assets. It reduces dependence on heroics.
How to frame ROI credibly
You don’t need invented math to make the case. Keep it practical.
Show where labor is being redirected from repetitive request handling to higher-value work. Show where reporting cycles have become more reliable. Show where executives can access trusted views without custom pull requests. Show where governed access lowers risk while still increasing usage.
If your company uses managed services, include infrastructure stability and support burden in the equation. If you built in-house, include whether the team can support growth without multiplying headcount around every new business question.
The strongest ROI stories combine both hard and soft outcomes. Hard outcomes are easier operations, lower rework, and cleaner platform ownership. Soft outcomes are trust, speed, and organizational confidence in the numbers. In practice, the soft outcomes often matter more, because they change how the company operates every day.
The Self-Service Future with Querio's Approach
A lot of companies think they want better dashboards. What they usually want is a company that can answer questions without waiting in line.
That’s a different goal. It requires more than tidy pipelines and decent governance. It requires a model where business users can explore data safely, technical users can go deeper without tool lock-in, and the central data team stops acting like a ticket queue.
Why traditional self-service often stalls
Most BI rollouts promise democratization and deliver dependency with better styling. Business users still need someone to build the right semantic layer, tune the model, resolve edge cases, and maintain custom logic. Technical users hit another wall when the tool becomes too rigid for deeper analysis.
That gap is especially visible in the mid-market. A 2025 Forrester survey indicates that 62% of mid-market companies struggle with governed self-service access, creating the “human API” pattern where non-technical teams still depend on analysts for basic answers, as discussed in Keboola’s piece on self-service data management challenges.
The problem usually isn’t ambition. It’s the mismatch between what the business needs and what traditional tools make easy.
What a better model looks like
The practical target is simple:
The warehouse remains the source of truth
Permissions stay governed
Business users can ask and iterate without filing tickets
Technical users can work in flexible environments, not narrow dashboard builders
The data team focuses on infrastructure, standards, and effectiveness
That’s where notebook-driven and warehouse-native approaches are useful. They allow exploration, analysis, and reusable workflows in the same environment, instead of forcing every question into a prebuilt dashboard or every advanced question into a bespoke analyst project.
One example is Querio, which deploys AI coding agents directly on the data warehouse and uses a file-system approach with custom Python notebooks so technical and non-technical users can query, analyze, and build on company data without waiting for analysts. That operating model matters because it shifts the role of the data team from answer provider to platform owner.
What changes when self-service is real
The biggest change isn’t technical. It’s organizational.
Product managers stop asking for every cut through Slack. Operators can investigate issues with guardrails. Analysts spend more time improving models and less time copying logic between one-off requests. Founders get faster access to trustworthy views without creating reporting chaos.
That doesn’t remove the need for governance. It raises the value of it. Self-service only works when access, definitions, and trusted datasets are in place. Otherwise you get a larger number of people making faster mistakes.
The goal isn’t to eliminate the data team. It’s to stop using highly trained people as manual routing layers for every question in the company.
The domain of data management services addresses the results most leaders prioritize. Not cleaner tables for their own sake. Not a prettier architecture diagram. A business that can move faster because more people can work from the same trusted data without waiting for permission, translation, or custom extraction.
If your team is stuck in analyst queue mode and you want to move toward governed self-service on top of your warehouse, Querio is worth evaluating. The product is built for companies that need flexible, notebook-driven analytics without turning the data team into a permanent request desk.

