Business Intelligence
governed self service BI best practices
Balance autonomy and control in self-service BI: define roles, build a centralized semantic layer, connect live to data warehouses, enforce RLS/CLS, and train users.
In today’s fast-paced business world, balancing quick access to data with maintaining consistency and security is a common challenge. Governed self-service BI offers a solution, allowing non-technical users to explore data while IT teams ensure data quality and security. Without governance, self-service BI can lead to chaos, like inconsistent reports and compliance risks.
Key takeaways:
Governance prevents "shadow BI" by centralizing data definitions, ensuring consistent metrics (e.g., "revenue" or "churn").
Hybrid models are growing: 41% of organizations are expected to adopt governed self-service BI by 2025.
Success stories: Companies have cut reporting time by up to 80% and reduced forecast errors significantly.
Steps for data governance implementation:
Define user roles and permissions.
Use a centralized semantic layer for consistent data definitions.
Connect directly to data warehouses for real-time access.
Provide training tailored to different user roles.
Governed self-service BI ensures faster insights, better decision-making, and secure, reliable data access.
Core Principles of Governed Self-Service BI
Balancing User Freedom with Central Control
Governed self-service BI thrives on striking the right balance between user autonomy and centralized oversight. Overregulation pushes users back to unstructured tools like spreadsheets, while lax governance leads to inconsistent metrics and data chaos [10]. A centralized hub model offers a middle ground. In this setup, a Center of Excellence provides certified, enterprise-grade semantic models, while business teams create tailored reports using this governed foundation [1].
This model redefines IT’s role. Rather than being report creators, IT becomes a guide - helping users access the right data, advising on tools, and scaling business-led solutions effectively [2][7]. JPMorgan Chase exemplifies this. Sriram Belur, Head of Business Intelligence Delivery Center, highlighted their success:
"Allowing self-service in one of the most highly regulated spaces - having the standard platform, the right data controls and the right governance... users love it because they don't have to wait for IT and IT loves it because they have happy users" [5].
Organizations can implement tiered governance models tailored to their needs. Centralized governance is ideal for industries with strict regulations and sensitive data. Delegated governance works for organizations building analytical skills across departments, while self-governing models suit teams with strong data literacy and clear content promotion processes [5][1]. To ease into this, start with a "lighthouse" domain - test governance practices within one business unit, gather feedback, and refine before scaling across the enterprise [1].
Next, let’s explore how maintaining data consistency strengthens this balance.
Why Data Consistency and Accuracy Matter
Trust in analytics starts with reliable data. When data is accurate and complete, users can focus on uncovering insights instead of verifying numbers [8]. Without consistent data definitions, "Shadow BI" emerges, leading to debates over KPIs and wasted resources [11][12].
PepsiCo’s experience showcases the impact of unified data definitions. Their Collaborative Planning, Forecasting, and Replenishment team implemented a modern analytics platform, reducing analysis time by 90% and replacing error-prone manual processes in Excel and Access [8].
A shared business glossary is key to avoiding misinterpretation. Metrics like "Churn Rate" or "Revenue" must mean the same thing across departments to minimize alignment meetings and maximize decision-making [12]. Labeling datasets as "Promoted" or "Certified" ensures users know which data sources are vetted for accuracy and quality [12]. This clarity not only avoids conflicts but also reinforces governance throughout the organization.
Security and Compliance Requirements
Governed self-service BI isn’t just about control and consistency - it’s also about protecting sensitive data and meeting compliance standards.
Identity-based access controls form the foundation. Using Row-Level Security (RLS) and Object-Level Security (OLS), align access permissions with user roles to ensure individuals see only the data they’re authorized to view [1]. This safeguards sensitive information while maintaining self-service flexibility.
Incorporate tools like sensitivity labels and Data Loss Prevention (DLP) policies to secure data across the BI ecosystem [1]. Audit logs and usage analytics are essential for tracking data access, identifying protocol deviations, and flagging potential breaches [1][9]. Alarmingly, 80% of organizations report some teams still operate siloed systems for data management - posing serious security risks [9].
To further strengthen governance, establish deployment pipelines with distinct Dev, Test, and Production environments. Automate checks to ensure only validated, secure content is deployed to end-users [1]. Regularly review access permissions and recertify licenses to align with current roles [1]. Pair these technical measures with ongoing data literacy and security training to help employees understand policies and responsibly use data [9].
Self-Service Data Analytics and Governance at Enterprise Scale with Unity Catalog
How to Implement Governed Self-Service BI
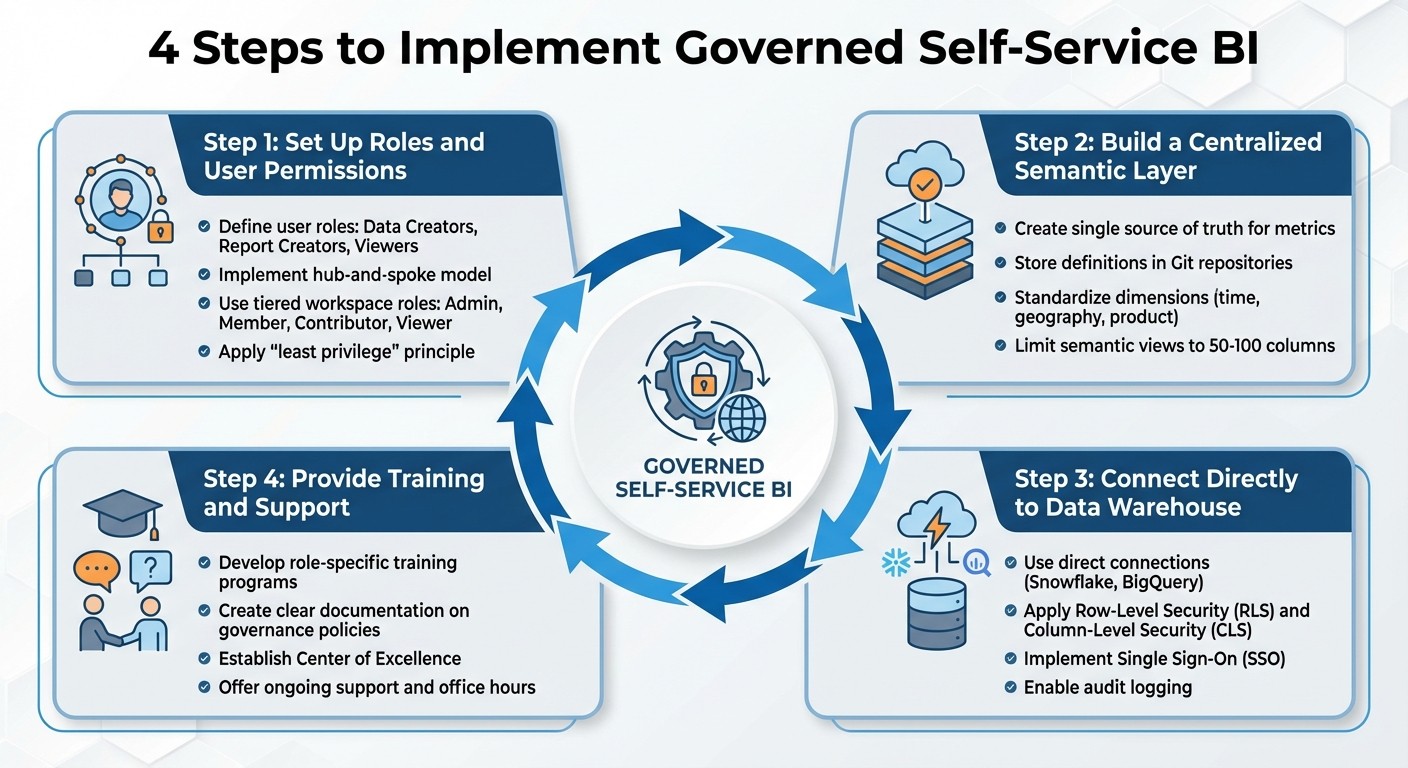
4-Step Implementation Guide for Governed Self-Service BI
To successfully implement governed self-service BI, organizations need a structured approach. This involves focusing on four key areas: defining user roles, creating a centralized semantic layer, establishing direct connections to data warehouses, and providing comprehensive training. Together, these elements create a balanced system where users can explore data freely while maintaining governance and data integrity.
Set Up Roles and User Permissions
Start by classifying users based on their responsibilities. For example, Data Creators focus on building semantic models, while Report Creators design visualizations. This separation ensures that core data definitions remain intact while allowing flexibility for custom reports.
Adopt a hub-and-spoke model to manage governance effectively. The "Hub" consists of certified, secure data models maintained by a central team, while the "Spokes" represent business units creating reports based on those trusted models. Use tiered workspace roles to control access:
Admin: Full control over all aspects.
Member: Can manage and publish content.
Contributor: Focuses on creating content.
Viewer: Has read-only access.
Store semantic models in secured repositories separate from report workspaces. This centralization ensures data consistency while giving users room for creativity. Permissions should follow a "least privilege" principle, granting only the access necessary for each role. Implement formal workflows for requesting access, requiring business justification for "Build" permissions. Limit who can "Certify" datasets, ensuring certified content adheres to quality standards and formal support processes.
Once roles and permissions are in place, the next step is to standardize data definitions through a centralized semantic layer.
Build a Centralized Semantic Layer
A centralized semantic layer acts as a single source of truth, defining metrics, joins, and business logic consistently across all BI tools like Tableau, Power BI, or Excel. This approach eliminates discrepancies, such as conflicting figures for the same metric across departments.
Collaboration is key: business teams should outline use cases, while data engineers manage technical access. Store data definitions in Git repositories to enable peer reviews, track changes, and allow rollbacks when needed. For efficiency, semantic views should ideally include no more than 50–100 columns.
Create standardized dimensions for attributes like time, geography, and product, which act as the "glue" for combining datasets. Include a dedicated metric_time dimension to ensure consistent time series alignment, avoiding misleading trends. Organize metrics hierarchically by business unit or team to make them easier to navigate, especially for non-technical users.
With standardized data definitions in place, ensure users have real-time access by connecting directly to your data warehouse.
Connect Directly to Your Data Warehouse
Direct connections to data warehouses like Snowflake or BigQuery eliminate data duplication and ensure users always work with the most recent data. Apply fine-grained access controls, such as Row-Level Security (RLS) and Column-Level Security (CLS), to restrict access based on roles.
Use Single Sign-On (SSO) to pass user identities from the BI tool to the data warehouse for seamless permission checks. This setup enhances security, enables transparent auditing, and automatically enforces warehouse-level access controls. For users who shouldn't have direct warehouse access, bind the BI model to a service account with specific permissions.
Enable audit logging to monitor data usage and access patterns. Use zero-copy data sharing to create live pointers to shared assets, avoiding unnecessary duplication. Certify high-demand datasets, like those for revenue or customer analytics, as trusted sources. Conduct regular data quality scans to catch issues before they affect dashboards.
Finally, equip users with the knowledge and resources they need to succeed.
Provide Training and Support
Effective training is essential to help users navigate the governed self-service BI environment. Develop concise, role-specific training programs tailored to different user groups:
Data Creators: Focus on semantic modeling and data warehouse connections.
Report Creators: Learn how to use certified models without altering underlying logic.
Viewers: Gain basic skills in interpreting visualizations and understanding data limitations.
Provide clear documentation on governance policies, including the meanings of labels like "Certified" and "Promoted." Explain when and how to report data quality concerns.
Establish a Center of Excellence to offer ongoing support. This team can host office hours, maintain a knowledge base for common questions, and assist users with troubleshooting. Use audit logs to track usage patterns, identifying areas where users struggle and updating training materials accordingly. As Daniel Trimmer, Senior Manager of Product Facing Solutions at Abercrombie, explained:
"Our definition of governance... has altered in a way. It used to be self-service - get whatever data you want, but we can't guarantee where it came from - to now building standards and consistency around it" [5].
How Querio Supports Governed Self-Service BI
Querio builds on established practices for governed self-service BI by offering essential BI tool features: a shared context layer for standardized definitions, transparent code generation to eliminate "black box" analytics, and secure live connections to data warehouses. These features ensure quick, reliable insights while maintaining control. By combining speed with governance, Querio strengthens the core principles of consistency, transparency, and security in self-service BI.
Shared Context Layer for Consistent Metrics
Querio's shared context layer ensures that metrics, joins, and business logic are defined once and applied universally - whether for ad hoc analysis, dashboards, or AI-generated insights via a natural language interface. This centralized setup provides uniformity across all reports.
The context layer also makes metadata, lineage, and definitions available to Querio’s AI system. This ensures AI-generated queries follow governed business logic, avoiding inconsistent or misleading results. Kathryn Chubb from dbt Labs highlights the importance of structure in self-service BI:
Speed without structure leads to problems: broken dashboards, stale metrics, and a loss of trust in the data team [4].
By consolidating definitions and transformations, Querio reduces redundant work and eliminates the need for constant context switching, which often slows analysts down [14][4].
Additionally, users can independently trace model lineage and access trust signals, making it easier to debug issues or confirm data freshness. This level of traceability is especially useful as nearly half of organizations blend self-service capabilities with centralized governance [3].
Transparent AI-Generated SQL and Python
Every answer generated by Querio comes with fully reviewable and editable SQL or Python code. This transparency eliminates the "black box" issue that often undermines trust in AI-powered analytics. By allowing users to see exactly how metrics are calculated, Querio empowers them to validate logic, identify potential issues, and make informed decisions.
This inspectability serves multiple roles. For analysts, it acts as both a learning tool and a way to ensure that AI-generated outputs align with business needs. For compliance teams, it provides an auditable record of data transformations, supporting regulations like GDPR and CCPA [3]. For data teams, it ensures that self-service users operate within approved business logic while maintaining momentum.
This approach addresses a key challenge: only 32% of organizations report "very successful" adoption of pure self-service BI. This often stems from users either lacking the technical expertise to validate results or being unable to trust outputs they cannot verify [3].
Secure Live Data Warehouse Connections
Querio connects directly to data warehouses such as Snowflake, BigQuery, Amazon Redshift, and ClickHouse. By maintaining live, read-only access, Querio queries data in place, ensuring analyses always reflect the most up-to-date information without duplicating data [15].
To enforce security, Querio leverages warehouse-native features like IAM, RBAC, and VPC controls. This ensures granular, live, read-only access, adhering to "zero-copy" principles that reduce risks and prevent unauthorized data movement [15].
This architecture aligns with the growing preference for "warehouse-native BI", where tools prioritize secure, live connections over moving data into unregulated environments [3]. By keeping data within the warehouse’s security framework, Querio ensures governance policies, access controls, and audit logs remain centralized. This is crucial, especially since around 80% of self-service analytics initiatives fail when treated as mere software purchases rather than strategic programs requiring robust data architecture [16].
How to Measure Success
Metrics That Show Success
Tracking the right metrics is key to ensuring your governed self-service BI platform is doing its job - maintaining data consistency while encouraging user engagement. Start by keeping an eye on Monthly Active Users (MAU) and the number of active content creators. If these numbers plateau or drop, it might be a sign that users are slipping back into old habits, like relying on spreadsheets.
Another critical metric is the ratio of certified to total artifacts. A higher percentage of "Certified" or "Promoted" datasets indicates that users trust the system and are sticking to approved data sources. Metrics like time-to-insight and fewer conflicting reports also show that your semantic layer is doing its job in keeping data consistent.
Don’t overlook technical performance. Regularly check data refresh success rates and query performance. Additionally, track how often users refer to the central business glossary - this shows whether they understand and trust the metrics they rely on. Together, these metrics paint a clear picture of how well governance is balancing quality with adoption. As David Stodder from TDWI puts it:
The self-service genie is not going back in the bottle. Self-service BI and analytics are here to stay. [2]
Fixing Problems and Making Improvements
When metrics start to stray from expectations, it’s time to take action. Look for signs of governance issues. For example, the rise of shadow BI - users creating their own processes outside of the system - can point to underlying frustrations. Duplicate workspaces or a flood of similar reports might mean users are struggling to locate or trust the content they need. Even high view counts can signal a problem if certified datasets aren’t being used, suggesting access barriers or usability issues.
To address these challenges, consider running periodic "App Rationalization" sprints to clean up duplicate reports and streamline the system. A Center of Excellence (CoE) can also help by offering "Fix-It" clinics and office hours, reducing user friction without shutting down self-service entirely.
Adopting a tiered governance approach can also help strike the right balance. For example, core systems like ERP and CRM can have stricter controls, while departmental analyses can operate with more flexibility. Karen Robito from P3 Adaptive explains it well:
Traditional governance doesn't fail because it's too strict. It fails because it treats control and speed like they're opposites. [6]
Finally, test improvements in a smaller business unit first. Use the feedback from these pilots to refine your governance practices and ensure they continue to evolve effectively.
Conclusion
Governed self-service BI strikes a balance between control and freedom. When done right, it empowers business users to explore data and find answers independently, without waiting on IT, while ensuring the organization maintains consistent, secure, and reliable data for decision-making. This balance enables fast and secure insights across the board.
The guide outlines key practices to achieve this, such as defining clear roles, utilizing a centralized semantic layer, connecting directly to data warehouses, and providing ongoing training. However, governance isn’t a one-and-done task - it’s a continuous process. As your team’s analytical capabilities expand and business needs shift, governance must adapt. Kathryn Chubb from dbt Labs captures this well:
High-performing teams shift their focus from 'how many questions can we answer' to 'how many people can we enable to answer their own questions, safely.' [13]
These principles not only maintain governance but also open the door to infrastructure solutions that support innovation. Querio aligns with this vision by providing tools that make governed self-service BI feasible. Features like the Shared Context Layer ensure everyone uses consistent definitions, transparent AI-generated SQL and Python build trust by showing how insights are derived, and secure live data warehouse connections eliminate risky shortcuts that lead to shadow BI. With Querio, IT evolves from being a gatekeeper to becoming an enabler, creating guardrails for safe, user-driven analytics.
Start small - pilot governance in one area, measure key metrics, and fine-tune your approach. This strategy can unlock trusted, scalable insights, giving your organization the speed and flexibility to adapt without compromising stability.
FAQs
How do we stop “shadow BI” without slowing teams down?
To tackle "shadow BI" - when data analysis happens without proper oversight - without stifling team productivity, it’s crucial to strike the right balance in governance. This means ensuring access to reliable, high-quality data through well-defined policies, certified datasets, and tracking data lineage. Think of it as a "Goldilocks" approach to governance: not overly restrictive, but not too loose either. This balance allows teams the freedom to work independently while keeping essential controls in place. By fostering collaboration between IT and business departments and using tools designed for governed data discovery, organizations can maintain flexibility without sacrificing accuracy or security.
What should go in a centralized semantic layer first?
Creating a well-organized data catalog is a crucial first step. By systematically arranging data objects - like tables, views, and sources - you make it easier for users to find, navigate, and manage information. This setup not only simplifies discovery but also supports better governance, ensuring consistency and accuracy throughout your self-service BI environment.
How do we enforce security (RLS/CLS) and still keep self-service easy?
To implement row-level security (RLS) and column-level security (CLS) effectively while keeping self-service analytics simple, embed security measures directly into your data models. This approach ensures that security rules are consistently applied, conceals restricted data to reduce confusion, and eliminates the need for complicated setups. By weaving security into the background, users can interact with data effortlessly, striking the right balance between governance and user accessibility.
Related Blog Posts


