Text Analytic Software: The Self-Serve Guide for 2026
Unlock insights from customer feedback. Our guide to text analytic software covers capabilities, use cases, and how to build scalable, self-serve workflows.
https://www.youtube.com/watch?v=BeDeHntF68M
published
Outrank AI
text analytic software, text analysis, nlp software, customer feedback analysis, data analytics
33dc010d-fc16-4215-9111-9b22c073364e

You already have the data. It's sitting in app reviews, NPS verbatims, support tickets, sales call notes, onboarding chats, and renewal emails. Product leaders know this. Data leaders know it even more painfully, because they're usually the ones asked to “find the themes” after a launch goes sideways.
The common failure isn't lack of feedback. It's lack of workflow. Teams collect massive amounts of text, then trap it in disconnected tools, route every question through analysts, and wonder why nobody trusts the output or acts on it quickly. That's why text analytic software matters now. Not as a novelty layer on top of BI, but as the system that turns language into something operators can use.
Table of Contents
Why Your Unstructured Data Is a Goldmine (Or a Minefield)
A familiar pattern shows up in growing companies. Customer feedback exists everywhere, but no one can answer simple questions quickly. Why are churned customers frustrated? What changed in sentiment after the last release? Which complaints are isolated noise, and which ones signal a real product issue?

Without text analytic software, teams fall back on weak substitutes. They sample a few hundred comments, tag them manually, then present a neat summary that ages out almost immediately. Or they dump comments into spreadsheets and look for word counts, which tells you very little about meaning, intent, or severity.
That's why this category has moved into the core data stack. Text analytics software is projected to grow from US$12.1 billion in 2026 to US$35.9 billion by 2033, at a 16.8% CAGR, according to Mordor Intelligence's text analytics market forecast. The reason is straightforward. Traditional BI tools are built for rows and measures. They don't natively understand language.
Where teams get stuck
Most product leaders don't need another dashboard. They need a way to ask, “What are users complaining about in their own words?” and get an answer tied to actual evidence.
The trouble is that raw text behaves differently from structured events:
It's messy: The same issue appears in ten phrasings across reviews, chat logs, and surveys.
It's contextual: “Slow” might mean app performance, support response time, or onboarding friction.
It changes fast: New releases create new vocabulary. Static labels go stale.
Practical rule: If a team can measure clicks but can't systematically interpret customer language, it's running partial business intelligence.
Modern natural language processing for business closes that gap. It turns text into themes, sentiment, entities, and intent signals that product, support, and operations teams can use without reading every line by hand.
The upside is real. The risk is just as real. Unstructured data can become a goldmine when teams can query it reliably. It becomes a minefield when they overtrust brittle tools, disconnected workflows, or outputs nobody can audit.
Understanding Text Analytics From the Ground Up
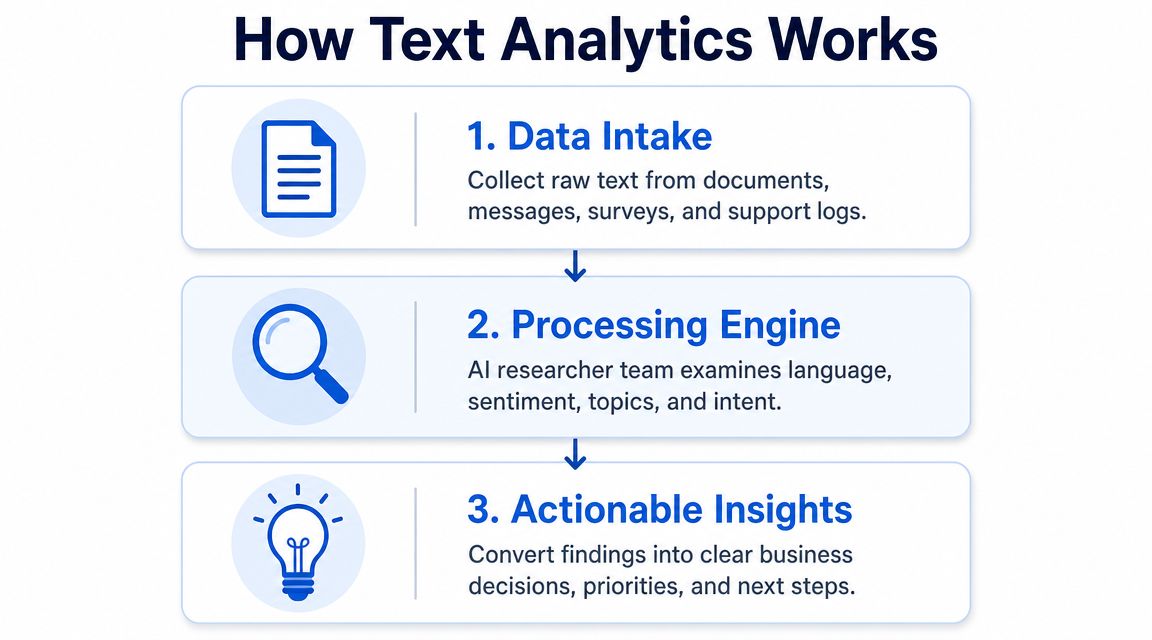
Text analytic software is easiest to understand if you think of it as a research team that never gets tired. It reads every review, ticket, transcript, and open-text response, then returns a structured picture of what people are saying.
That matters because around 80% of business data today is unstructured, as summarized in Thematic's market growth analysis. In practice, the shift to text analytics was inevitable. Companies couldn't keep scaling manual review while more customer interaction moved into digital channels.
What the software is really doing
Under the hood, most platforms perform a sequence of jobs. The details vary, but the operational goal is the same: convert raw language into analyzable outputs.
A simple way to think about the workflow:
Ingest the text Raw inputs come from review sites, CRMs, support platforms, survey tools, chat systems, and document stores.
Normalize the language The software breaks text into parts it can interpret. Many traditional tools become cumbersome for non-technical teams during this specific process.
Assign meaning The engine identifies patterns such as tone, topic, referenced entities, or likely intent.
Return usable structure The result becomes filterable and comparable. Teams can sort by issue type, product area, time period, region, account segment, or release cohort.
The outputs that matter to product teams
Not every output deserves equal attention. A polished demo often shows many features, but a few capabilities tend to matter most in practice.
Sentiment analysis: Useful when you need directional readouts across large volumes of feedback. It helps answer whether a launch, policy change, or support experience shifted customer tone.
Topic or theme detection: This is usually the highest-value layer. It tells you what people are talking about, not just whether they're happy.
Named entity recognition: Helpful when users mention specific products, features, competitors, workflows, or locations in free text.
Intent classification: Important when the goal is to identify what a customer is trying to do, such as requesting a feature, reporting a defect, asking for help, or signaling cancellation risk.
Good text analytics doesn't replace close reading. It tells you where to read closely.
That last point matters. Teams sometimes expect the tool to produce final truth. It won't. What it should do is compress search space. Instead of reading ten thousand comments blindly, the PM can review the clusters most likely to explain a metric change.
A practical test is whether the output helps someone take action. If sentiment scores move but nobody can connect that movement to a feature, workflow, or customer segment, the system is reporting motion rather than insight.
How Different Text Analytics Tools Actually Work
Two platforms can both claim to do sentiment, categorization, and theme extraction, yet behave very differently once the data gets messy. That difference usually comes from architecture, not marketing.

The most important split is simple. Some systems require you to define the world in advance. Others learn from the text itself.
Top-down systems versus bottom-up discovery
A top-down tool starts with a taxonomy. You define categories like billing, onboarding, bug, feature request, performance, and support quality. The model or rules then sort incoming text into those bins.
That approach works when your business already has stable labels and you mainly want consistency. It's common in compliance monitoring and tightly controlled service workflows. The weakness appears when language changes or new problems emerge. The system can only classify what it has been told to recognize.
A bottom-up system starts from raw text and learns recurring themes without requiring predefined categories. According to Thematic's explanation of bottom-up theme discovery, this approach is especially valuable because it can surface both known patterns and emerging issues that weren't anticipated in advance.
Here's the practical trade-off:
Approach | Works well when | Fails when |
|---|---|---|
Top-down taxonomy | You need controlled labels and repeatable reporting | New issues appear outside the schema |
Bottom-up discovery | You need to detect change and uncover unknown themes | Teams need strict category governance from day one |
For product teams, bottom-up discovery is often better at catching reality early. A release creates a new complaint pattern. Users invent their own language for it. A rigid taxonomy misses it until someone manually updates the system.
If your model only confirms what you already expected, it's helping with reporting, not discovery.
A similar distinction shows up in adjacent domains. In publishing and content operations, teams choosing metadata workflows face the same choice between rigid templates and adaptive systems. This practical guide for authors is useful because it shows how structure helps, but only when it doesn't lock teams into stale categories.
What pipeline control changes in practice
There's another layer experienced buyers pay attention to: how much control the platform gives over the NLP pipeline itself. Some tools behave like black boxes. Others expose controls that matter when industry jargon, abbreviations, or multilingual inputs make generic models unreliable.
Lexalytics describes its Salience NLP engine as able to process over 200 tweets per second and notes that teams can tune tokenization, part-of-speech tagging, sentiment scoring, categorization, and theme analysis while integrating through Java, PHP, Python, and .NET/C#, as outlined in Lexalytics' overview of enterprise text analytics controls.
That matters less in a polished demo than in production. In real environments, terms don't behave generically. “Ticket closed” may signal success in one workflow and failure in another. “Lightweight” may be praise for one product and criticism for another.
A more applied walkthrough of this issue appears in this sentiment analysis on reviews guide, especially if your team works with app-store feedback or ecommerce reviews where sarcasm, shorthand, and product names distort naive sentiment models.
A short overview helps if you want to see how these differences show up in practice:
Effective performance depends on matching the architecture to the specific task. Failure occurs when purchasing based on a feature checklist without understanding whether the system is designed to discover, classify, or provide text with decorative labels.
Key Criteria for Selecting Text Analytics Software
A text analytics demo can look convincing in thirty minutes. Production reality shows up later. The right buying questions are less about whether a vendor has sentiment analysis and more about whether your team will still trust and use the system six months after rollout.
Four filters that separate good demos from useful systems
Domain adaptability comes first. If the system can't learn your product language, support shorthand, and customer vocabulary, output quality drops fast. Generic models struggle with industry-specific phrasing, internal acronyms, and terms whose meaning changes by context. Ask how the platform handles jargon drift and whether teams can tune behavior without rebuilding everything from scratch.
Scalability isn't just volume. It includes latency, concurrency, and operational reliability. Some tools work well on sampled survey data but slow down or become expensive when you add support tickets, reviews, chats, and sales notes in one workflow. Buyers should test realistic loads and realistic messiness, not just clean CSV exports.
Integration is usually underestimated. If the product reads from one source elegantly but creates friction everywhere else, adoption stalls. You want a system that fits where your text already lives and where your metrics already get trusted. Teams evaluating modern analytics stacks can borrow some useful thinking from this checklist for evaluating text-to-sql models in BI, especially around governance, reliability, and user trust.
Accessibility decides whether the initiative spreads or bottlenecks. A tool that only specialists can operate may still be useful, but it won't create self-serve insight. Product managers, support leads, and executives need interfaces and workflows they can use without waiting in an analytics queue.
A practical evaluation list looks like this:
Ask for messy data tests: Use raw tickets, duplicate reviews, vague survey responses, and mixed-quality exports.
Check explainability: Can users inspect examples behind a theme or sentiment label?
Probe the handoff cost: How much analyst setup is required before business users can ask useful questions?
Audit integration paths: Native connectors matter, but so does how the system fits your warehouse and governance model.
Buying advice: Don't choose the platform with the most features. Choose the one your product and data teams can operate together without creating a permanent service desk.
That's the line many teams miss. Text analytic software succeeds when it becomes part of operating rhythm, not an isolated specialist project.
From Standalone Tools to Warehouse-Native Analytics
Most text analytics projects don't fail because theme extraction is impossible. They fail because the workflow around the tool is wrong.
The common pattern is a standalone SaaS platform. Teams export data from Zendesk, Salesforce, Qualtrics, app stores, or internal databases, then upload files into a separate environment for analysis. It feels fast at first. Then the problems start.
Why the standalone model breaks down
Data gets stale. Definitions drift. Security reviews multiply. Analysts spend time moving data instead of improving logic. Product managers stop trusting outputs because they can't tell whether the latest complaints or release notes are even included.
That's why the upstream problem matters more than most vendor pages admit. Chattermill's discussion of text analysis software highlights a critical issue: organizations often lack unified access to text data because it's siloed across CRMs, support platforms, and survey tools. The core problem isn't just extracting themes. It's standardizing where text data lives so teams can query it without constant analyst intervention.
Warehouse-native approaches start from that reality. Instead of copying text into yet another tool, the analysis happens where governed company data already lives. That changes the workflow from “export, upload, transform, recheck” to “query, analyze, and share in place.”
Text Analytics Implementation Models Compared
Criteria | Standalone SaaS Tool | Warehouse-Native Approach |
|---|---|---|
Data movement | Frequent exports and uploads | Analysis runs where data already resides |
Freshness | Often delayed by sync schedules or manual refreshes | Closer to live operational data |
Governance | Separate permissions and policy reviews | Aligned with existing warehouse controls |
Analyst workload | High, because ingestion and reconciliation keep recurring | Lower, because teams work from unified tables |
Trust in output | Weakens when users suspect missing sources | Improves when source data is shared and inspectable |
Self-serve potential | Limited by app boundaries | Stronger when business users can query across systems |
The workflow difference is bigger than it sounds. In a standalone model, text analytics stays a specialty function. In a warehouse-native model, it becomes part of how teams investigate product issues, churn risk, launch feedback, and support quality alongside the rest of their operational data.
That also changes the role of the data team. Instead of acting as a human API that fields every request, they can build governed access patterns and reusable logic once.
Teams exploring that shift should look closely at warehouse-native data analysis tools for Snowflake, BigQuery, and Databricks. The useful question isn't “Does this vendor do text analytics?” It's “Can this workflow let product and operations teams answer customer-language questions directly from trusted data?”
What works now is integration first, analysis second. What doesn't work is adding another destination for already fragmented feedback.
How Querio Enables Scalable Self-Serve Text Analytics
The hardest part of text analytics isn't usually model selection. It's removing the operational friction that keeps business users dependent on analysts.
That friction is why adoption stalls. As noted in Zonka Feedback's write-up on text analysis tools, the primary bottleneck is often implementation complexity. Traditional tools require extensive preprocessing, which creates friction for non-technical users. The practical question becomes how to democratize text analysis so product managers can self-serve.
What self-serve looks like in practice
Querio's approach is built around that exact problem. It deploys AI coding agents directly on the data warehouse and uses a file-system model with custom Python notebooks, so teams can query and analyze text where company data already lives.
That changes who can do the work.
A product manager investigating a feature launch doesn't need to wait for a separate analytics project to begin. They can work against warehouse-resident app reviews, support tickets, and survey verbatims in one environment. A data lead can still enforce the right guardrails, but they no longer need to handcraft every intermediate step.
The difference shows up in the workflow:
The PM asks a concrete question: Which themes are rising in negative feedback after the release?
The system works on warehouse data: No manual exports into a side platform.
The output stays connected to context: Users can trace themes back to the underlying records.
The result is shareable: Teams can turn findings into repeatable analysis and dashboards without rebuilding from scratch.
This model matters because self-serve only works when technical and non-technical users operate in the same governed environment. If the tool is easy for business users but detached from trusted data, they'll get speed without confidence. If it's powerful for analysts but inaccessible to everyone else, the queue just moves to a different tool.
The best self-serve system is the one that lets the data team stop answering the same exploratory question twenty times.
That's where warehouse-native text analytic software has an advantage. It treats text as part of the broader analytics surface, not as an isolated specialty workload. For overwhelmed data teams, that's the difference between one-off insight generation and scalable internal capability.
The Future of Text Analytics Is Accessible and Integrated
Text analytics is maturing in the same direction as the rest of the data stack. Teams don't just want stronger models. They want fewer handoffs, fewer disconnected tools, and faster access to answers grounded in trusted data.
That's why the winning pattern is accessibility plus integration. Product leaders need to investigate what customers are saying without opening a ticket for every question. Data leaders need governance, reproducibility, and a workflow that doesn't create more operational drag than insight. Text analytic software earns its place when it supports both.
The broader lesson applies beyond feedback analysis. In search and content systems, teams also get more value when meaning is encoded in ways other systems can understand. This Raven SEO structured data strategy is a useful parallel because it shows how accessible structure improves downstream usability. The same principle holds in analytics. Structure only helps when people can work with it.
The future won't belong to the most crowded feature grid. It will belong to the platforms that make unstructured data queryable inside normal business workflows. That's how companies finally close the loop between customer language and product action.
If your team is sitting on support tickets, reviews, surveys, and CRM notes but still relies on analysts for every text question, it's worth looking at Querio. Querio brings AI coding agents directly to your warehouse so product, operations, and data teams can analyze text in a governed, self-serve workflow instead of pushing exports through another disconnected tool.

