Snowflake vs Redshift: Which Is Right for Your Startup?
Snowflake vs Redshift: An in-depth guide for startup and data leaders. Compare architecture, pricing, performance, and TCO to choose the right data warehouse.
https://www.youtube.com/watch?v=f5BJtcuZFZA
published
Outrank AI
snowflake vs redshift, data warehouse, cloud analytics, big data, aws redshift
05dd6bd3-f329-4db9-b317-ebaa80de93b1

Your company usually reaches this decision later than it should.
At first, the data stack feels fine. Product data lives in the app database. Finance exports CSVs. Marketing has a dashboard in one tool, success has another, and someone on the team knows enough SQL to answer the hard questions. Then the business grows. Board questions need consistent numbers. Product teams want funnel analysis without waiting three days. Sales wants territory reporting. Suddenly, the main bottleneck isn't storage. It's the fact that every answer depends on a few people stitching together data by hand.
That's when snowflake vs redshift stops being a technical debate and becomes a leadership decision. The warehouse you choose will shape how quickly your team can answer questions, how much engineering time goes into maintenance, and whether self-serve analytics is realistic or just something people say in planning meetings.
Both platforms are credible. Both can support a serious analytics program. But they reward different operating models. One tends to reduce day-to-day warehouse management and fit bursty, mixed workloads more naturally. The other often makes a lot of sense if you're firmly committed to AWS and your workloads are steadier and easier to predict. The right answer isn't about picking the tool with the louder marketing. It's about picking the one your team can run well.
Table of Contents
The Crossroads Every Growing Company Faces
A familiar pattern plays out in startups around the same stage. Revenue is growing. Teams are hiring. The executive team wants cleaner reporting. Product wants to understand activation and retention without filing a ticket every time. The data team, if there is one, is still small. Maybe it's one analytics engineer and one analyst. Maybe it's a backend engineer doing warehouse work after hours.
At that point, the old setup starts breaking in subtle ways. Metrics disagree across teams. Analysts spend more time reconciling definitions than answering questions. Founders lose trust in dashboards because every board deck requires a special cleanup pass. The immediate instinct is to ask which warehouse is faster or cheaper.
That's the wrong first question.
The harder question is which system your team can operate without turning your most expensive data people into maintenance staff. A startup doesn't just need a warehouse that runs queries. It needs one that supports decision-making without adding constant friction.
Most founders underestimate how much warehouse choice affects hiring efficiency. A platform that needs more babysitting changes what your first data hires spend their week doing.
Snowflake and Amazon Redshift sit at the center of this decision because they're both mature, widely adopted, and capable enough for serious analytics. But they don't create the same operating experience. One tends to favor flexible scaling and workload isolation. The other often fits companies that are already committed to AWS and value tighter ecosystem alignment with more predictable warehouse patterns.
If you're making your first major warehouse decision, the headline feature list won't help much. The key issue is whether your choice will make self-serve analytics easier to sustain as the company scales.
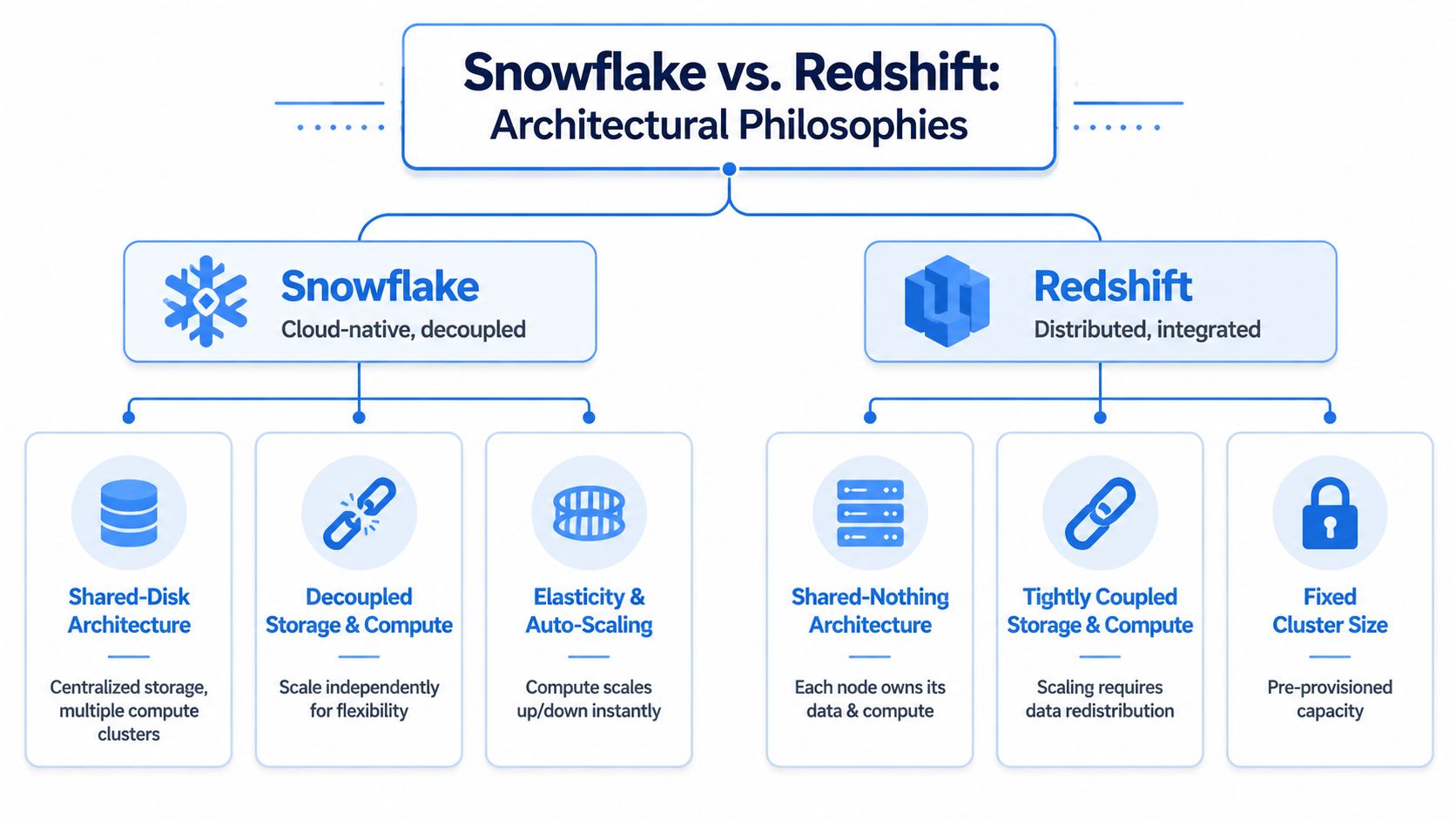
Core Architectural Differences That Drive Everything
The decision between Snowflake and Redshift starts with one question: how much operational coordination will your team need just to keep analytics working well as usage grows?
Snowflake separates storage and compute by default. That gives teams more freedom to scale compute for specific workloads without redesigning the whole system. Redshift has added more flexibility over time, but its model still asks teams to think more carefully about cluster sizing, node choices, and how capacity is provisioned.
That sounds technical. Its primary effect shows up in calendars and headcount.
At an early-stage company, warehouse demand is uneven. Finance runs month-end reporting. Product wants behavioral analysis after a launch. GTM teams refresh dashboards before pipeline review. An ELT job kicks off at the same time. In that environment, architecture determines whether people get answers quickly or start negotiating for warehouse time.
Snowflake usually creates less contention in mixed, bursty environments because compute can be isolated more easily across teams and use cases. Redshift can perform well, especially with steadier workloads, but it more often rewards teams that are willing to plan capacity and tune the system with intent. For a startup founder, that difference matters because every hour spent on warehouse management is an hour your data team is not spending on metrics, experimentation, or decision support.
A useful mental model is simple. Snowflake is generally easier to adapt to changing demand. Redshift generally asks for more upfront capacity planning and more deliberate operating discipline.
That trade-off affects self-serve analytics more than vendor demos suggest. If product managers, finance leads, and operators are all expected to query data directly through BI tools, the warehouse has to tolerate concurrency without constant intervention from the data team. If it cannot, self-serve turns into a support queue.
For a broader explanation of the design patterns behind these systems, this guide to data warehouse architectures gives helpful context.
The practical consequence for scaling
As usage grows, the architectural gap becomes an org design issue.
With Snowflake, the common pattern is to give different workloads their own compute layer so BI dashboards, transformation jobs, and ad hoc analysis are less likely to interfere with each other. That reduces the number of internal conversations about query contention, queueing, and whether someone needs to pause a job so another team can finish a report.
With Redshift, those conversations are often more relevant. That does not make Redshift the wrong choice. It means the platform fits best when workload patterns are more predictable, the company already runs heavily on AWS, and the team is comfortable owning more of the tuning and performance management. Some startups prefer that trade-off because it can align better with an existing AWS footprint and a more centralized data operating model.
Practical rule: If multiple teams and tools will hit the warehouse at the same time, architecture shapes the day-to-day user experience, not just system performance.
That is the difference leaders miss. This choice is not only about query speed. It is about whether your analytics stack stays usable as more teams depend on it, or whether growth adds quiet operational drag that forces your highest-impact people into warehouse babysitting.
A Practical Comparison of Key Features
A founder choosing a warehouse is usually not buying database features. They are choosing how much friction the team will absorb once analytics becomes a shared company system.
That changes how to read the comparison.
Snowflake vs Redshift At a Glance
Criterion | Snowflake | Amazon Redshift |
|---|---|---|
Core architecture | Storage and compute are separated by default through virtual warehouses | More cluster-oriented operating model, with separation depending in part on node strategy |
Best workload shape | Bursty, mixed, concurrent analytics | Steadier, predictable workloads, especially in AWS-heavy environments |
Concurrency behavior | Better aligned with workload isolation and multi-team access | Can work well, but scaling behavior is more tied to cluster planning |
Pricing pattern | Separate billing for compute and storage, compute billed per second, can suspend when idle | Often attractive for steady usage with reserved pricing |
Operational burden | Commonly described as more automated | Often involves more tuning and performance management |
Ecosystem fit | Strong for teams prioritizing flexibility and self-serve analytics patterns | Strong for teams already standardized on AWS |
If your broader data strategy still includes lake-style storage and raw ingestion, this guide to data warehouse vs data lake trade-offs provides the right framing.
Performance and concurrency
Raw speed usually gets too much attention. For an early-stage or growth-stage company, the better question is whether the warehouse stays usable when dashboards, dbt jobs, finance pulls, and ad hoc analysis all hit at once.
Panoply summarized one head-to-head comparison where query performance and per-query cost were very close between the two platforms, while also noting a practical split in pricing fit: Redshift often looks better for steady reserved usage, and Snowflake tends to fit intermittent demand better, according to Panoply's comparison of Snowflake and Redshift.
That should change the decision process. A near tie on benchmark-style speed does not help much if one platform creates more internal coordination every time usage spikes.
Snowflake usually makes more sense for mixed, unpredictable access patterns. A product manager can run exploratory SQL while finance refreshes a board deck and scheduled transformations continue in parallel, with less risk that one workload degrades everyone else's experience.
Redshift performs well for large-scale SQL analytics too, especially when workload patterns are known in advance and the team can shape capacity around them. In a disciplined AWS-centric environment, that can be a rational trade-off.
The deciding factor is often not peak performance. It is how much team time gets consumed keeping analytics reliable as more people depend on it.
Pricing and operating model
Snowflake's pricing model tends to land well with companies that have uneven demand. If usage clusters around weekday mornings, monthly reporting, launches, or investor prep, the ability to run compute only when needed can reduce wasted spend.
Redshift often fits better when demand is steady and leadership wants costs to map cleanly to a known operating pattern. Reserved pricing can be easier to forecast, especially for companies already managing infrastructure this way across AWS.
The finance view matters, but the team view matters just as much.
Bursty usage: Snowflake often maps better to the actual rhythm of work.
Steady usage: Redshift can be easier to model and justify on cost.
Shared self-serve environment: Snowflake often reduces the odds that one team's work slows everyone else down.
Centralized platform ownership: Redshift can work well if the company is comfortable dedicating more effort to warehouse operations.
A cheap warehouse that pulls analysts and engineers into repeated tuning work is rarely cheap in practice.
Ecosystem and workload fit
Company context should carry more weight than vendor messaging.
Snowflake tends to fit teams that want self-serve analytics to spread across functions without turning the data team into a traffic controller. That matters when the plan is to let finance, operations, product, and go-to-market teams answer more of their own questions directly.
Redshift tends to fit companies that already operate extensively inside AWS and prefer tighter alignment with that stack. Familiar tooling, permissions, and procurement can simplify adoption, even if the warehouse asks for more hands-on care over time.
For a startup founder, this is an operating model choice disguised as a tooling decision. Pick the platform that your current team can run well, and that your next few hires will not have to babysit.
The True Cost of Ownership and Operational Drag
Teams usually notice warehouse cost on the invoice. They notice operational drag in morale.

A founder might compare Snowflake and Redshift and focus on list pricing. That's understandable. The warehouse is a visible line item. But the more expensive cost often sits elsewhere. It shows up when analysts wait on performance issues, when engineers spend time resizing or tuning instead of shipping data products, and when every self-serve initiative turns back into a queue for the data team.
Where the hidden cost shows up
Qrvey's comparison makes an important point that many vendor summaries skip. Redshift performance often involves more day-to-day labor, including tuning sort keys, dist keys, vacuuming, workload management, and resizing, while Snowflake is consistently described as more automated in how teams operate it, according to Qrvey's discussion of Snowflake vs Redshift.
That difference changes what your team can accomplish with the same headcount.
If your first analytics engineer spends too much time keeping the warehouse healthy, that person isn't building trusted metrics, documenting definitions, or enabling product teams to answer questions on their own. A small data function can absorb only so much operational overhead before it becomes a service desk.
For leaders thinking about whether to assemble these capabilities internally or rely on more packaged workflows, this breakdown of buy versus build is relevant because warehouse complexity and analytics tooling costs usually rise together.
What founders should actually optimize for
A young company should optimize for decision throughput per data hire.
Cheap infrastructure becomes expensive if it absorbs your best technical people.
Snowflake often wins the conversation even when it doesn't obviously win the invoice. Auto-suspend, fast scaling behavior, and a more automated operating model reduce warehouse babysitting. That can matter more than list price if your goal is broad access to data.
A quick explainer helps frame the difference in practical terms:
Redshift can still be the right choice. But if you pick it, do so intentionally. Make sure the economics of predictable workloads and AWS alignment outweigh the labor cost of more active management. Otherwise, you'll save on the platform and pay for it in slower execution.
How Your Analytics Layer Should Influence Your Choice
Warehouse decisions used to be made mostly by data engineers. That no longer works. The warehouse now sits underneath BI tools, notebook workflows, reverse ETL, internal product analytics, and AI-driven query interfaces. If your company wants genuine self-serve access, the analytics layer has to shape the warehouse decision.
Self-serve changes the warehouse requirement
Self-serve analytics creates a very different query pattern from classic centralized reporting. Instead of a small number of scheduled dashboards, you get lots of unpredictable activity. An analyst runs exploratory SQL. A product manager checks a retention question. Finance refreshes a dashboard. An AI workspace translates plain English into a sequence of warehouse queries. The system has to tolerate that mess.
Satori notes that while both platforms can separate storage and compute, Snowflake does so natively by default, which makes workload-isolated scaling better suited to mixed BI, ad hoc analytics, and AI-driven querying, while Redshift's elasticity depends more on RA3 nodes and a deliberate cluster resizing strategy, as described in Satori's comparison of Snowflake and Redshift.
That doesn't mean Redshift can't support self-serve. It can. But it does mean the path is often more sensitive to configuration and capacity planning.
Why the semantic layer and query layer matter
A self-serve stack lives or dies by trust and responsiveness. Users need definitions that stay consistent, and they need answers fast enough that they don't abandon the tool and go back to asking an analyst in Slack. That's why the warehouse should be evaluated together with the layer above it.
A strong semantic layer helps standardize business definitions, but it can't compensate for a warehouse that struggles under mixed demand. If the underlying platform creates resource contention, self-serve degrades into a frustrating partial rollout.
This is also where a warehouse-native tool such as Querio can fit. It connects directly to Snowflake or Redshift and lets users query live warehouse data through read-only access, including AI-assisted workflows that translate plain English into SQL and Python. For teams trying to reduce dependence on analysts, that kind of analytics layer increases the importance of concurrency and operational simplicity underneath it.
If non-technical users are going to query the warehouse directly through modern tools, warehouse elasticity becomes part of product design, not just infrastructure design.
That's why the snowflake vs redshift decision should reflect the kind of analytics culture you want. If your ambition is broad, frequent, self-serve usage, the warehouse must support that operating pattern without constant intervention.
Real-World Scenarios When to Choose Each Platform
The fastest way to make this decision is to stop thinking in abstract product terms and think in company patterns.
The AWS-native commerce company
This company runs most of its stack on AWS. Its analytics work is dominated by recurring sales, inventory, finance, and marketing reporting. Loads are meaningful but fairly predictable. The engineering team already understands AWS thoroughly, and leadership prefers stable infrastructure spend over elasticity they may not use every day.
Redshift is often the cleaner fit here.
The main reason isn't that Snowflake couldn't handle the work. It's that the company already gets value from AWS standardization, and the workload shape is steady enough that reserved-style economics and a more planned cluster model can be sensible. If the team is comfortable owning warehouse tuning and doesn't expect heavy self-serve concurrency right away, Redshift can be a practical choice.
The B2B SaaS startup with messy demand patterns
This team has investors asking for weekly metrics, product managers exploring behavior changes after each release, and customer success pulling account-level reports on demand. Nobody can predict when warehouse activity will spike. Some days are quiet. Other days half the company wants answers at once.
Snowflake usually fits better in this pattern.
The business benefit is less about marginal query speed and more about reduced friction. Independent compute behavior and easier workload isolation support ad hoc usage better. For a small data team trying to enable self-serve without spending its week tuning infrastructure, that matters a lot.
When the question volume is unpredictable, flexibility is usually worth more than theoretical infrastructure efficiency.
The fintech or data product team
This company isn't just analyzing data internally. It may also expose data to customers, support internal risk or operations workflows, or run multiple analytics experiences with different access patterns. It needs strong separation between workloads because internal reporting and customer-facing analytics can collide.
Snowflake often has the more natural operating model for that setup because isolated compute maps well to mixed usage patterns. But this is also a case where internal expertise matters. A strong AWS-heavy team with clear workload planning might still prefer Redshift, especially if the broader platform is already anchored there.
A useful decision filter here is simple:
Choose Snowflake when you expect many concurrent users, mixed analytical behavior, and a small team that can't afford much warehouse maintenance.
Choose Redshift when your company is firmly AWS-native, workloads are steady, and the team is prepared to manage warehouse performance more actively.
Pause and validate assumptions if you're buying based only on brand familiarity. The wrong fit usually shows up later as data team bottlenecks, not immediate technical failure.
The Final Decision A Checklist for Leaders
A good warehouse decision should survive contact with your actual operating model. Use this checklist the way you'd evaluate any foundational platform. Not by asking what's possible, but by asking what your team can sustain.
Choose Snowflake if most of these are true
Your workloads are bursty. Query demand comes in waves tied to reporting cycles, launches, or ad hoc analysis.
You want self-serve analytics to spread across teams. Product, finance, operations, and leadership will all hit the system in uneven ways.
Your data team is small. You need more automation and less warehouse tuning.
You care more about flexibility than fixed infrastructure planning. Idle compute spend is a bigger concern than reservation strategy.
You expect mixed workloads. BI, exploratory work, and newer AI-driven analytics patterns all need to coexist.
Choose Redshift if most of these are true
You're committed to AWS. The warehouse should align with existing platform choices and team expertise.
Your workloads are steady and predictable. That makes reserved pricing and cluster planning easier to justify.
Your team can manage more warehouse operations. Tuning and capacity decisions won't derail higher-value work.
You prioritize budget predictability. Finance would rather plan around steadier warehouse behavior.
Your analytics model is more centralized. A smaller number of technical users drive most query activity.
The best choice in snowflake vs redshift isn't the one with the most features. It's the one that gives your company the most usable analytics with the least operational drag.
If you're choosing between Snowflake and Redshift because your team is overloaded with requests, Querio is one way to turn either warehouse into a live self-serve analytics environment. It connects directly to your warehouse, lets users work from plain English, SQL, and Python, and helps data teams spend less time acting as a reporting queue.

