Sentiment Analysis on Reviews: A Production-Ready Guide
Build a production-ready pipeline for sentiment analysis on reviews. This guide covers data prep, model selection, and deployment with Querio's AI agents.
https://www.youtube.com/watch?v=NSeKCBTFC18
published
Outrank AI
sentiment analysis on reviews, customer feedback, data analysis, python notebooks, querio
9e9f4193-8476-4236-9cc3-1ba79b9432ae

Your team already has the raw material for better product decisions. It’s sitting in App Store reviews, support transcripts, G2 comments, post-purchase surveys, and marketplace feedback. The problem isn’t access. The problem is turning that mess into something a product manager, founder, or support lead can use without reading thousands of comments by hand.
That’s where sentiment analysis on reviews becomes useful. Not as a vanity dashboard. Not as a single happiness score. Useful means you can spot recurring complaints before they become churn, identify which feature launch changed perception, and give teams a way to ask questions about customer voice without opening another ticket for the data team.
The Business Case for Mastering Review Sentiment
A common difficulty arises. Reviews pile up faster than anyone can read them. Product managers skim a few dozen comments, support leaders escalate the loudest complaints, and founders rely on anecdotal snippets from calls. That process misses patterns.

Reviews matter because buyers use them as decision input. According to industry analysis, over 90% of consumers read online reviews before making a purchase, and nearly 70% say reviews directly influence their buying decisions, which makes review sentiment a direct business signal rather than just a support artifact (PromptCloud on product review sentiment).
That changes how I think about review analysis. If reviews influence revenue, then the ability to classify, group, and interpret them is part of go-to-market execution, not just analytics hygiene. Teams working on pricing, onboarding, retention, and brand all need the same underlying capability.
For growth leaders, this also connects with broader positioning and demand generation work. If you’re reworking messaging, launch sequencing, or audience segmentation, these SaaS marketing strategies are a useful complement because they help connect customer language to campaign decisions.
What sentiment analysis actually gives the business
A good pipeline does more than label reviews positive or negative. It helps teams answer practical questions:
Product teams can see which features trigger praise, confusion, or frustration.
Support leaders can spot issue clusters before they explode in public channels.
Retention teams can watch for negative language that often appears before measurable churn.
Executives can track whether perception is improving after launches, pricing changes, or service incidents.
Practical rule: If a review workflow doesn’t change a backlog, escalation path, or customer communication plan, it’s reporting, not analysis.
The strongest use case is operational. You want a repeatable system that turns unstructured text into a decision input. That’s the same mindset behind disciplined retention work. If your team is trying to tie customer feedback to account health, this guide on reducing customer churn fits naturally with sentiment monitoring because the earliest warning signs often show up in text before they show up in dashboards.
From Raw Data to Analysis-Ready Reviews
Most failures in sentiment analysis on reviews start before model selection. The model gets blamed, but the underlying issue is almost always the input. Reviews are noisy. They contain typos, emojis, sarcasm, copied templates, mixed languages, boilerplate signatures, and platform-specific junk.
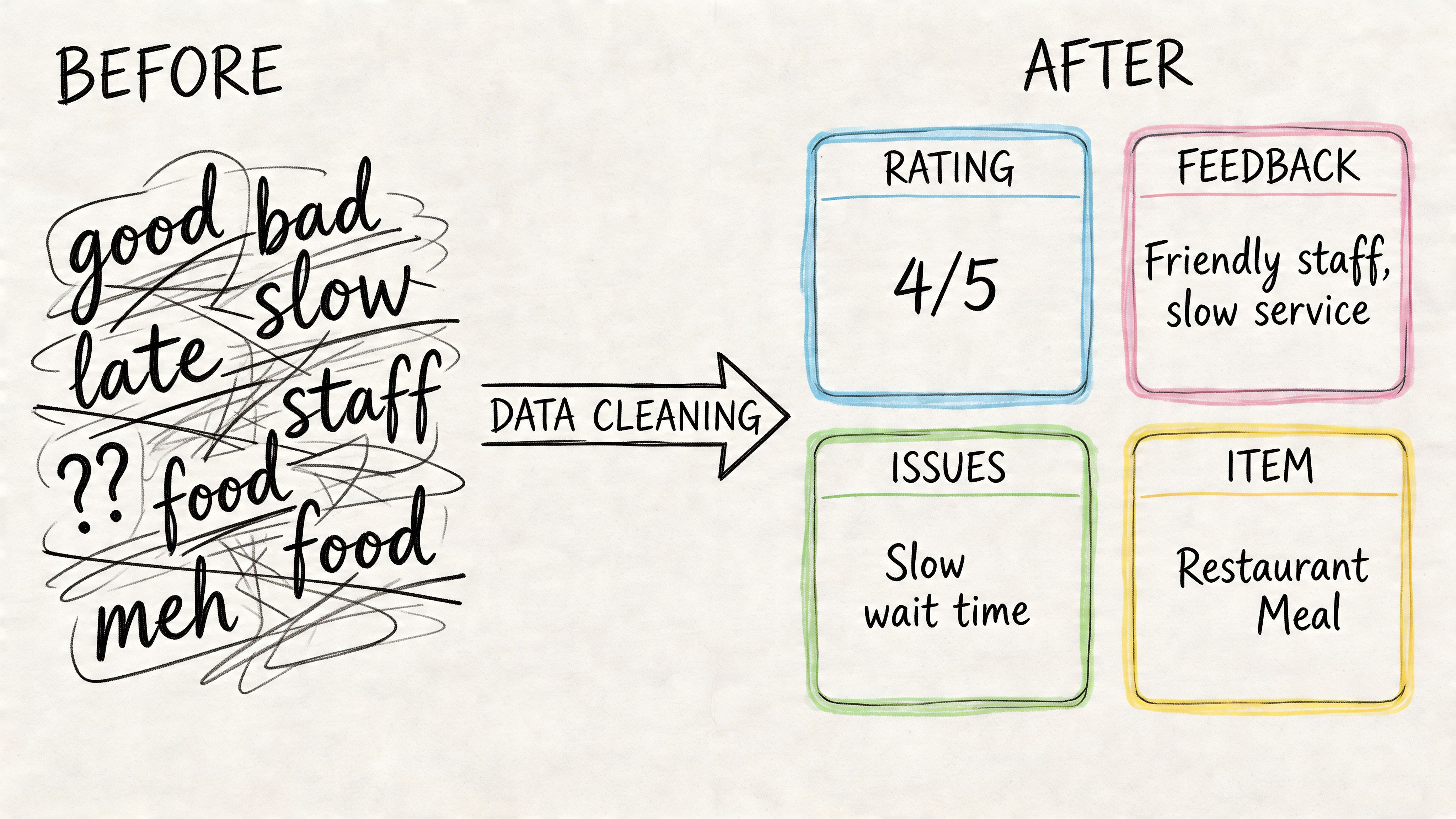
That gap between clean data and production data is where teams get surprised. Models can hit 85-90% accuracy on clean benchmarks, but real-world production accuracy often drops to 65-75% because of noise, sarcasm, and domain slang. Production mismatches can also cause up to 30% error spikes (Edge Delta on sentiment analysis accuracy).
Start with data contracts, not notebooks
Before writing preprocessing code, define what a review record should look like. At minimum, I want each row to include:
Review text with the raw original preserved
Source metadata such as App Store, G2, support ticket, or marketplace
Timestamp fields normalized to one standard
Entity context like product, plan tier, region, or account segment
Join keys for linking sentiment output to downstream BI tables
If this sounds basic, that’s because it is. It’s also where many teams cut corners. Once the warehouse has five different review schemas, no model choice will rescue the analysis.
A lot of this work is really data standardization. If your warehouse is still struggling with inconsistent field names and definitions, this write-up on standardization of data is worth reading before you invest more in NLP.
Clean for meaning, not for elegance
Preprocessing should improve signal retention. It shouldn’t scrub away useful context.
A practical pipeline usually includes:
Normalization
Lowercase text where appropriate, normalize whitespace, and remove obvious markup or formatting artifacts.Token-aware cleanup
Handle repeated punctuation, elongated words, emojis, and common abbreviations. “Loveeee it” and “💀 app crashed again” both carry sentiment.Negation handling
“Not good” cannot become “good” because a stop-word rule removed “not.”Deduplication
Detect near-duplicate reviews, copied vendor responses, or syndicated content from multiple channels.Language and channel tagging
Separate app reviews from support transcripts. They behave differently and often need different thresholds.
Clean text for the question you want to answer. If you want feature feedback, don’t preprocess away feature names, version strings, or product terms.
What works in practice
I prefer lightweight Python preprocessing close to the warehouse instead of exporting CSVs and building isolated scripts that no one maintains. That makes it easier to rerun logic, inspect edge cases, and version transformations alongside the rest of the analytics stack.
A few habits help:
Keep the raw text column untouched. Every cleaned field should be derived.
Store intermediate outputs. Tokenized text, normalized text, and language tags are useful for debugging.
Sample failures weekly. Review the false positives and false negatives. You’ll learn more from bad examples than aggregate metrics.
Segment before scoring. Reviews from enterprise admins and casual mobile users often use very different language.
The preprocessing mistakes that usually hurt most
Here’s what I see break pipelines most often:
Mistake | Why it hurts | Better approach |
|---|---|---|
Removing too much text | Deletes sentiment cues, product nouns, and negations | Strip noise selectively and preserve meaning-bearing tokens |
Mixing all sources into one corpus | App reviews, tickets, and surveys use different language | Build source-aware preprocessing and reporting |
Trusting benchmark-like samples | Production text is messier than demo datasets | Validate on recent warehouse data |
Treating sarcasm as a corner case | It shows up constantly in consumer reviews | Route uncertain or high-impact cases for review |
Choosing Your Sentiment Analysis Engine
Once the data is usable, the next decision is architectural. The right engine depends less on what’s fashionable and more on what your team can operate. A prototype that no one can explain or maintain becomes shelfware.
The temptation is to jump straight to transformers. Sometimes that’s right. Modern deep learning has enabled 91–95% accuracy for fine-tuned transformers in stable conditions, and these systems can reduce review coding time from weeks to hours (PubMed review of modern sentiment analysis). But “stable conditions” matters. Stable isn’t the same as messy multi-source production text.
Four engine types and their trade-offs
I group most options into four buckets.
Rule-based systems
These use explicit logic such as keyword lists, phrase rules, and polarity overrides. They’re easy to explain and fast to deploy. They also break quickly when users get creative with language.
They’re useful for:
narrow workflows
simple alerts
low-risk internal categorization
They’re weak for:
sarcasm
contextual sentiment
mixed or nuanced reviews
Lexicon-based methods
Tools like VADER sit between rules and learned models. They score text using dictionaries and weighting heuristics. For social-style text and lightweight review monitoring, they can provide a solid baseline.
Their strengths are speed and transparency. Their limitation is domain adaptation. Product reviews often include words that flip meaning by context, and lexicons don’t learn that on their own.
Traditional machine learning
This includes approaches like SVM or Naive Bayes trained on labeled examples with features such as TF-IDF or embeddings. These systems still matter because they’re often cheaper and easier to audit than heavier models.
They tend to work well when:
you have a labeled dataset in one domain
the sentiment categories are clear
inference cost matters
They struggle when:
language changes fast
you need phrase-level nuance
stakeholders ask why a model made a call
Transformer-based models
BERT-style and related models handle context far better than older approaches. If reviews are central to product, marketplace trust, or support triage, this is usually where teams end up.
The trade-off is operational. You need stronger evaluation, better monitoring, and clear escalation paths for low-confidence outputs. If your team needs a grounding overview, this explainer on what natural language processing is is useful for aligning technical and non-technical stakeholders around the basics.
Sentiment Analysis Model Comparison
Approach | How It Works | Pros | Cons | Best For |
|---|---|---|---|---|
Rule-based | Applies predefined rules and keyword logic | Fast setup, easy to explain, low cost | Brittle, weak on nuance | Alerting on obvious positive or negative phrases |
Lexicon-based | Scores words and phrases from sentiment dictionaries | Lightweight, transparent, good baseline | Limited domain awareness | Early-stage review monitoring |
Traditional machine learning | Learns patterns from labeled examples | Better adaptation than fixed rules, manageable cost | Needs labeled data, weaker contextual understanding | General review classification in a stable domain |
Transformer-based | Uses deep contextual language models | Strongest nuance handling, good for complex text | Higher complexity, more monitoring, more compute | High-volume and high-stakes sentiment analysis on reviews |
Don’t pick a model because it wins a benchmark. Pick one your team can evaluate, retrain, and explain when leadership asks why sentiment moved.
What usually works best
A layered approach works better than trying to force one model to do everything.
For example:
use rules for obvious escalation terms
use a learned model for broad sentiment classification
use phrase attribution or aspect extraction for product insight
send uncertain or high-impact examples to human review
That hybrid structure is often more durable than a single “smart” model. It also fits how real organizations work. Support wants fast routing. Product wants nuance. Leadership wants trends. Compliance wants traceability.
Extracting Actionable Product Insights
A sentiment score by itself rarely changes a roadmap. Teams need to know what people are reacting to. That’s where many sentiment analysis on reviews projects stall. They produce polarity, but not explanation.
Most sentiment tools collapse multi-faceted reviews into a single score. That misses the actual business signal. A review like “happy with the build but not impressed with the color” contains conflicting views about different aspects, and a single score obscures which feature needs attention (AWS explanation of sentiment analysis and mixed review examples).
Use aspect-based analysis for product questions
The shift that matters is moving from document-level sentiment to aspect-based sentiment analysis. Instead of asking whether a review is positive, ask what entity or feature the sentiment attaches to.
That lets teams answer questions like:
Which onboarding step drives the most negative language?
Did sentiment around billing improve after the pricing page update?
Which feature gets positive sentiment from power users but negative sentiment from new customers?
A useful output table usually looks something like this:
review_id | aspect | sentiment | confidence | source | date |
|---|---|---|---|---|---|
123 | onboarding | negative | high | app_store | recent |
123 | performance | positive | medium | app_store | recent |
124 | billing | negative | medium | support_ticket | recent |
That structure is much easier to operationalize than one score per review.
Turn raw output into decisions
When I present review intelligence to product teams, I don’t lead with model metrics. I lead with grouped findings:
Top negative drivers by product area
Top positive drivers worth reinforcing in messaging
Sentiment change over time after launches or incidents
Segment differences across customer type, region, or plan
This is also where operational response matters. Once you know which themes are hurting perception, customer-facing teams need a process to address them. For teams handling public feedback directly, this guide on how to respond to negative reviews is a practical complement to the analytics side.
A dashboard becomes useful when a PM can say, “Checkout complaints rose after the last release, and most negative phrases mention coupon logic,” then assign work the same day.
One good way to explain aspect-level sentiment to stakeholders is to show a live example of mixed feedback and how it gets separated into product themes:
What does not work
Three patterns usually disappoint:
Single-score executive dashboards
They look clean, but they flatten nuance and trigger arguments about methodology instead of product action.Topic models without business mapping
Generic clusters are interesting, but leaders need themes tied to actual product surfaces, workflows, or service components.No tie-back to releases or segments
Sentiment without business context becomes commentary. Sentiment tied to launches, cohorts, and customer type becomes decision support.
Building a Self-Serve Sentiment Pipeline with Querio
A one-time notebook analysis is fine for exploration. It doesn’t solve the operating problem. The ultimate goal is a pipeline that updates on schedule, stores outputs in the warehouse, and lets non-technical teams query the results safely.
The backbone is straightforward. Pull fresh reviews from your warehouse, preprocess them, run sentiment and aspect extraction, write structured outputs back to modeled tables, and expose those tables to downstream dashboards or chat-based interfaces. The hard part isn’t the sequence. It’s making the sequence reliable enough that the data team doesn’t become a permanent support queue.
A practical production pattern
I’d build the pipeline in five layers:
Ingestion layer
Land raw review text from app stores, marketplaces, support systems, and survey tools into source tables.Preparation layer
Normalize text, preserve raw columns, assign metadata, and filter obvious junk.Scoring layer
Run sentiment classification, aspect extraction, and confidence tagging.Quality layer
Flag suspicious patterns, uncertain outputs, and samples for human review.Access layer
Publish curated tables for BI, product reporting, and self-serve analysis.
The quality layer gets skipped too often. That’s a mistake, especially with fake reviews. Opinion spam has been described as fake or bogus reviews intended to mislead readers or automated systems, and heavy spam can “make sentiment analysis useless for applications” (research on opinion spam and sentiment analysis). If you don’t account for that, your sentiment dashboard can become a measurement of manipulation rather than customer voice.
What to automate and what to keep human
Not every step should be fully automated.
Keep these automated:
extraction from source systems
standard preprocessing
batch inference
warehouse writes
scheduled refreshes
Keep these human-supervised:
review of suspicious clusters
taxonomy updates for product aspects
evaluation of low-confidence outputs
spot checks after releases, rebrands, or pricing changes
“Production sentiment systems fail quietly.” They don’t always crash. They just drift until teams stop trusting the output.
For the self-serve access layer, Querio’s warehouse chat and notebook workflow fits this model because it lets teams run Python directly against warehouse data and expose results through a conversational interface. That matters when a product manager wants to ask a plain-English question about review trends without waiting on an analyst to write another query.
The bottleneck to remove
The biggest shift is organizational, not technical. Data teams shouldn’t spend their week answering variants of the same review question. They should maintain the tables, logic, and monitoring that make those answers self-serve.
That means your final deliverable is not a model. It’s an internal product:
a trusted sentiment table
a documented aspect taxonomy
a refresh schedule
clear ownership for retraining and QA
a simple way for business users to ask questions
FAQ on Production Sentiment Analysis
How much labeled data do you need
Enough to represent the language your customers use. For a narrow use case, a modest labeled set can be enough to establish a baseline. For a broader production system, coverage matters more than sheer volume. Include edge cases, mixed sentiment, slang, and channel-specific language.
Should you analyze reviews from every source together
Usually no. App reviews, support tickets, and marketplace comments behave differently. Keep a shared core pipeline, but segment the reporting and often the modeling logic too. A complaint in a support ticket carries a different meaning than the same phrase in a public review.
How do you handle mixed sentiment in one review
Use aspect-level extraction instead of assigning one label to the whole document. Mixed reviews are common, especially in product feedback. If your model only supports a single label, you’ll miss the specific feature driving the reaction.
Do you need a transformer model on day one
Not always. Start with a baseline you can explain and validate. If the business use case is lightweight triage, a simpler model may be enough. Move to a more advanced model when nuance, scale, or risk justifies the added operational load.
How often should you review model performance
Regularly, and especially after product launches, pricing changes, major incidents, or expansion into new segments. Language drift is operational reality. A model that looked solid a few months ago may misread today’s reviews if the product and audience changed.
What should you show executives
Don’t show raw model internals first. Show trend direction, top drivers by aspect, representative examples, and changes tied to releases or customer segments. Keep the output business-facing and make the methodology available when needed.
How do you build trust in the system
Trust comes from transparency and repeatability. Preserve raw text, retain confidence signals, sample outputs for manual review, and publish clear rules for how sentiment gets generated. Teams trust systems they can audit.
If your data team is stuck acting like a human API, Querio is worth evaluating as infrastructure for self-serve analytics. It gives teams a way to run Python and natural language workflows directly on warehouse data, which is useful when review sentiment needs to move from one-off analysis into an operational pipeline that product, support, and leadership can effectively use.

