Data: data warehouse vs data lake — which is right for you?
Compare data warehouse vs data lake: architecture, costs, and use cases to pick the right data strategy.
published
Outrank AI
data warehouse vs data lake, data architecture, data strategy, startup tech stack, business intelligence
3ae4098a-8678-4132-9d65-a82114892f26

The fundamental difference between a data warehouse and a data lake boils down to structure and intent. Think of a data warehouse as a highly curated library of polished reports, perfect for getting reliable answers to specific business questions. A data lake, on the other hand, is like a massive, raw archive, holding everything in its original format, making it ideal for deep exploration and future-facing data science projects.
Data Warehouse vs. Data Lake: The Core Difference
Choosing between these two approaches isn't just a technical decision; it’s a strategic one that dictates how you'll derive value from your data. One path gives you a meticulously organized system for known queries, while the other offers a vast, unedited pool of information for open-ended discovery. Getting this right from the start is critical for building a data strategy that truly supports your company's ambitions.

Data Warehouse vs. Data Lake at a Glance
To quickly grasp the key distinctions, this table provides a high-level snapshot. It’s a great starting point for understanding their fundamental differences before we get into the finer architectural details and real-world trade-offs.
Characteristic | Data Warehouse | Data Lake |
|---|---|---|
Data Structure | Highly structured and processed | Raw, unstructured, and semi-structured |
Primary Users | Business analysts, executives | Data scientists, data engineers |
Key Use Case | Business Intelligence (BI) and reporting | Machine learning and exploratory analysis |
Data Processing | Schema-on-write (structure defined before loading) | Schema-on-read (structure applied when queried) |
Query Speed | Very fast for reporting and dashboards | Slower, designed for large-scale batch processing |
Storage Cost | Higher, due to processing and structured formats | Lower, using inexpensive object storage |
This table lays out the facts, but the strategic implications are where things get interesting.
The Strategic Trade-Off
The primary function of a data warehouse is to deliver speed and reliability for answering known business questions. The data is cleaned, transformed, and organized into a predefined structure before it's ever loaded—a process called "schema-on-write." This upfront investment pays off every time an executive needs last quarter's sales figures, because the answer is fast, consistent, and trustworthy. It's the foundation for your most critical KPI dashboards.
In contrast, data lakes are built for flexibility and the exploration of unknown future questions. By storing data in its native, raw format, you embrace a "schema-on-read" approach. This gives data scientists the complete, unfiltered picture they need to train machine learning models, find hidden user behavior patterns, or answer questions you haven't even thought of yet.
The core decision isn't just technical; it's about business philosophy. Do you need to perfect the answers to questions you already have, or do you need the raw material to discover questions you haven't yet thought to ask?
For most companies, especially startups, this isn't a one-and-done choice. Your data needs will evolve. An early-stage product might thrive with a simple warehouse for core analytics, but as it scales, adding a data lake to predict churn or personalize user experiences becomes the next logical step. The key is to match the architecture to your immediate strategic goals.
Comparing Data Architecture and Structure
When you get right down to it, the fundamental divide between a data warehouse and a data lake comes from their architecture. This isn't just a technical detail; it shapes everything from how you bring data in to how your teams can actually use it. One approach is built for structure and speed, the other for raw, untamed flexibility.

Getting a handle on these structural models is crucial for making the right choice. Your decision will ripple out, affecting engineering workloads, how fast queries run, and ultimately, the kinds of questions your business can even ask of its data.
The Warehouse Model: Schema-on-Write
A data warehouse runs on a schema-on-write philosophy. I like to think of it as building from a very detailed blueprint. Before any data gets in, it has to be cleaned, processed, and forced to fit a predefined structure.
This disciplined approach uses a process called ETL (Extract, Transform, Load), which works like this:
Extract: Data gets pulled from all your different operational systems—think CRMs, e-commerce platforms, or accounting software.
Transform: This is the heavy lifting. The raw data is scrubbed, standardized, and reshaped until it perfectly matches the warehouse's strict schema.
Load: Only then is the pristine, structured data loaded into the warehouse, perfectly primed for high-speed analysis.
The payoff here is predictable performance and reliability. When an analyst needs a report, the data is already optimized for fast, consistent answers. It’s why warehouses have long been the gold standard for business intelligence (BI) and critical dashboards. You can learn more about how this fits into the bigger picture in our detailed guide on the modern analytics stack.
The Lake Model: Schema-on-Read
Data lakes flip the script entirely with a schema-on-read architecture. You just dump everything in its original, raw format. It doesn't matter if it's structured tables, semi-structured JSON files, unstructured text logs, images, or a firehose of IoT sensor data—it all goes into the lake.
The structure isn't applied until someone actually needs to read the data for a specific analysis. This model, known as ELT (Extract, Load, Transform), is a game-changer for flexibility. Data scientists get access to the complete, unfiltered dataset, which is exactly what they need for deep exploratory work and training machine learning models.
The core architectural trade-off is simple: A data warehouse offers rigid reliability at the cost of upfront structuring. A data lake provides maximum flexibility but shifts the burden of data validation and interpretation to the point of analysis.
But that flexibility comes with a huge catch. Without rock-solid governance and metadata management, a data lake can quickly turn into a "data swamp." It becomes a messy, disorganized mess where no one can find what they need or trust the data they do find. As you weigh your options, it's also worth thinking about how the underlying principles of cloud storage vs local storage influence your overall strategy. To avoid creating a data swamp, you have to plan carefully to keep your lake a valuable asset, not a costly liability.
How Performance and Cost Models Impact Your Startup
When you're building a startup, every decision comes down to two things: how fast can you move, and how much will it cost? Your data architecture is no exception. The choice between a data warehouse and a data lake isn't just technical—it's a fundamental business decision that hits your budget and your team's ability to act on information.
A data warehouse is built for speed. Its neatly structured data and powerful query engine are designed to give you answers now. This is the engine behind your operational dashboards, the kind your CEO checks for real-time sales numbers or your product team uses to watch user activation funnels. You get sub-second responses because the system is optimized for known, recurring questions.
A data lake, on the other hand, is all about processing power and scale. It’s not about instant gratification; it’s about deep, exhaustive analysis. Imagine a data scientist trying to build a churn prediction model. They don't need a response in milliseconds. They need to sift through terabytes of raw event logs efficiently, a job that a data lake handles with ease.
Breaking Down the Cost Structures
The money side of this is where things get really interesting, because the two models couldn't be more different. Traditionally, data warehouses meant big upfront costs for hardware and software licenses. While the cloud has made them more accessible, the price is still largely tied to high-performance compute and structured storage.
Data lakes flipped this model on its head by embracing cheap object storage like Amazon S3 or Google Cloud Storage. This approach makes it astonishingly cheap to dump massive amounts of unfiltered data—years of clickstream logs, IoT sensor readings, you name it. You're paying pennies per gigabyte, allowing you to build a vast reservoir of data without breaking the bank.
This incredible cost-efficiency is why the data lake market has exploded, growing from $7.9 billion in 2019 to a projected $20.1 billion by 2024. As you think about your own strategy, you can find more on these market trends and their implications.
For a startup, the choice is often pragmatic: Pay for the premium performance of a data warehouse to run the core business, or pay for the cheap, scalable storage of a data lake to fuel future innovation.
Calculating Your Total Cost of Ownership
Modern cloud pricing adds another layer of complexity. Both systems often use a pay-as-you-go model, but what you pay for is completely different.
Data Warehouse Costs: You’re usually paying for the compute cluster (the "warehouse size") by the hour, plus the cost to store your processed, refined data. Queries are lightning-fast, but that meter is always running on your compute resources.
Data Lake Costs: Storage is the cheap part. The real cost comes from compute, which you pay for on a per-query or per-job basis. A single, complex analysis from a data scientist could rack up a surprising bill. Cost control here is all about managing who runs queries and how complex they are.
Your total cost of ownership (TCO) isn't just about the storage bill. It's a direct result of who is using the data and why. A data warehouse gives you predictable costs for predictable workloads, which is great for budgeting. A data lake offers a low barrier to entry for storage but can create volatile costs if you aren’t carefully managing query patterns. The goal is to match the cost model to what your business needs most.
Matching Use Cases to Your Business Teams
Choosing between a data warehouse and a data lake isn't just a technical decision—it's about people. The right data architecture should feel intuitive for your teams, fitting into their daily workflows and giving them the data they need, how they need it. Different roles have fundamentally different relationships with data, and your infrastructure has to reflect that.
For many organizations, the data warehouse acts as the central hub for operations and leadership. It’s what powers the predictable, high-stakes reporting that keeps the lights on.
The Domain of the Data Warehouse
Think about your business analysts, finance department, and sales operations leads. Their work demands consistency, accuracy, and speed. They lean on a data warehouse because the information is already cleaned, structured, and ready for their specific questions.
Here are a few classic warehouse-driven tasks:
Executive KPI Dashboards: Giving leadership a trusted, real-time pulse on core metrics like Monthly Recurring Revenue (MRR), Customer Acquisition Cost (CAC), and churn.
Sales Funnel Tracking: Letting the sales team monitor lead conversion rates, pipeline velocity, and quota attainment against historical data.
Financial Reporting: Helping the finance team close the books, perform variance analysis, and produce auditable data for regulatory compliance.
A data warehouse delivers a single source of truth for the metrics that run your business. It's built for reliability and serves teams who need fast, consistent answers to known questions.
The Playground of the Data Lake
But what about the teams that need to explore the unknown? That's where the data lake comes in. It’s the preferred environment for data scientists and engineers—people who thrive on having access to massive volumes of raw, unfiltered information. This is where they hunt for new patterns and build predictive models that simply wouldn't be possible with pre-processed data.
This need for flexibility is driving massive growth. The combined market for data lake and warehousing is set to explode from $16 billion in 2024 to an estimated $50 billion by 2030, with cloud-based systems accounting for a 75% share.
You’ll typically find data lakes powering use cases like:
Predictive Modeling: Training a machine learning model to forecast customer churn by digging into raw user activity logs, support tickets, and even social media sentiment.
Product Discovery: Sifting through granular clickstream data and session recordings to truly understand user behavior and spot opportunities for new features.
Real-Time Processing: Ingesting and analyzing high-velocity data from IoT sensors or application event streams to flag anomalies or drive personalization.
The end goal is to give each team the right tools for their job. A warehouse provides the stability required for day-to-day reporting, while a lake offers the raw material for discovery and innovation. Understanding these distinct workflows is the first step toward building a data stack that actually works for everyone. For more ideas on putting this into practice, see our guide on self-service analytics use cases across different industries.
7. Beyond the Binary: The Rise of the Lakehouse and Hybrid Models
For years, the big question in data architecture was "data warehouse or data lake?" It felt like a forced choice between structured, reliable reporting and flexible, raw data exploration. But that’s starting to feel like an outdated conversation. The most forward-thinking data strategies now focus on combining the strengths of both.
This has paved the way for hybrid architectures, with the Data Lakehouse leading the charge. The concept is simple but powerful: merge the warehouse and the lake into a single, unified system. It aims to resolve the central conflict by layering warehouse-like features directly onto the low-cost, flexible storage of a data lake. The goal is to build one platform that serves both BI and data science, finally breaking down data silos and simplifying the entire stack.
How the Data Lakehouse Became a Reality
The lakehouse isn't just a clever marketing term; it's a genuine technical shift powered by new open-source table formats. Technologies like Delta Lake (from Databricks), Apache Iceberg (created at Netflix), and Apache Hudi (from Uber) are the real engines behind this evolution. They work as a transactional metadata layer over the raw files sitting in your data lake.
So, what does that actually mean? It means they bring features that were once exclusive to data warehouses into the lake environment.
ACID Transactions: This is a huge one. It guarantees data integrity, just like in a traditional database, preventing corruption when multiple people or processes are writing data at the same time. This reliability was historically a key reason to choose a warehouse.
Schema Enforcement and Evolution: You can define a structure for your data and, more importantly, enforce it. This is the antidote to the dreaded "data swamp." It also gives you the flexibility to update that schema over time as your business needs change, without breaking everything.
Time Travel: This feature lets you query historical versions of your data. It provides a complete, auditable trail of every change, which is invaluable for debugging, compliance, and analyzing trends.
This flowchart helps visualize how different team roles and their primary needs naturally align with the core strengths of each traditional architecture.
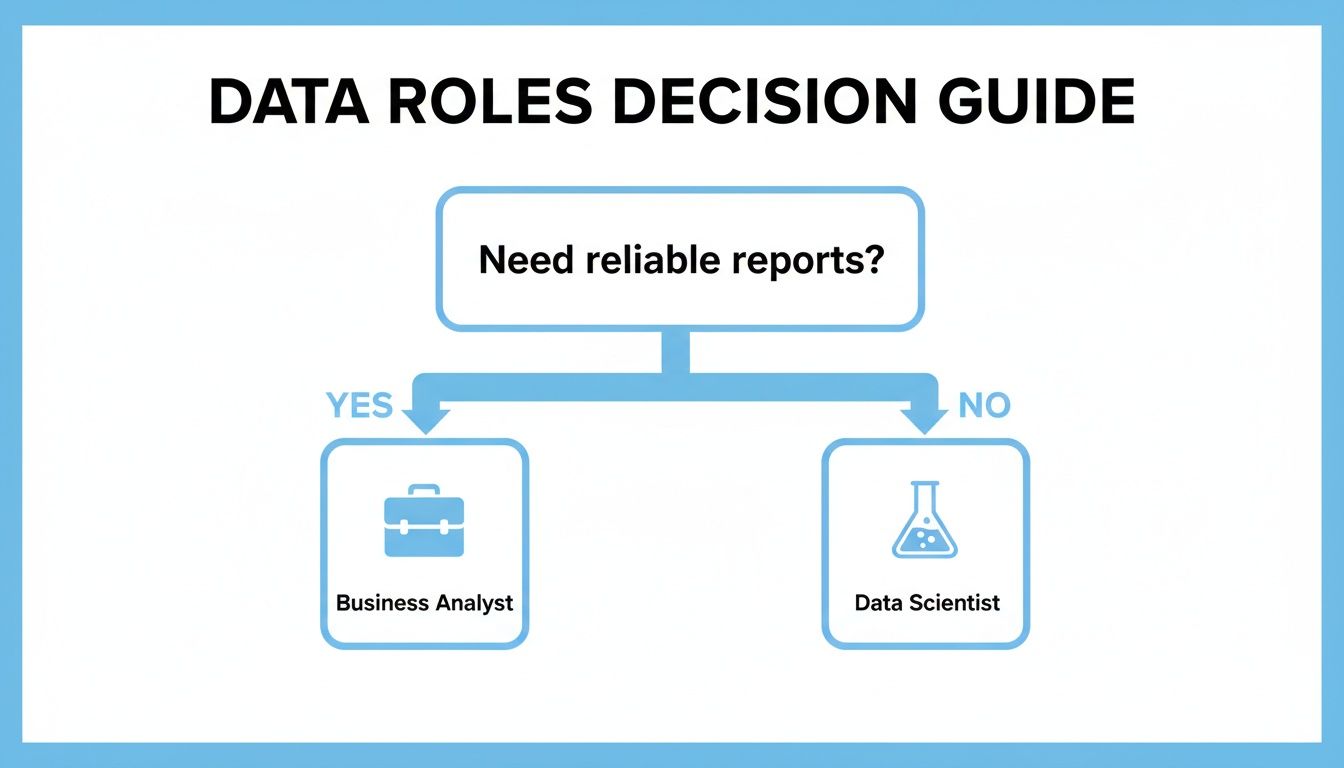
As the diagram shows, roles focused on reliable, structured reporting have historically gravitated toward warehouses, while those doing deep, exploratory analysis leaned on data lakes. The lakehouse attempts to serve both equally well.
A data lakehouse effectively promises a single source of truth for all data, from perfectly structured tables to raw, unstructured files. The goal is to deliver the high performance of a warehouse with the low-cost scalability of a lake, creating one system for every analytics and AI workload.
A Unified Future for Your Data Stack
For startups and any company experiencing growth, the lakehouse model is an incredibly attractive option. Instead of architecting, building, and maintaining two separate systems—one for BI and another for machine learning—you can build a single, cohesive platform from day one. This doesn't just cut down on engineering overhead; it drastically speeds up the time it takes to get from data to decision.
When your data team isn't constantly building pipelines to move and duplicate data between a lake and a warehouse, they can move much faster. Business analysts get quicker access to more reliable data, and data scientists can work with the freshest, most complete datasets available. This unified model is quickly becoming the default for organizations wanting to build a data stack that won't feel obsolete in a few years.
As you map out your own architecture, it's also worth checking out our guide on the new breed of warehouse-native data analysis tools designed to operate directly on top of these modern systems.
Unlocking Your Data With an Intelligence Layer
Choosing between a data warehouse and a data lake is just the first step. The architecture itself is only the foundation; the real goal is to turn all that stored data into faster, smarter business decisions. This is where a modern intelligence layer like Querio comes in, acting as the crucial bridge between your data infrastructure and the people who need answers.
This layer sits on top of your existing warehouse, data lake, or lakehouse, essentially serving as a universal translator. It puts data directly into the hands of everyone on your team—not just engineers—allowing them to explore, ask questions, and visualize information securely and intuitively.
Making Your Data Warehouse Accessible
For teams running a data warehouse, an intelligence layer breaks a common bottleneck. Your warehouse is full of clean, reliable, and structured data, but it's often locked away, accessible only to those who can write SQL. This creates a frustrating queue where business teams have to wait for analysts to run even basic reports.
Querio closes this gap by letting business users ask complex questions in plain English. For example, a product manager could ask, "What was the week-over-week user retention for our new onboarding flow in Germany?" and get an instant, accurate answer and a chart, all without writing a single line of code.
Taming the Data Lake for Business Use
Data lakes hold enormous potential, but their raw, semi-structured nature can make them a minefield for non-technical users. An intelligence layer connects to the powerful query engines running on your lake, making its vast collection of datasets truly useful for everyone.
With a tool like Querio, your finance and operations teams can safely ask questions of the same underlying data your data scientists use. They can pull their own insights from massive, complex datasets, turning the lake from a pure engineering asset into a company-wide resource for strategic analysis.
The real value of your data stack isn't its architecture—it's how easily your teams can get answers from it. An intelligence layer makes that possible, ensuring your investment in data infrastructure actually pays off through widespread, self-serve analytics.
Querio's embedded analytics and AI agent help your teams find insights securely. Governance and ease-of-use go hand-in-hand, as permissions are automatically enforced while natural language removes the technical hurdles. You can learn more about the technology behind this by exploring how semantic layers provide key benefits for any data architecture. This approach ensures that whether you have a warehouse, a lake, or a hybrid model, every team can turn their curiosity into decisions that move the business forward.
Your Top Data Strategy Questions, Answered
When you're building a data foundation, the theoretical differences between a data warehouse and a data lake are one thing. The practical, real-world questions you face as a founder or data leader are another entirely. Let's get straight to the trade-offs you'll actually be wrestling with.
Should a Small Startup Really Start With a Data Lake?
For the vast majority of early-stage startups, the answer is a firm no. Your immediate focus is on survival and growth, which means you need clear, trustworthy reports on core metrics—user sign-ups, revenue, feature adoption. A data warehouse is designed from the ground up for exactly this kind of fast, consistent operational reporting.
Jumping straight to a data lake can be a classic case of premature optimization. It often introduces a ton of complexity that a lean startup simply doesn't have the resources for. Without a dedicated data engineering team, you'll spend more time trying to manage and govern raw data than you will getting actual insights from it. Your time is better spent on a straightforward warehouse that delivers business value on day one.
What Exactly Is a "Data Swamp," and How Do I Avoid Creating One?
A "data swamp" is what happens when a data lake goes wrong. It’s a repository that's become so disorganized, undocumented, and filled with junk data that it’s impossible to use for any meaningful analysis. Instead of an asset, it turns into a black hole—a costly storage bill for data that nobody trusts or understands.
A data swamp is the inevitable outcome of a "store everything" approach that isn't balanced by an equal investment in data governance. It’s born the moment data gets dumped without clear ownership, metadata, or quality checks.
The only way to prevent a data swamp is to establish strong governance from the start. This doesn't have to be complicated, but it must be intentional.
Create a Data Catalog: You need a system to track what data you have, where it came from, and who's responsible for it. It's the map to your data treasure.
Enforce Schema (Where it Matters): Even though a lake is flexible, you can and should apply structure. Tools that enforce data quality at the point of ingestion or during analysis are critical.
Set Clear Access Controls: Define who can read and write data. This simple step prevents the uncontrolled, undocumented data dumps that are the primary cause of swamps.
How Do We Evolve From a Warehouse to a Lakehouse?
Moving from a traditional warehouse to a modern lakehouse isn't a big-bang, "rip and replace" project. It’s an evolution. The entire point is to bring your analytics and machine learning workloads together on one platform, not to create a massive migration headache.
The journey usually starts by setting up a data lake alongside your current warehouse. You can begin by offloading raw, unstructured data—think event logs, user activity streams, or third-party API dumps—into low-cost object storage like Amazon S3 or Google Cloud Storage.
Next, you introduce a metadata and transaction layer over that raw data using a technology like Apache Iceberg or Databricks Delta Lake. This is the magic step—it adds warehouse-like features such as ACID transactions and schema management directly onto your lake files. From there, you can gradually shift analytics workloads from the old warehouse to your new lakehouse, eventually creating a unified system for both BI and data science without having to duplicate all your data.
Ready to make your data accessible to everyone, no matter your architecture? With Querio, your teams can ask questions in plain English and get instant answers from your data warehouse, data lake, or lakehouse. Unlock self-serve analytics today.

