Row Level Security: A Guide for Self-Serve Analytics
Row level security - Learn how to implement row level security (RLS) to scale self-serve analytics. A practical guide for data teams on architectures,
https://www.youtube.com/watch?v=PdEutzhsrws
published
Outrank AI
row level security, data governance, self-serve analytics, data warehouse, querio
d049489b-9074-4709-a116-6184349a88ef

Most startups don’t set out to make the data team a ticket queue. It happens gradually. A product manager needs retention by segment. Sales wants pipeline by region. Finance asks for a margin view with sensitive rows removed. The first few requests are manageable. Then every dashboard, notebook, and ad hoc SQL query depends on someone from the data team translating business questions into safe queries.
That’s when the data team becomes a human API. People wait for answers they should be able to get themselves. Analysts spend their time rebuilding the same filtered views for different audiences. Leaders talk about self-service, but they still don’t trust broad access to the warehouse because one wrong query can expose the wrong customer, territory, or business unit.
Row level security is the architectural control that breaks that loop. When you enforce access rules inside the database or warehouse, every downstream tool inherits the same boundaries. BI dashboards, SQL editors, notebooks, and natural language query layers all see only the rows each user is allowed to see. The security model moves to the source, where it belongs.
That changes the role of the data team. Instead of hand-delivering filtered datasets, they define policies once and let teams explore safely. It also makes data democratization more realistic than most data democratization strategies suggest, because access control is enforced before results ever reach the user.
For growing companies, this isn’t only about convenience. It’s also operational discipline. For mid-market firms scaling self-service analytics, RLS simplifies compliance with regulations like GDPR and can cut audit preparation time by 30% according to Snowflake’s row-level security overview.
Table of Contents
Introduction Beyond the Data Bottleneck
In a fast-growing startup, the biggest analytics problem usually isn’t lack of tools. It’s trust. Leaders want broad access to data, but they don’t want broad exposure to customer records, compensation lines, regional performance, or partner-level details. So they centralize access through analysts and engineers.
That works until the business starts moving faster than the request queue. Product leaders need daily reads on feature adoption. Growth teams want campaign performance sliced by market. Operations wants account health by territory. The warehouse has the data, but access is constrained because nobody wants the wrong rows leaking into a dashboard or notebook.
The usual workaround is brittle. Teams create separate views for each audience, hard-code filters into BI models, and rely on naming conventions to keep sensitive tables out of reach. That architecture gets messy quickly. One dashboard points to a secure view, another points to the base table, and a well-meaning analyst accidentally joins the wrong object.
Practical rule: If access control lives mainly in dashboards and ad hoc views, it will drift.
Row level security gives you a cleaner foundation. The table stays shared. The policy decides which rows each user can access. A sales manager in Europe and a finance lead in the US can query the same underlying dataset, but each sees a different result set based on identity or attributes. The application doesn’t need custom filtering logic for every endpoint, and the BI team doesn’t need to clone the same semantic model for every audience.
That matters even more in self-service environments. Once notebooks, SQL workbenches, and AI query tools enter the stack, users can ask much broader questions than a prebuilt dashboard allows. Without database-level controls, self-service turns into a security review problem. With RLS, self-service becomes governable.
The shift is subtle but important. You stop asking, “Which dashboard should this person open?” and start asking, “What rows should this person ever be allowed to see?” That’s the right architectural question.
What Is Row Level Security and Why It Matters
Row level security means the database filters records based on who is asking. Users can access the same table, but they don’t all get the same rows back. The policy runs inside the database engine, not in the application after the fact.
A simple way to think about it
The office-building analogy works because it maps directly to how RLS behaves. The building is your dataset. Every employee enters the same building, but their badge only opens specific floors or rooms. They aren’t shown a fake building. They’re using the same one, with access constrained by policy.
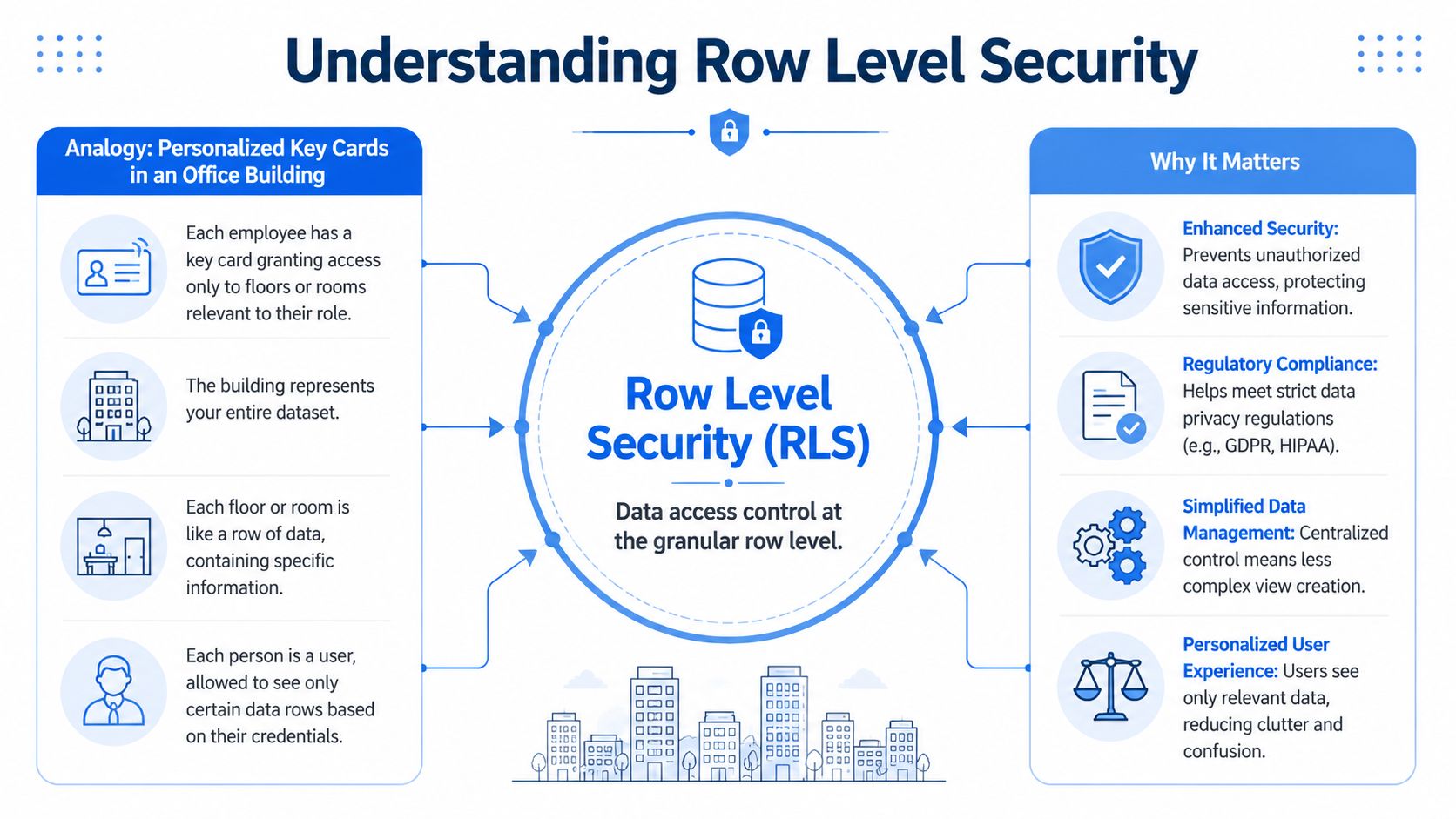
In data terms, a sales table might contain every region. A user in the EU role queries sales, and the warehouse returns only rows for the EU region. A support manager queries tickets, and the warehouse returns only the accounts assigned to that manager’s team. Nobody needs a separate copy of the table.
The key technical distinction is where this filtering happens. The database transforms user queries into filtered queries with WHERE conditions automatically appended. In PostgreSQL, enabling RLS creates a security predicate that the query planner injects before execution, which is why database-enforced filtering is more secure than application-layer filtering, as described in Yugabyte’s explanation of row-level security mechanics.
The safest filter is the one users never get a chance to bypass.
What row level security is not
RLS is often confused with simpler permission models.
Access model | What it controls | Where it falls short |
|---|---|---|
Table-level security | Whether a user can access a table at all | Too coarse for shared datasets |
Column-level security | Which fields are visible | Hides fields, not records |
Application-layer filtering | What the app chooses to show | Easy to miss in one query path |
Row level security | Which records a user can read | More complex, but much safer for shared access |
If you run a multi-tenant SaaS product, table-level permissions are rarely enough. Giving every tenant a separate table doesn’t scale operationally. If you run internal analytics, column-level security also won’t solve the problem. Hiding salary fields doesn’t stop someone from seeing the wrong department’s headcount rows.
What makes RLS strategically important is consistency. The policy applies regardless of whether the query comes from Power BI, a notebook, a SQL IDE, or an AI-generated query layer. That consistency is the difference between “we think access is limited” and “the database enforces access every time.”
Common RLS Architectures and Patterns
Most production implementations land in one of two camps. You either map users to predefined roles, or you evaluate attributes at query time. Both can work. The wrong choice is usually the one made too early, with no plan for how access rules will evolve.
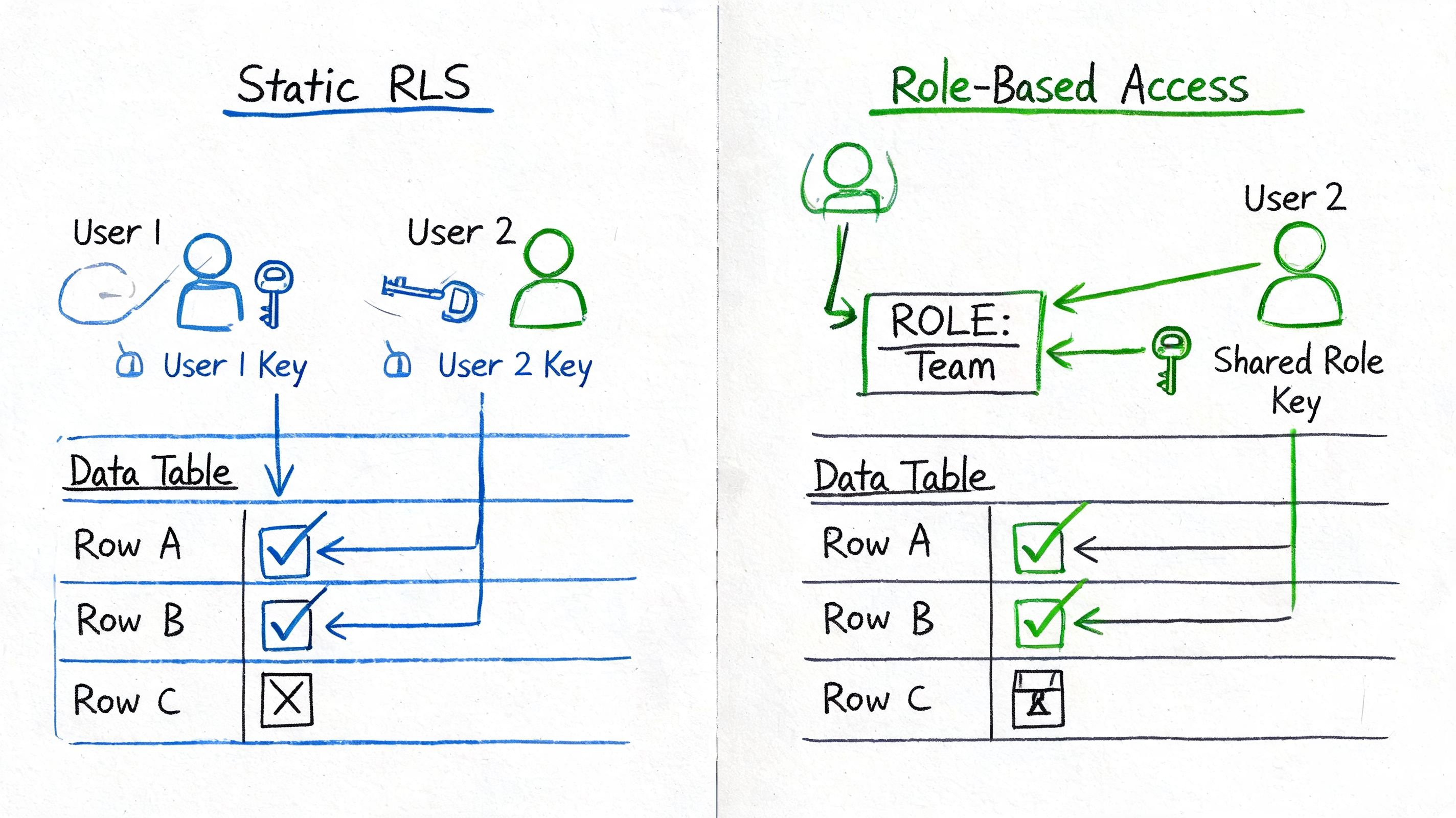
IBM’s documentation describes these two models as static role-based access control (RBAC) and dynamic attribute-based access control (ABAC), with performance implications that range from negligible to 40-60% query latency increases depending on join complexity in its discussion of row-level security implementation.
Static RBAC when the org chart matches access
Static RBAC is the simpler pattern. You create roles like north_america_sales, europe_finance, or support_tier_2, and attach policies that map those roles to row filters.
This works well when access boundaries are stable:
Regional sales teams who always see the same territory
Departmental reporting where finance, HR, and product have fixed boundaries
Partner portals where each partner maps cleanly to a known access scope
The upside is obvious. RBAC is easier to explain, test, and debug. If someone can’t see the right rows, you inspect their role membership and the policy attached to that role. That’s manageable for lean teams.
The downside shows up as the org gets more nuanced. One user covers two regions temporarily. Another needs access based on account ownership, not department. A contractor needs support data for one product line but not another. Soon the role list starts multiplying.
Dynamic ABAC when context matters more than roles
ABAC uses user attributes or session context instead of relying only on role membership. A policy might evaluate current_user_region, account_manager_id, or a session variable passed at login. This is often the right fit for multi-tenant apps and internal tools where entitlements depend on context.
For a deeper look at the multi-tenant use case, this guide on row-level security for SaaS analytics is a useful reference point.
ABAC scales better when access changes often, but the policy logic can get harder to reason about. If you depend on multiple joins to evaluate permissions, performance and debuggability can degrade quickly.
A useful rule is simple. If your access rules can be written on an org chart, start with RBAC. If they depend on account ownership, geography, product line, or session context, you’ll probably end up with ABAC.
Here’s a practical walkthrough that shows the mindset behind these trade-offs:
The entitlements table pattern
The pattern I trust most at scale is the entitlements table. Instead of hard-coding a long list of values inside each policy, create a table that maps users or roles to allowed scopes.
Example structure:
principal | scope_type | scope_value |
|---|---|---|
region | eu | |
product | analytics | |
role_sales_mgr | region | uk |
Then let your policy check membership against that table. This gives you a single place to maintain permissions, review changes, and automate provisioning. It also keeps policy definitions shorter and less fragile.
Don’t encode business ownership logic in five different policy files. Put entitlements in data where you can inspect and govern them.
Implementing RLS Across Major Data Warehouses
The details vary by platform, but the implementation pattern is similar everywhere. Define the access condition. Attach it to the table. Test with different identities. Then verify that downstream tools inherit the restriction.
A practical way to compare platforms is to use one example. Assume you have a sales table with a user_region column, and you want each user to see only the rows for their region.
RLS implementation syntax across warehouses
Platform | Create Policy Syntax | Apply Policy Syntax |
|---|---|---|
Snowflake | Create a row access policy with a condition based on current role or context | Attach the row access policy to the table or column reference used for policy evaluation |
BigQuery | Create a row access policy on the target table with a filter predicate | Grant filtered access through the policy definition on the table |
Redshift | Create RLS policy logic and associate it with roles or users | Attach the policy to the table for protected access |
PostgreSQL |
|
|
For teams working across engines, the core issue isn’t syntax memorization. It’s standardizing how the identity context reaches the warehouse. That matters more than whether the platform calls the object a policy, filter, or predicate. If you’re supporting multiple backends, a cross-warehouse workflow like chatting with Snowflake, BigQuery, and Redshift in one interface only stays safe if the same access model is enforced at the source.
Snowflake
In Snowflake, the common pattern is to define a row access policy and bind it to the protected object. The policy evaluates context such as current role, current user, or mapped entitlements.
That example is intentionally simple. In production, organizations often do not map business regions directly to database roles. They usually join through a permissions table or use a more explicit mapping layer.
What works well in Snowflake is centralizing the logic in the policy and keeping the business mapping outside the SQL text when possible. What doesn’t work well is scattering policy assumptions across role naming conventions nobody wants to maintain six months later.
BigQuery
BigQuery supports row access policies directly on tables. The approach feels closer to table-scoped filtering than to a reusable policy object.
The trade-off in BigQuery is operational clarity versus reuse. Table-scoped policies are straightforward, but if you need the same pattern across many datasets, you’ll want a disciplined rollout process and strong naming conventions.
In this domain, teams often underinvest in testing. They validate one dashboard and assume the policy is correct. A better test is to query the base table directly under the target identity and verify that unauthorized rows never appear.
Redshift
Redshift supports row-level filtering through policy definitions associated with users or roles. The structure depends on how you manage identity and session context, but the idea is the same. The database applies the filter before returning results.
Redshift implementations often become cleaner when the warehouse role model already mirrors business access patterns. If identity is inconsistent across BI tools, notebooks, and service accounts, policy design gets messy fast.
One practical lesson: separate human access from service-account access early. The exceptions pile up otherwise.
PostgreSQL
PostgreSQL remains the clearest way to understand the mechanics because the syntax is explicit. You enable row level security on the table, then create the policy.
You’d typically set the session variable at connection or transaction start, then let the policy evaluate it automatically.
If you use PostgreSQL-compatible systems, remember one sharp edge. In some implementations, the table owner may bypass policies unless you explicitly force enforcement. That’s the kind of detail that causes painful surprises in testing if you create the table with one user and validate access with the same one.
Implementation habit: Test RLS with the same kinds of identities your real users and applications will use, not only with an admin account.
Performance Governance and Auditing Best Practices
RLS is one of those features that looks elegant in architecture diagrams and gets expensive in real workloads if nobody governs it. The policy itself may be simple. The joins, cardinality, and downstream dashboards are where costs start to surface.
Recent 2025-2026 benchmarks from Snowflake’s own tests report RLS policies adding 2-5x latency on 10M+ row scans and increasing compute costs by 30% for dashboards in tools like Looker. That should change how you design policies, especially on large fact tables.
Performance work starts with policy shape
The biggest performance mistake is putting too much logic inside the filter path. If the policy has to evaluate multiple joins, string transformations, or nested lookups for every query, you’ve turned access control into a heavy query planning problem.
Better patterns include:
Precompute entitlements: Materialize user-to-scope mappings before query time when the permissions model is stable enough.
Index for the filter path: In engines where indexing matters, align indexes or clustering with tenant, region, or account keys used in RLS.
Prefer direct predicates: If a row already has
tenant_idorregion, use it. Don’t force a join if denormalizing a safe access key will simplify policy evaluation.Benchmark dashboard workloads: Test the actual dashboard and notebook queries people run, not only isolated table scans.
A lot of teams discover too late that their “secure” model works for one analyst query but drags in a production reporting workload. The policy needs to be part of performance engineering, not a late-stage add-on.
Governance needs a clear owner
RLS can’t be a shared responsibility in the vague sense. Someone has to own the policy model, change control, and exceptions process.
In startups, the right split usually looks like this:
Responsibility | Typical owner |
|---|---|
Policy framework and standards | Central data or platform team |
Business approval for who should see what | Functional leaders |
Provisioning and deprovisioning | Identity or admin workflow |
Validation and audit evidence | Data governance or security lead |
What doesn’t work is letting every BI developer invent their own policy pattern. That creates inconsistent logic, duplicate rules, and painful audits.
Auditing should test the policy not the dashboard
Auditors don’t care that a dashboard looks filtered. They care that unauthorized access can’t happen through another path. That’s why your audit process should validate the warehouse policy itself, plus the logs that show how access is enforced.
If your team is formalizing that process, this practical guide to the cyber security audit process is useful because it frames evidence collection and control validation in operational terms, not only compliance language.
A minimal audit checklist should include:
Role test cases: Query as each representative role and confirm visible rows match expectation.
Negative tests: Confirm users cannot retrieve rows outside their allowed scope.
Change logs: Track policy changes, entitlement changes, and approvals.
Query logs: Retain evidence showing access paths and identities used.
Unlocking Self-Serve Analytics with Querio and RLS
The full value of row level security becomes apparent when people stop relying on prebuilt dashboards as their only safe interface. That’s where notebook-based analytics changes the conversation. A notebook lets users ask open-ended questions, iterate, join data, and inspect results. Without strong warehouse-level controls, that flexibility can create real exposure.
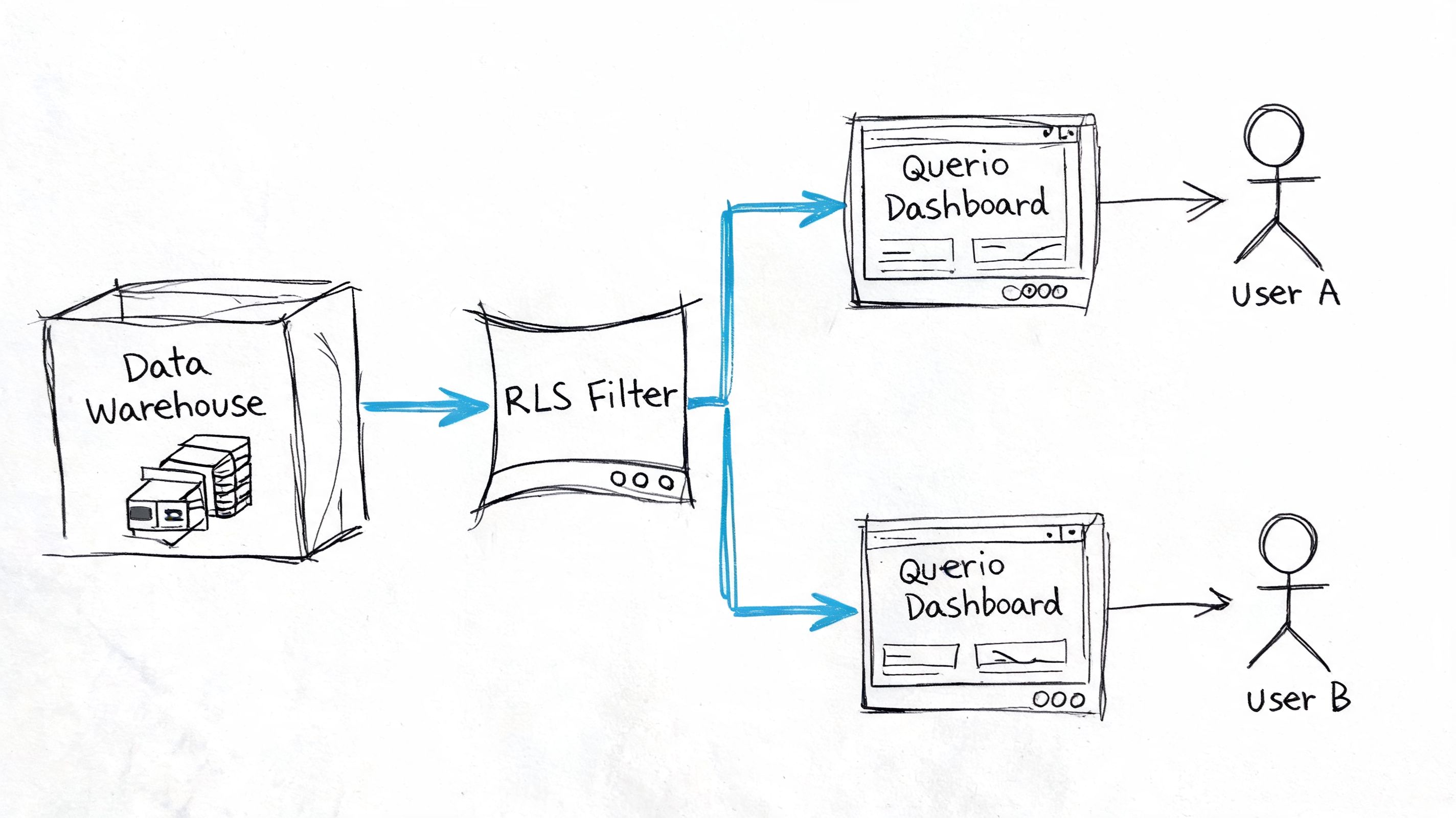
What the workflow looks like in practice
Take a common startup scenario. A product manager owns one product line and wants daily active users for the last month, segmented by plan tier. In the old model, they ask an analyst to either build a dashboard or write a filtered query. The analyst checks which accounts, products, and regions the PM is allowed to see, then bakes those assumptions into the request.
With warehouse-level RLS in place, the workflow is cleaner. The PM opens a notebook, asks the question in natural language, the platform generates SQL, and the warehouse enforces the policy at execution time. The user gets the freedom of ad hoc analysis without inheriting unrestricted table access.
That’s the model Querio’s secure NLQ platform is designed around: AI-generated queries executed against live warehouse connections where row-level restrictions are enforced by the data source, not recreated in a separate app-layer permission system.
When self-service works, analysts stop hand-authoring every filtered report and start maintaining the system that makes safe exploration possible.
Why notebook based self service changes the RLS conversation
Traditional BI tools often hide weak access design because users mostly click through predefined views. Notebook workflows expose it quickly. Users want to join tables, inspect edge cases, and ask follow-up questions the original dashboard designer never modeled.
That’s exactly why RLS matters more in modern self-service, not less.
A few practical patterns make notebook-based self-service workable:
Pass user identity cleanly: The notebook execution context needs a trustworthy identity or role mapping in the warehouse.
Define policies before tool rollout: If users can query a table before access rules are attached, self-service starts with a gap.
Keep semantic assumptions visible: Users should know what entity boundaries exist, even if they don’t need to understand every SQL predicate.
Avoid policy logic in the notebook layer: The notebook should generate analysis logic, not decide who can see which rows.
Where AI assisted policy setup helps
One of the blockers to wider RLS adoption is setup friction. A 2025 Stack Overflow survey of more than 90K developers found that 68% of data analysts struggle with RLS configuration due to complex syntax, while AI-assisted RLS generation can reduce setup time by 75% according to a 2026 Gartner report. Those figures are included in the verified brief for this article.
That matches what many teams experience in practice. The concept is easy to understand. The implementation details are not. Policy syntax, session variables, role mapping, and entitlement tables are manageable for engineers, but they’re often uncomfortable territory for product managers or business analysts.
AI assistance helps when it accelerates boilerplate and exposes the resulting policy logic for review. It doesn’t help when it hides the access model behind generated code nobody audits. The right use of AI is to draft, explain, and test policy definitions. The wrong use is to treat access control as something too tedious to inspect.
In notebook-based workflows, that distinction matters. You want users to ask broader questions without forcing the data team to approve every query. RLS provides the control boundary. AI can reduce the implementation burden. Together, they make self-service possible without turning the warehouse into an unmanaged free-for-all.
Conclusion Building a Secure Data Culture
Row level security isn’t a checkbox feature. It’s the access layer that lets a startup move from controlled reporting to real self-service analytics without losing control of sensitive data.
The practical lesson is straightforward. Put access rules in the warehouse. Keep them close to the data. Choose a policy model that matches your business complexity. Start simple if roles are stable. Move to attributes and entitlements when access becomes contextual. Then test those rules the way users query data, through BI tools, notebooks, and direct SQL paths.
The trade-offs are real. Poorly designed policies can slow queries and complicate operations. Weak governance can turn exceptions into a maze. But the alternative is worse. Without RLS, every self-service initiative eventually runs into the same wall: nobody trusts broad access, so the data team stays stuck answering routine questions by hand.
A secure data culture starts when teams can explore data independently within boundaries the business understands and the platform enforces. That’s what turns the data team from report builders into infrastructure owners. It also gives product, finance, operations, and leadership room to move faster without creating chaos.
If you’re building for scale, row level security deserves the same attention you’d give modeling, orchestration, or observability. It’s foundational.
If you’re evaluating ways to give teams notebook-style self-service on top of warehouse-enforced access controls, Querio is one option to review. It uses live warehouse connections and file-based analytical workflows so teams can query data more flexibly while keeping row-level restrictions anchored in the underlying data platform.

