Physical vs Logical Data Model: Unlocking Analytics Power
Understand critical differences between physical vs logical data model. Learn to choose, convert, and implement for faster, self-serve analytics.
https://www.youtube.com/watch?v=Ex6wszg2XZ8
published
Outrank AI
physical vs logical data model, data modeling, data warehousing, analytics engineering, self-serve analytics
4aec6744-8e6a-45ce-9d4d-a9b17497c76f

Your dashboards are live, but nobody trusts the numbers. Finance has one version of revenue, Product has another, and Sales keeps asking an analyst to “pull the actual figure.” Queries that should take seconds drag on. Every new metric request turns into a ticket. The data team becomes a routing layer for basic business questions.
That situation usually gets blamed on tooling, SQL quality, or team capacity. In practice, the root issue is often structural. The warehouse exists, the BI layer exists, and the pipelines run, but the underlying data model doesn't give the business a stable definition of what the data means or a performant way to retrieve it.
That's where the physical vs logical data model discussion stops being academic. A logical data model gives the business a shared blueprint for entities, relationships, and rules. A physical data model turns that blueprint into a database design that can support fast, reliable analytics at scale. If you're building a self-service platform, you need both. One protects meaning. The other protects performance.
Teams usually understand this only after they've already paid the tax. They've loaded data into a warehouse, built a semantic layer, and started shipping dashboards before agreeing on what “customer,” “active account,” or “net revenue” means. Or they've modeled the business well, then shipped a warehouse schema that can't handle interactive use. If your platform sits on top of a weak foundation, self-service becomes self-inflicted chaos.
A strong data warehouse foundation isn't just storage. It's a disciplined translation of business reality into structures people can trust and systems can run efficiently.
Table of Contents
Introduction The Hidden Cost of a Weak Data Foundation
Most Heads of Data inherit the same pattern. The company has enough data to be dangerous, enough tools to feel modern, and enough executive pressure to push self-service before the foundation is ready. Analysts spend their time reconciling metrics instead of building reusable assets. Engineers optimize slow queries one by one. Stakeholders lose trust because the same business question returns different answers depending on the dashboard.
That isn't a talent issue. It's a modeling issue.
When the underlying structure is weak, every downstream layer gets unstable. The warehouse becomes a dumping ground of raw and semi-modeled tables. BI tools expose inconsistent joins. Metric definitions drift by team. A self-service analytics stack without disciplined modeling doesn't reduce dependency on the data team. It just moves the confusion closer to end users.
Where the friction shows up first
The first symptoms are rarely labeled as data modeling problems. They show up as operational pain:
Conflicting reports: Different teams define core entities differently, so two dashboards can both be technically correct and still disagree.
Slow ad hoc analysis: Queries scan too much data because the storage layer wasn't designed around access patterns.
Analyst bottlenecks: Business users can't safely explore data on their own, so every question gets escalated.
Rework in every sprint: New product launches or reporting needs force schema changes that ripple through pipelines and dashboards.
A weak data foundation doesn't fail all at once. It fails every time a stakeholder asks a simple question and gets an answer nobody trusts.
Why both models matter early
The physical vs logical data model debate matters because each model solves a different failure mode. The logical model handles meaning. It defines the business entities, the allowed relationships, and the rules that make data interpretable. The physical model handles execution. It decides how those ideas become tables, columns, partitions, indexes, and constraints inside Snowflake, PostgreSQL, BigQuery, or another platform.
Teams that skip one of these layers usually feel productive at first. Then complexity arrives. More users, more source systems, more dashboards, more metrics, more exceptions. Without a logical model, consistency collapses. Without a physical model, speed collapses.
Self-service analytics only works when users can ask their own questions against data that is both understandable and fast.
The Logical Data Model Your Business Blueprint
A logical data model is the cleanest place to settle business meaning before database decisions distort it. It defines entities like Customer, Subscription, Order, Invoice, or Product. It defines attributes that describe them. It defines relationships between them. And it captures business rules without binding them to Snowflake, PostgreSQL, BigQuery, or any other implementation target.

That sounds abstract until you look at how analytics teams work. If one team thinks a customer is a billing account, another thinks it's an individual user, and a third treats it as a CRM company record, your self-service layer won't stay coherent. The logical model is where those conflicts get resolved before they become dashboard disputes.
According to the 2023 Global Data Management Survey by the Russell Group for Big Data, 68% of data engineering leaders identified the lack of a standardized logical data model as the primary cause of data silos that persist in 42% of mid-to-large enterprise organizations.
What the logical model actually captures
A useful logical model does a few things well:
It defines core entities clearly: Customer, Account, Product, Order, Subscription, Session, or whatever your business runs on.
It names relationships precisely: One-to-many, many-to-many, optional, mandatory, historical, or current-state.
It records business rules: What counts as an active customer, whether an invoice can exist without an order, how product bundles are represented.
It reduces ambiguity: Teams stop arguing in downstream tools because they've already aligned upstream.
The model is technology-agnostic, but it isn't vague. Good logical models are exact where business logic matters and neutral where platform details don't.
Why self-service depends on it
Self-service analytics lives or dies on consistent meaning. Business users don't need to know the warehouse internals, but they do need reliable entities and metrics. That's why the logical model pairs naturally with a semantic layer. The semantic layer exposes trusted concepts for exploration, and the logical model gives those concepts a durable foundation.
Practical rule: If your semantic layer is carrying unresolved business definitions, you're too late. Those decisions belong in the logical model.
Logical models also create a governance anchor. They let data teams review changes against business intent before implementation. That matters when product teams add new billing plans, when sales operations changes account hierarchies, or when acquisitions introduce a second CRM with different rules.
The logical model won't make queries faster. It does something just as important. It makes the data understandable enough that speed is useful.
The Physical Data Model Your Performance Engine
A physical data model takes the business blueprint and turns it into a working database design. Abstraction ends at this stage. You decide whether a field is VARCHAR(255) or TEXT, whether a measure belongs in a fact table, whether to cluster or partition by date, and whether a join path is acceptable for expected query patterns.
This is the part executives often underestimate because it looks like infrastructure detail. It isn't. The physical model decides whether self-service feels interactive or punishing.
What exists only in the physical layer
Logical models don't specify implementation details such as:
Indexing strategy: B-tree, Bitmap, Hash
Partitioning scheme: range, list, interval
Concrete constraints:
NOT NULL,UNIQUE,CHECKStorage-oriented type choices:
VARCHAR(255)vsTEXT,DECIMAL(10,2)vsFLOATWarehouse-specific optimization: file format choices like Parquet or ORC, columnar storage behavior, and memory allocation strategy
These details shape both system cost and user experience. A self-service platform that scans too much data or executes too many expensive joins trains users not to ask questions.
Why the physical model changes the user experience
Performance work isn't cosmetic. It directly affects adoption. Verified benchmark data states that physical data models introduce performance-critical specifications like indexing, partitioning, and storage engine optimizations, and strategic partitioning can reduce average query latency by 40–60% and improve I/O throughput by 2–3x.
That's why analytics teams often move from a normalized business view into dimensional structures such as a star or snowflake schema. They aren't abandoning rigor. They're making a conscious trade-off so common analytical paths become efficient.
If users wait too long for answers, they stop exploring. When they stop exploring, your self-service platform becomes a reporting portal with extra steps.
What works and what doesn't
What works:
Modeling around access patterns: Build for the queries people run, not just the source system shape.
Using denormalization selectively: Especially for read-heavy analytics workloads.
Encoding constraints where the platform supports them: Even when enforcement is partial, explicit structure helps downstream tools and developers.
Revisiting the model after usage emerges: Physical design should respond to real workload behavior.
What doesn't:
Treating physical design as a 1:1 export of the logical model
Assuming warehouse elasticity will cover poor schema choices
Pushing all optimization into BI extracts or caching
Designing only for engineering elegance while ignoring analyst behavior
The logical model tells you what the data means. The physical model decides whether people can use it at scale.
Core Differences A Side-by-Side Analysis
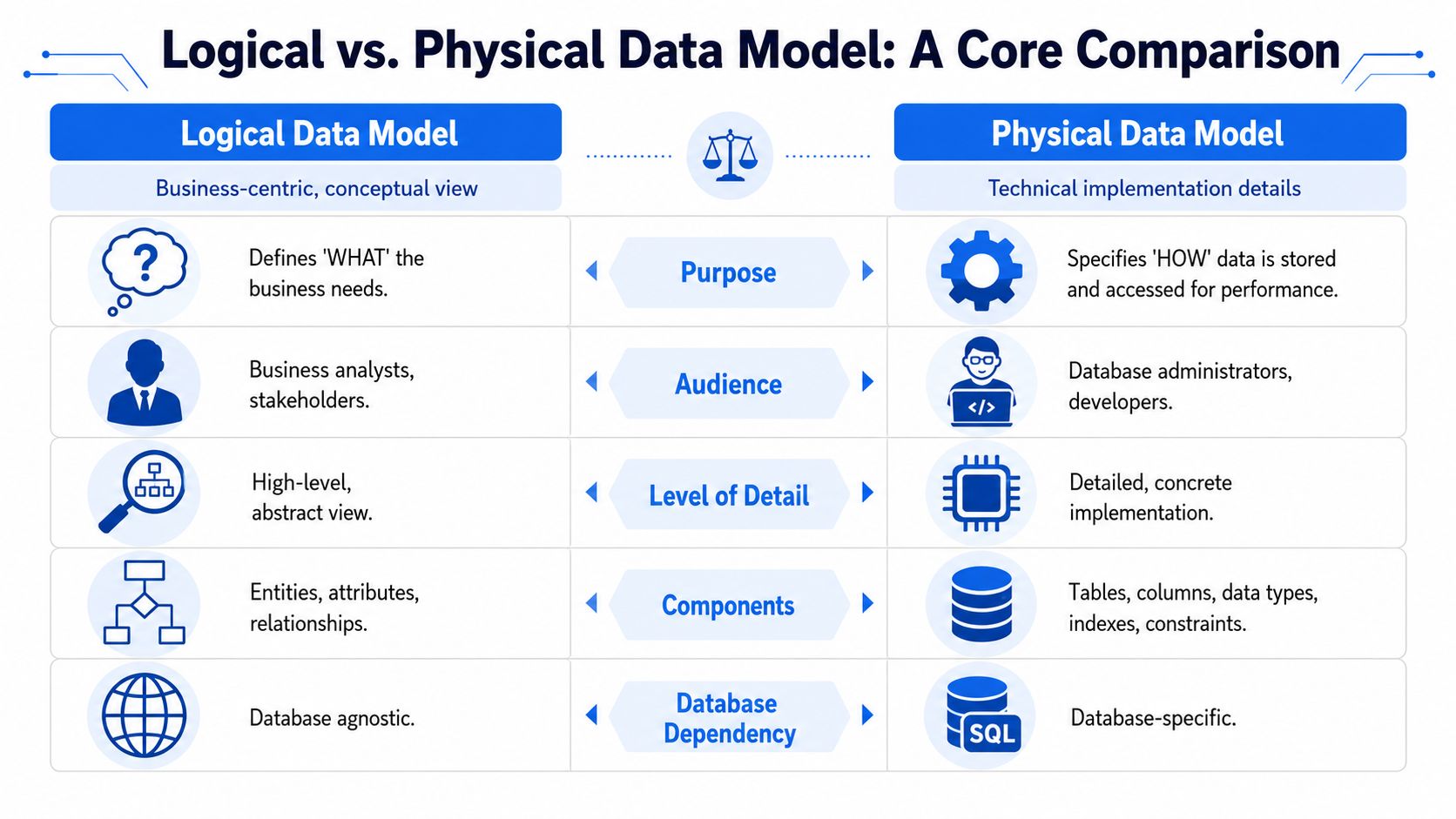
The easiest way to explain the physical vs logical data model distinction to stakeholders is to compare them on purpose, audience, and design pressure. One protects business meaning. The other protects execution.
Attribute | Logical Data Model | Physical Data Model |
|---|---|---|
Purpose | Defines what the business data represents | Defines how data is stored and accessed |
Primary audience | Business analysts, architects, stakeholders | Data engineers, DBAs, platform teams |
Level of detail | Entities, attributes, relationships, business rules | Tables, columns, data types, constraints, indexes |
Technology dependence | Platform-agnostic | Database-specific |
Normalization tendency | Usually normalized to preserve integrity | May be denormalized for performance |
Main risk if skipped | Conflicting definitions and unstable governance | Slow queries and weak scalability |
Typical output | ERD and business-aligned schema logic | Implementable schema and optimization choices |
The difference in one sentence
A logical model says, “An order belongs to a customer and contains products.” A physical model says, “Here are the tables, keys, data types, partitions, and constraints that make that query run acceptably on this platform.”
That distinction matters because the two models answer different stakeholder questions.
Where teams get confused
A lot of organizations collapse the two into one overloaded artifact. They put business definitions in dbt models, hide performance decisions in warehouse settings, and call the result “the model.” That works for a while, but it creates friction fast.
Common confusion points include:
Audience mismatch: Business stakeholders can't review warehouse-specific DDL meaningfully.
Change impact: A harmless business definition change can create expensive implementation side effects if the layers aren't separated.
Ownership drift: Analytics engineering, platform engineering, and business operations all modify the same structures for different reasons.
Communication gaps: Executives often value logical modeling as strategy but see physical modeling as low-level execution, even though both shape reporting quality.
There's a useful framing here. The logical model is the contract. The physical model is the machinery that keeps the contract usable.
The video below gives a quick visual explanation of how these layers differ in practice.
The trade-off leaders have to manage
The actual decision isn't logical versus physical. It's whether you want to separate meaning from implementation clearly enough to scale. Teams that do this well can evolve warehouse structures without constantly reopening metric definitions. Teams that don't end up renegotiating both at once.
The fastest way to lose confidence in self-service is to ask business users to navigate implementation detail and ask engineers to carry unresolved business semantics.
Translating the Blueprint From Logical to Physical
The move from logical to physical is where architecture becomes practical. It's also where many teams damage an otherwise strong design by assuming translation is mechanical. It isn't. The right physical model depends on workload, platform behavior, cost constraints, and who's using the data.

The translation decisions that matter
A disciplined translation usually follows this sequence:
Validate the business structure
Make sure the logical entities and relationships still reflect current operations. If the business definition is unstable, don't optimize yet.Choose the target platform
PostgreSQL, Snowflake, BigQuery, and Redshift each reward different physical patterns.Map entities into tables
Some entities become straightforward tables. Others split, merge, or materialize differently depending on query demand.Assign concrete types and constraints
At this stage, precision, nullability, uniqueness, and referential behavior become operational decisions.Shape for workload
Add indexes, partitions, clustering, summary tables, or warehouse-specific structures based on expected access patterns.Test with realistic queries
Don't sign off on the model using idealized examples. Use the messy joins and filters your teams run.
Normalization versus denormalization
This is the heart of the translation.
Logical models are typically normalized because normalization is excellent for data integrity and clear representation of business relationships. Analytics workloads, though, are often read-heavy and repetitive. Users ask for trends by time, product, account segment, geography, or lifecycle stage. That's where strict normalization can become expensive.
Physical models often denormalize intentionally into dimensional patterns. Fact tables carry events or measurements. Dimension tables carry descriptive context. Sometimes teams materialize summary tables or views to avoid repetitive heavy joins.
Verified benchmark data shows that physical models optimized for query patterns with denormalized star and snowflake schemas can achieve 5–10x faster response times for complex analytical workloads compared to strict logical-to-physical translations.
What a good translation looks like
A good translation preserves business truth while adapting storage for use. A bad translation copies every normalized entity into warehouse tables, then expects BI tools or analysts to solve usability and speed downstream.
Here's a practical way to judge the result:
If the model is pure but slow, it's incomplete
If it's fast but semantically messy, it's unstable
If business users need a senior analyst to explain every join, self-service isn't real
If every new dashboard requires a custom mart, the physical layer isn't doing enough
Design test: A user should be able to ask a common business question against trusted structures without needing to understand source-system quirks.
The best teams treat translation as iterative. They keep the logical model stable enough to govern meaning and the physical model flexible enough to support changing workloads.
Impact on Self-Serve Analytics and Data Governance
Self-service analytics fails in two predictable ways. Either users get access to data that isn't governed well enough to trust, or they get access to governed data that performs too poorly to use. The reason both failures are common is simple. Teams underinvest in one side of the model.
Why governance starts before implementation
A logical model creates the reference point for definitions, lineage conversations, and metadata consistency. It lets teams decide what a customer, contract, invoice, activation event, or churn state means before those ideas spread into dozens of warehouse models and dashboards.
That discipline pays off materially. According to IDG and the Data Management Solutions Group, organizations that rigorously implemented a logical data model before physical implementation reduced their data integration cycle time by 45% and decreased data redundancy errors by 62%. The same verified data states that 73% of failed enterprise database projects were attributable to skipping the logical modeling phase.
Those aren't just architecture outcomes. They are operating model outcomes. If your team has fewer integration cycles and fewer redundancy issues, it can spend more time enabling reusable analytics rather than resolving schema confusion.
Why performance determines adoption
Even perfectly governed data won't create self-service if every query feels heavy. Users don't separate semantic frustration from performance frustration. They just conclude that the platform is hard to use.
That's why physical modeling has direct governance consequences too. When the warehouse is slow, teams create workarounds. They export data to spreadsheets, build local extracts, cache metrics in one-off tables, or duplicate transformations in BI tools. Governance degrades because the sanctioned path is painful.
A strong physical model reduces that temptation. It makes the governed path the practical path.
What this changes for the data team
When both models are healthy, the data team stops acting like a human API and starts operating as infrastructure for decisions.
That shift usually looks like this:
Analysts curate shared logic instead of answering repeat questions
Engineers optimize reusable patterns instead of firefighting isolated dashboards
Business teams explore within defined guardrails instead of escalating everything
Governance becomes embedded in the model, not bolted on after incidents
For leaders, this is the key payoff of the physical vs logical data model approach. You get trust and speed at the same time. One without the other doesn't scale.
A practical next step is to align your modeling decisions with your broader data governance operating model. Governance works best when it's anchored in architecture, not just policy.
Frequently Asked Questions
Do you always need both a logical and a physical model
For any organization trying to scale self-service analytics, yes. Small teams sometimes get away with lightweight versions of both, especially early on. But the functions still need to exist. Someone has to define the business meaning, and someone has to turn that into performant structures. Calling one layer “informal” doesn't remove the need.
If you skip the logical model, metric definitions drift. If you skip the physical model, query performance becomes an afterthought.
Where does the conceptual data model fit
The conceptual model sits above both. It's the highest-level view of the business domain and helps stakeholders align on major entities and relationships before detailed modeling begins. It's useful when the business itself is still being clarified, such as during a new platform build, a merger, or a major product expansion.
In practice, Heads of Data usually feel the day-to-day pain more acutely in the logical and physical layers because that's where analytics trust and performance break.
How do these models apply in a modern stack with dbt
dbt is helpful, but it doesn't replace modeling discipline. It gives teams a strong way to express transformations, test assumptions, and manage warehouse logic in code. The problem starts when teams treat dbt models as the only modeling artifact. Business semantics get buried in SQL, and implementation decisions bleed into stakeholder-facing definitions.
The stronger pattern is to keep the logical model explicit, then use dbt and warehouse-native features to implement and evolve the physical layer.
Can the same logical model support multiple physical models
Yes. That's often the right approach. You may keep one business-aligned logical model, then create different physical implementations for operational reporting, finance-grade reconciliation, and exploratory analytics. The business meaning stays stable while implementation adapts to workload and platform needs.
That separation is one reason mature data teams can support multiple tools without redefining core entities every time.
What about spreadsheet-driven teams and lightweight workflows
Not every team starts inside a warehouse. Sometimes product ops, marketplace teams, or ecommerce managers begin with spreadsheets and connector-based reporting. In that case, it still helps to think in logical and physical terms. Define the business entities and rules first, then decide how the data should be structured for use. If your team is trying to automate Amazon data in Google Sheets, the same principle applies. A clean business definition prevents spreadsheet logic from fragmenting across tabs and owners.
What's the most common mistake
Treating physical modeling as “just IT work” is near the top of the list. Leaders usually recognize the strategic value of business definitions. They don't always recognize that performance design determines whether those definitions can be used consistently in practice.
The other common mistake is assuming self-service can compensate for weak modeling. It can't. Self-service amplifies whatever foundation you give it.
If your data team is overloaded, the answer usually isn't another dashboard layer. It's better infrastructure for asking and answering questions. Querio helps teams turn the warehouse into self-service analytics infrastructure with AI coding agents, flexible notebooks, and a workflow that supports both technical and non-technical users without turning analysts into a ticket queue.

