SQL vs Python A Guide for Modern Data Teams
Explore the SQL vs Python debate. Learn when to use each, how to combine them for powerful analysis, and what skills your data team needs to succeed.
published
Outrank AI
sql vs python, data analytics, python for data, sql for data, data engineering
47cee182-4306-4e0a-8ea9-16b1e4ddd7ac

The SQL vs. Python discussion isn't about picking a winner. It’s about understanding that you're dealing with two fundamentally different tools, each designed to solve a different part of the data puzzle. One is a master locksmith for databases; the other is a complete workshop for everything that comes after.
SQL vs Python: Understanding the Core Roles
Think of SQL (Structured Query Language) as the native tongue of the database. Its entire existence is optimized for one job: pulling, filtering, joining, and aggregating massive amounts of structured data right where it lives. When you need to grab specific records from a table with billions of rows, SQL is your most direct and efficient path. It’s built for this scale.
Python, on the other hand, is the versatile generalist. While it has libraries to connect to databases, its real power kicks in once you have the data. Python is where you turn for tasks that are simply out of scope for SQL—things like complex statistical modeling, building and deploying machine learning pipelines, automating repetitive tasks, or creating interactive web-based visualizations. For a primer on the fundamentals, our guide on what is a database and what is sql is a great starting point.
The performance difference for raw data processing is stark. A modern data warehouse running SQL can scan billions of rows in seconds thanks to its underlying architecture, which often uses columnar storage and massively parallel processing. Python, running on a single machine, simply can't compete at that initial retrieval stage.
Quick Comparison SQL vs Python At a Glance
To make the distinction even clearer, let's break down their core attributes side-by-side. This table gives you a high-level look at where each tool fits.
Aspect | SQL | Python |
|---|---|---|
Primary Function | Data query, manipulation, and management within a database. | General-purpose programming for analysis, modeling, and automation. |
Core Strength | High-speed, set-based operations on massive structured datasets. | Flexibility, statistical capabilities, and a rich ecosystem of libraries. |
Ideal Use Case | Aggregating sales data, joining user tables, and filtering records. | Building predictive models, advanced statistical analysis, or web scraping. |
Nature | Declarative (You declare what you want). | Procedural/Imperative (You describe how to get it). |
Ultimately, SQL is declarative—you tell the database what data you want, and its highly optimized engine figures out the best way to get it. Python is procedural—you write explicit, step-by-step instructions telling the computer how to perform a calculation or transformation. This difference in approach is key to understanding why they aren't competitors, but partners.
Syntax and the Real-World Learning Curve
It’s a common oversimplification: SQL is easy, and Python is hard. There's a sliver of truth there, of course. A basic SELECT statement is certainly more straightforward than getting a Python environment running for the first time.
But this view completely misses the real journey to mastering either tool. The path from novice to expert in SQL and Python involves very different, and equally significant, learning curves.
SQL’s initial appeal is its gentle slope. The syntax is declarative and almost reads like a structured English sentence, which lets new analysts start pulling real data almost immediately. You tell the database what you want, not how to get it. A query like SELECT customer_name FROM sales WHERE purchase_date > '2024-01-01' is instantly understandable.
The problem is, the difficulty doesn't stay that way. It skyrockets once you move beyond simple retrieval. True SQL mastery isn’t about SELECT, FROM, and WHERE; it's about wrangling the surprising complexities of advanced functions and query optimization.
The Hidden Depth of Advanced SQL
To really master advanced SQL, you have to shift your thinking. It's less about writing commands and more about understanding how the database engine thinks so you can craft efficient, set-based logic. This is where most people hit a wall.
Key areas that represent this much steeper learning curve include:
Window Functions: These are game-changers for performing calculations across related rows, like creating a running total or ranking products within categories, without resorting to clunky self-joins.
Common Table Expressions (CTEs): Using the
WITHclause is essential for breaking down monstrously long queries into logical, readable steps. It's the key to writing code that your future self (or your teammates) can actually maintain.Complex Joins and Subqueries: Anyone can write an
INNER JOIN. But knowing when and how to useLEFT,CROSS, and correlated subqueries without bringing a database to its knees is a different skill entirely.Query Optimization: This is the big one. It's about reading execution plans, understanding indexing, and structuring your query to minimize resource use on tables with billions of rows.
A senior analyst who can write a single, optimized SQL query using window functions to calculate Monthly Recurring Revenue (MRR) can often deliver results faster and more efficiently than a junior data scientist struggling to load and process the same raw data in Python.
Python’s Ecosystem Challenge
Python's syntax is famously clean and readable. But the real learning curve isn't the language itself—it’s the massive ecosystem of specialized data libraries you need to get anything done. Being "good at Python" for data work means becoming proficient in a whole suite of tools, each with its own quirks and conventions.
For an analyst or data scientist, the core stack includes:
Pandas: This is your workhorse for in-memory data manipulation, built around its powerful DataFrame object. But its syntax can feel inconsistent, and mastering its indexing rules (
locvs.iloc) is a rite of passage for every new user.NumPy: The foundation for all numerical computing in Python. It provides the high-performance array objects that power most other data libraries.
Matplotlib/Seaborn: The standard libraries for creating static, detailed visualizations for reports and presentations.
Scikit-learn: The go-to library for machine learning. It covers everything from regression to clustering with a remarkably consistent API.
While Python offers incredible flexibility, its procedural nature puts the burden on you to manage every step. You're the one telling the computer how to do everything. When deciding on a tool, it's also smart to see how they stack up against other statistical software. For a deeper dive, check out our guide on when to use R, Python, SPSS, or SAS.
Ultimately, building true proficiency across this entire stack is a major investment of time and effort.
Analyzing Performance in Modern Data Stacks
When we talk about SQL vs. Python performance, it's easy to get fixated on raw speed. But that's missing the point. The real question isn't which one is faster, but where each tool performs best within your data stack. It's a conversation about architectural fit, not just a stopwatch.
SQL’s dominance in large-scale data crunching is practically undeniable. This isn't because the SQL language itself is magical; it's because of the incredible engineering behind the database engines that run it. Modern data warehouses like Snowflake, Google BigQuery, and Amazon Redshift are built from the ground up for this kind of work, employing massively parallel processing (MPP), columnar storage, and sophisticated optimizers to tear through petabytes of data.
Think of it this way: when you run a SQL query, you're not just running a script. You're handing instructions to a distributed supercomputer designed for one thing: set-based operations. It splits your request across hundreds or thousands of nodes, processing data in parallel right where it lives. For the bread-and-butter work of filtering, joining, and aggregating massive tables, nothing else comes close.
Where Python Steps In
Python picks up where SQL’s rigid, set-based logic hits a wall. Its power lies in procedural flexibility and a massive ecosystem of libraries built for tasks that are clumsy, inefficient, or downright impossible in pure SQL. These are the jobs that require row-by-row iteration, custom logic, or advanced math.
This is where Python really shines:
Iterative Machine Learning: Training a model involves looping over a dataset again and again, tweaking parameters with each pass. This is completely natural for Python's procedural style but fundamentally at odds with how SQL works.
Complex Statistical Simulations: Need to run a Monte Carlo simulation or a complex statistical model? You’ll be generating thousands of variables and applying custom functions. That’s home turf for Python libraries like NumPy and SciPy, but it's not what databases were made for.
Handling Unstructured Data: Parsing messy JSON, scraping websites, or processing images are all well outside of SQL's wheelhouse. Python handles these tasks without breaking a sweat.
For the initial, heavy-lifting of data retrieval and aggregation from a warehouse, SQL is the undisputed champion. But for the complex, iterative analysis that comes next, Python takes over. The trick is knowing where to hand off the baton.
Narrowing the Gap with Modern Libraries
The performance gap is also closing for many in-memory operations. While Pandas has long been the go-to, the Python ecosystem is constantly producing faster, more efficient tools that challenge traditional performance benchmarks.
Libraries like Polars and Dask are perfect examples. Polars, built in Rust, brings its own query optimizer and parallel execution to offer huge speed boosts over Pandas for common data manipulations. Dask, on the other hand, lets you scale your existing Python code—including Pandas DataFrames—across multiple cores or a full cluster, bringing parallel computing straight to your notebook.
This means that once you’ve pulled data from the warehouse, Python is more capable than ever of handling large datasets efficiently. You can dig deeper into getting the most from your database in our guide on how to optimize SQL for real-time visuals. Ultimately, the most effective workflows use a hybrid approach: let SQL do the heavy lifting, then pass a cleaner, smaller dataset to Python for the nuanced work of modeling, advanced analysis, and visualization.
When to Use SQL vs. Python: A Practical Guide
The endless debate over SQL versus Python misses the point. It’s not about picking a winner; it’s about knowing which tool to pull out of your toolbox for the job at hand. The right choice always comes down to your immediate goal. Are you just trying to get a feel for the data, are you building a production pipeline, or are you spinning up a predictive model? Each task has a natural fit.
This flowchart maps out the high-level decision points.
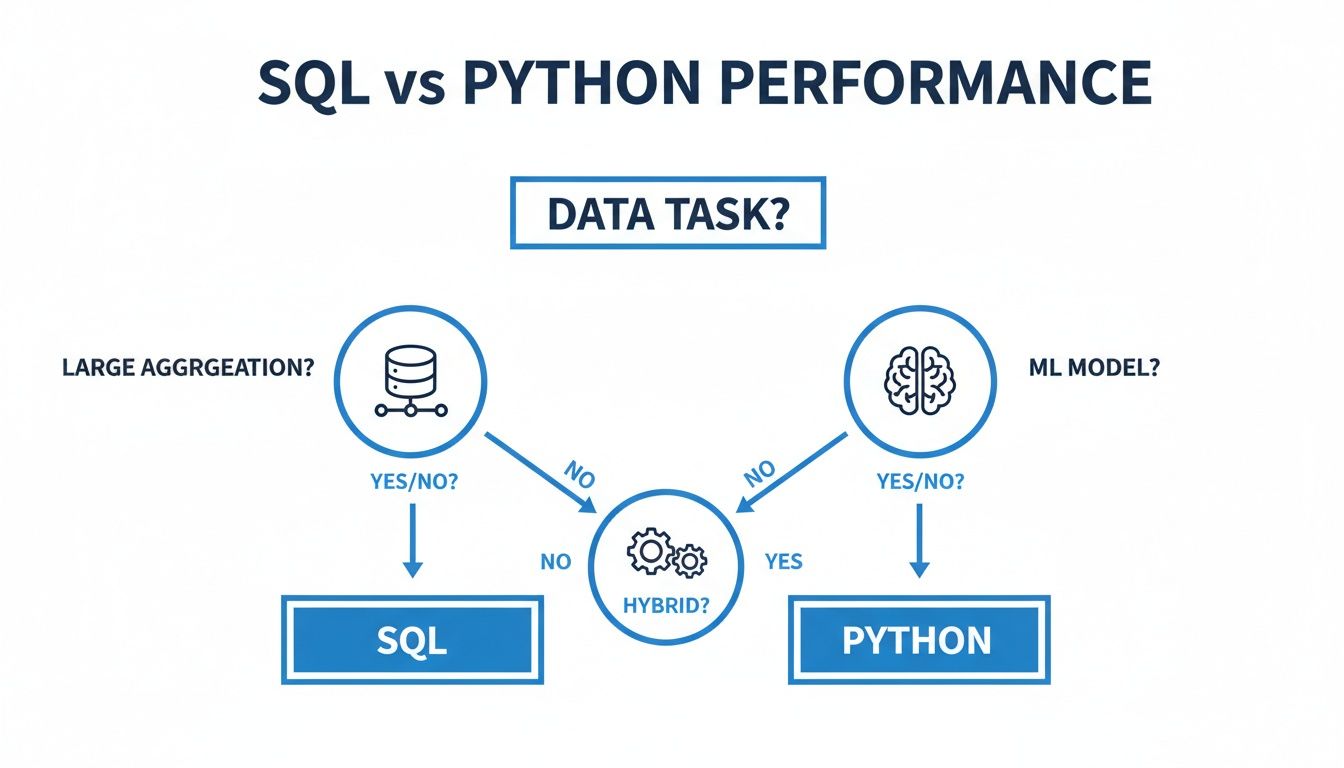
As you can see, the path is pretty clear: large-scale aggregations are SQL’s home turf, machine learning is a job for Python, and anything in between often requires a smart blend of both. Let's dig into these common scenarios to give you a clearer sense of how to make the right call every time.
Exploratory Data Analysis (EDA)
When you first get access to a massive new dataset in your warehouse, the first step is always to figure out what you're even looking at. For that initial reconnaissance, SQL is your fastest path to insight.
Say you need to find your top 10 customer segments from a 500 million-row sales table. A simple SQL query can crunch those numbers directly inside the database and hand you back a tiny, ten-row result in seconds. You haven’t moved any raw data, and you’ve let the database do what it does best. That’s a win.
But what happens next? Once you have that summary, your questions almost always get more sophisticated. You’ll want to visualize sales distributions, run a correlation analysis, or perform a few statistical tests. This is your cue to switch to Python. With libraries like Pandas, Matplotlib, and Seaborn, Python gives you the statistical depth and custom visualization power that’s simply out of reach for SQL or most BI tools.
So, the EDA workflow looks like this:
Start with SQL for the heavy lifting. Use it to filter, join, and aggregate huge tables down to a manageable size, right inside the warehouse.
Then, switch to Python for the deep dive. Pull that smaller, pre-aggregated dataset into a notebook to explore its statistical nuances and build rich visualizations.
Building ETL and ELT Pipelines
Data pipelines are the circulatory system of any analytics organization. Where Python and SQL fit in often depends on which letter you emphasize in your pipeline: the "T" in ETL or the "T" in ELT.
In the modern ELT (Extract, Load, Transform) paradigm, SQL is absolutely dominant. Tools like dbt have cemented SQL as the language for transforming data after it’s already landed in the warehouse. This approach is brilliant because it uses the raw power of your data warehouse to handle massive transformations at scale.
On the flip side, traditional ETL (Extract, Transform, Load) workflows often lean heavily on Python. If your job involves pulling data from five different APIs, cleaning up messy CSVs, or performing complex data validation before it hits your warehouse, Python is the obvious choice. Its rich ecosystem of libraries for handling web requests and wrangling data makes it perfect for these pre-load transformations.
For rapid cohort analysis directly in your warehouse, start with SQL. For building a customer churn prediction model, Python’s Scikit-learn is the standard.
Predictive Modeling and Machine Learning
When it’s time to build, train, and deploy machine learning models, the conversation is over before it starts: this is Python’s territory. The entire modern data science stack is built on it.
SQL simply wasn't built for the kind of iterative, procedural logic that model training requires. Critical steps like feature engineering, hyperparameter tuning, cross-validation, and serving the final model are all handled by Python’s incredible libraries—chief among them Scikit-learn, TensorFlow, and PyTorch.
You will almost certainly use SQL to pull your initial training dataset from the warehouse. But from that point on, the entire modeling lifecycle happens in a Python environment. It provides the statistical rigor, algorithms, and computational flexibility that SQL can’t. This clear division of labor makes the decision process for any data science project incredibly straightforward.
Building a High-Impact Data Team
The SQL vs. Python debate is more than just a technical squabble—it's a blueprint for building your entire data organization. The skills you cultivate on your team will directly determine the kinds of questions you can ask and the products you're able to build. Building an effective team isn't just about hiring experts; it's about understanding how the roles defined by each language fit together and, crucially, making sure they actually talk to each other.
A classic mistake is letting silos form. You end up with one side of the house speaking fluent SQL, churning out reports and dashboards, while the other side speaks Python, quietly building models in isolation. This divide creates friction, slows down projects, and kills your ability to turn data into real business value. A truly high-impact team isn’t just full of specialists; it’s full of connectors.
Defining Core Data Roles
It's natural for expertise in SQL and Python to lead to specialized roles, and both are essential for a well-rounded data function.
Data Analysts & Analytics Engineers are the masters of SQL. They live and breathe the data warehouse, transforming raw, messy tables into the clean, reliable datasets that power business intelligence and reporting. Their strength is working with data at scale, right at the source.
Data Scientists & Machine Learning Engineers are Python natives. Their work often picks up where the analyst's leaves off. They take that clean, structured data and use it to build predictive models, run sophisticated statistical tests, or automate complex processes.
The most successful organizations see these not as opposing camps but as two halves of the same brain. You can explore the specific duties and distinctions between these roles in our detailed guide on the data scientist vs data analyst.
The Power of Bilingual Professionals
While specialization is important, the real force multipliers on a data team are the "bilingual" pros—the ones who are fluent in both SQL and Python. These are the people who can see a project through from start to finish, from raw data extraction all the way to model deployment, without awkward handoffs. They know how to write an efficient SQL query to pull exactly the right data and can immediately pivot to a Python notebook to explore it further.
This dual skill set has become a massive career advantage. In fact, demand for data professionals with both SQL and Python skills is surging, with the U.S. Bureau of Labor Statistics projecting data science roles to grow by more than 33% by 2034. While Python consistently tops language popularity contests, SQL is so foundational to every data-driven company that the combination is an undeniable career accelerator.
A single person who can write a complex SQL query to define a customer cohort and then immediately build a churn prediction model for that group in Python can deliver a project in half the time it would take a siloed team.
Creating a Unified Data Culture
To prevent these knowledge silos from forming, team leads have to actively push for collaboration and cross-training. This doesn't mean every analyst needs to become a machine learning wizard, but they should feel comfortable using Python for basic data manipulation. When you're building a truly high-impact data team, bringing in strong Python expertise is a must. You might even need to hire dedicated python developers to lead advanced projects and mentor the rest of the team.
Here are a few practical ways to build a more unified culture:
Use Shared Tools: Adopt platforms where SQL and Python can live together happily, like modern notebooks that connect directly to the data warehouse.
Run Cross-Functional Projects: Intentionally pair a SQL-first analyst with a Python-native data scientist on the same project. This forces them to learn each other's language and workflows.
Invest in Training: Offer internal workshops like "Python for SQL Analysts" or "Advanced SQL for Data Scientists" to help bridge the gap.
Ultimately, you want to build a team whose first instinct is to choose the best tool for the job, not just the tool they know best. That kind of collaborative, tool-agnostic mindset is the bedrock of any modern, high-impact data organization.
How to Effectively Use SQL and Python Together
Forget the endless "SQL vs. Python" debates. In practice, the most effective data teams don't choose one over the other; they make them work in tandem. The real conversation is about creating a smart, efficient workflow where each tool plays to its strengths.
The time-tested pattern is simple: let SQL do the heavy lifting inside the database, then hand off a refined dataset to Python for the finishing touches. SQL is purpose-built for slicing, dicing, and aggregating massive datasets right at the source. It’s far more efficient to ask the database for a summary than to pull billions of rows across a network.
This classic handoff typically involves two steps:
1. SQL for Extraction: You start by writing a query to pull only the data you actually need. Instead of downloading an entire raw table, you use SQL to filter, join, and pre-aggregate the data, shrinking it down to a manageable size.
2. Python for Analysis: This much smaller, focused dataset is then loaded into a Python environment. From there, you can use libraries like Pandas, Scikit-learn, or Matplotlib for complex modeling, statistics, or custom visualizations.
While this workflow is logical, it isn't without its headaches. Exporting data—even a smaller subset—creates friction. It's often slow, introduces potential security risks, and leads to multiple copies of the same data floating around, which is a nightmare for governance.
Unifying Workflows in Modern Notebooks
Fortunately, a new generation of data platforms is built to dissolve this barrier. Tools like Querio are changing the game by letting Python notebooks run directly on top of the data warehouse. It sounds like a small change, but the impact on daily workflows is huge.
When your Python environment is natively connected to the warehouse, the entire data export step vanishes. An analyst can write a SQL query in one cell and, in the very next, start working with the results using Python. No downloads, no CSV files, no hassle.
Instead of a clunky handoff, you get a continuous conversation. You use SQL to ask the warehouse a question, and then immediately use Python to interrogate the answer—all in one place, without ever moving the data.
This integrated approach makes everyone more effective. Analysts who live in SQL can easily begin adding powerful Python functions to their work without getting bogged down in environment setup. Meanwhile, data scientists can use a quick SQL command to shape their data before diving into complex modeling, dramatically speeding up their iteration cycles.
It creates a shared space where different skills converge, making the whole team faster and more capable.
Frequently Asked Questions
When teams start blending SQL and Python, a few questions always surface. Getting these answers right is less about picking a winner and more about building a smart, collaborative data strategy. Let's tackle the questions I hear most often.
Thinking through the SQL vs. Python debate is essential. It helps you sidestep common traps and get the most out of your team's skills.
Can Python Completely Replace SQL?
In a word, no. And frankly, you wouldn't want it to. SQL’s entire reason for being is to talk to databases. It is simply unbeatable for fetching, joining, and manipulating huge datasets right where they live. The query optimizer inside a modern database is a finely tuned engine, built for one purpose: handling these tasks with incredible speed.
Trying to make Python pull terabytes of raw data just to run a simple GROUP BY would be a massive performance bottleneck. It’s like using a Ferrari to haul gravel—it'll do it, but it's the wrong tool for the job and you'll ruin the car. For large-scale data retrieval and in-database transformation, SQL is still the king.
Python can absolutely connect to and query a database, but it can never match the raw performance of a native SQL engine running inside the warehouse. The goal isn’t replacement; it’s intelligent integration.
What Should a New Startup Prioritize?
For any new startup, the answer comes down to your most immediate business goals and what your product actually does. Your first data hire should directly address your most urgent need.
Prioritize SQL if you're focused on Business Intelligence (BI). If the top priority is building dashboards, tracking KPIs, and making sense of user behavior, SQL is your bedrock. You need a data analyst who can quickly translate raw data into business insights.
Prioritize Python if you're building data products. On the other hand, if your startup’s secret sauce involves predictive features, recommendation engines, or complex automation, you need Python on day one. Your first hire should be a data scientist or machine learning engineer.
How Do Modern Platforms Change This Dynamic?
Modern data platforms are completely reshaping the old SQL vs. Python debate by simply erasing the wall between them. Unified environments, especially notebooks that run directly on top of the data warehouse, are a game-changer. They get rid of that clunky, traditional workflow of exporting data from a SQL client just to import it into a Python environment.
This tight integration means analysts and data scientists can use both languages in a single, fluid session. You can write a SQL query to define a customer cohort, and in the very next cell, use a Python library like Scikit-learn to build a churn model on that exact data. This approach kills data movement bottlenecks and lets everyone use the best parts of both languages without constantly switching contexts.
At Querio, we’re built for this powerful partnership. We deploy AI agents and custom Python notebooks directly on your warehouse, empowering your entire team to blend SQL and Python without friction. This transforms the data team from a bottleneck into an engine for self-serve analytics. Learn more about how Querio can help scale your data capabilities.

