
Mohammed Hussain

Engineering
6
m
We Almost Over-Engineered Our Job Worker
jobs jobs jobs steve jobs?
we've recently introduced a new service to our family, steve, and we almost over-engineered the hell out of the poor guy.
steve is a bun server, that needed to be lightweight, fast and dumb. no knowledge of any system, just a worker who picks up jobs off a queue, spins up a handler to deal with it, then kills the handler and goes again.
in production, steve is already handling jobs which don't require scheduling - adhoc job requests that only run once, a good example of this is background data warehouse introspection. the natural next step was to extend his ability to deal with scheduled jobs, for things like board syncs. but before picking up the claude code reins to begin planning out this implementation - i took a poke around other engineering blogs and see how this problem is traditionally solved.
after reading blog posts from slack, airbnb, dbos, what i found is that typically solutions have a 3 man process in a trad job queue workflow. it usually looks a little something like this:
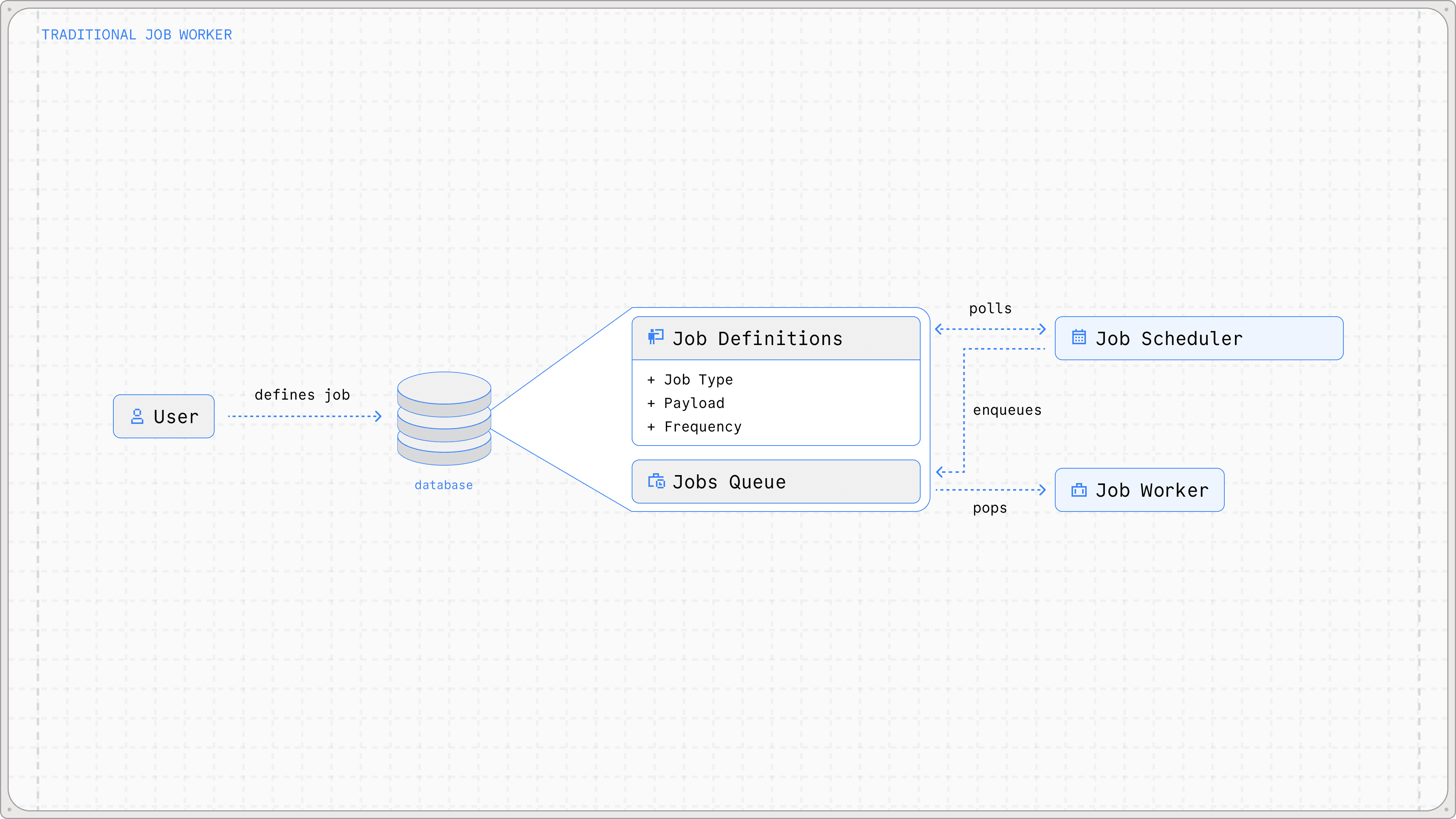
the user creates some kind of job definition, sticks it into the database, then a separate job scheduler service polls the definitions and schedules jobs, which get picked up and handled by a worker. this is nice, tried and tested, and generally works well. but it introduces an additional two services to our system. the worker (which we've already committed to build and extend) and the job scheduler.
this brings us to problem one
pls pls no more services
is what nik told me when i was planning this architecture. i replied with "well, someone needs to schedule the damn jobs, not like we can cron them"
hang on a minute
we should cron them.
how else could we possibly schedule these jobs without a dedicated service to do this? well, we had a few options:
steve +
webapp -
pg_cron ++
job scheduler --
we first pondered implementing the scheduler service into our webapp, risking mixing concerns in a major way. the benefit here was that vercel would spin up an edge process, run the scheduler function and die— it'd be pretty cheap and nicely coupled with our existing infra, and would allow us to utilise the cron-parser package to calculate next run times. but if there's anything worse than building and standing up a new service in our infra, it's deepening our relationship with vercel and our reliance on their... vercel-magic. nik would have my head on a stick if i'd gone ahead with this, rightfully so.
passing steve the responsibility of scheduling jobs, expands the complexity of this guy and introduces him to information his simple mind need not know. he'd need awareness of cron expressions, access to job definitions, and logic to calculate next run times — none of which a worker should care about. we wanted steve to stay stateless: pick up job, run the handler, forget.
building another service isn't the end of the world. we could've built a job scheduler, but we've made an active effort to slim down our footprint and be more considered in standing up new services, packages, dependencies, whatever. its made us more laser focused on how we can achieve our requirements without needing to expand technical debt or maintenance overhead. for this reason, building out a new service, particularly when other, better alternatives were present didn't seem worth it. not to mention the additional cost, maintenance and failure modes that introducing this service would gift us.
as part of a job definition, the user defines a simple cron expression for how often they need this specific job to run. we know the next run time in the frontend because we use a library cron-parser which does the heavy lifting for us and gives us a nice clean api to convert to and from cron expressions.
so, the thought here was that utilising pg_cron could actually be quite the time saver. we'd have a handful of clean functions we can use and it would slot cleanly into our existing infrastructure. our neon postgres db is serverless, but always warming so this looked like the strongest option.
the initial thought looks like this
so, we offset the job scheduling directly to the database, using pg_cron. at least, that was the thought.
in an ideal world, postgres would regularly check the job definitions to find a job whose next run was scheduled, add the job to the queue and then update the next run time for the job definition. but we don't live in an ideal world. pg_cron doesn't expose any api to calculate a datetime from a cron expression, so calculating the next run wasn't possible unless we built a bespoke cron parser function in our database. not only would this be horrible to maintain, but the thought of having this function append a job onto the queue and then sequentially update the next run time was making me sweat behind the knees.
the solution to both of these problems was to take a step back and leverage more of the flexibility pg_cron gives us.
schedulers are overrated
instead of building the job scheduler into postgres, we now fully omit the need for a scheduler altogether. 'but how?!?' you might be asking. let me indulge.
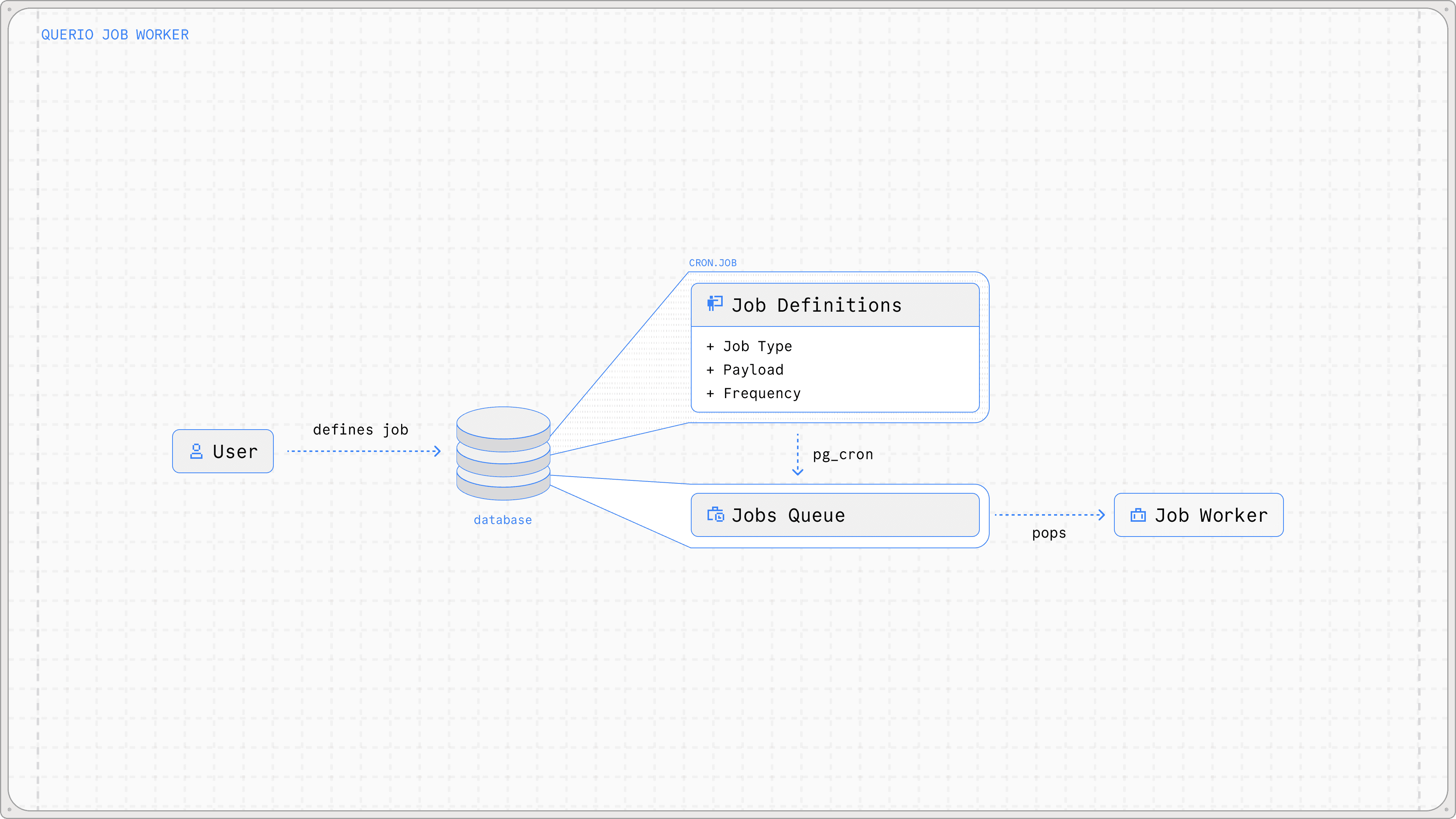
so we built a clean adapter to the cron.job table in our frontend that maps the user's payload into a cron payload
now when a user creates a job definition, we directly call a pg_cron function. cron.schedule which inserts this new job into the cron.job table.
this way all user job definitions now live inside the cron.job table and we've claude coded crud actions to manipulate them. our buildInsertCommand returns a payload that looks like this, giving the job queue all it needs to be completed.
cron is helping us out by executing this payload on schedule, enqueuing the job for it to then be picked up— with no skin off our nose, thanks to the resolution provided by pg_cron. it's simple.
pg_cron maintains its own internal scheduler— it wakes up every minute and checks the cron.job table, executing any matching jobs. by baking our job definitions directly into the cron jobs table, we're getting scheduling for free.
this solution will become brittle at scale, it will introduce significant load onto our database. in the near future when we hit tens of thousands of jobs, we'll run into connection pool pressure, every time a pg_cron job fires, we open up a database connection to execute that enqueue— at tens of thousands of jobs, this means potentially hundreds of jobs firing in the same minute window ontop of normal database usage..
even worse, we'll essentially be praying to the black box that is pg_cron hoping that it remains working, with no way to really observe what's going on under the hood. we could of course keep an eye on the cron.job_run_details to have a look what's going on, but it's not a concrete monitoring solution.
but for the time being, while we have tens to hundreds of active jobs, this solution is pretty elegant, works consistently and abstracts scheduling logic into a technology we've had for over 50 years, cron.
theres a lot more to this story, in the next post i'll explain a bit more about steve, how he currently works, and how he was almost going to deal with what we like to call, the big beautiful payload.
—msh
Written by

